 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Partial Model Personalization
Apr 08, 2022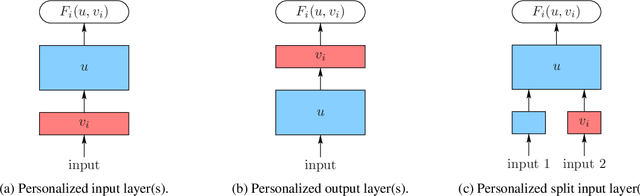

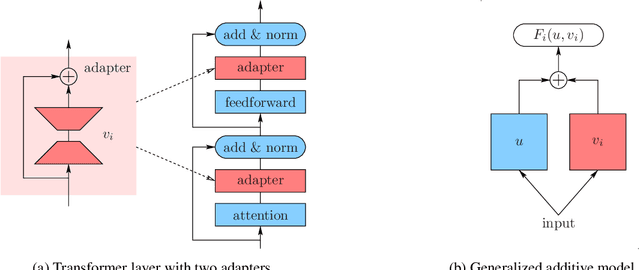

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
Generative Spoken Dialogue Language Modeling
Mar 30, 2022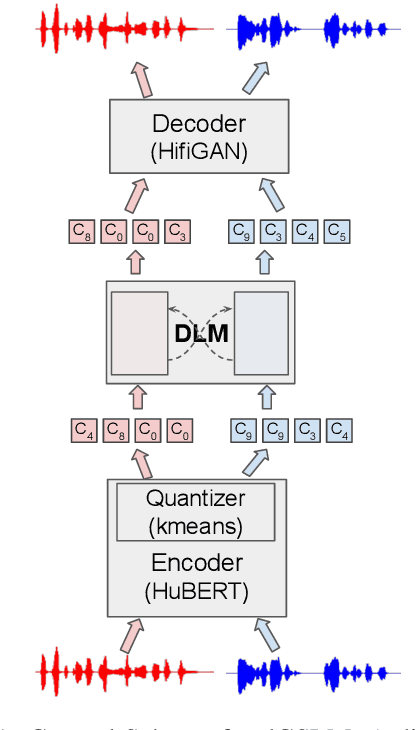
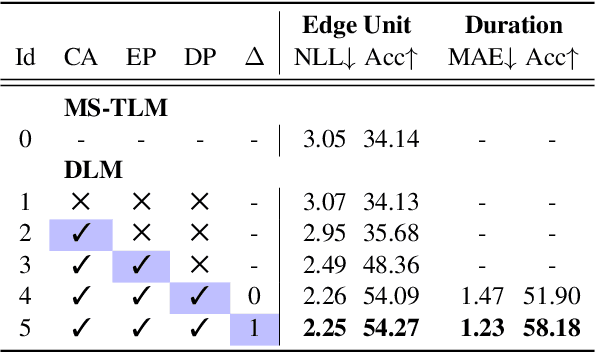
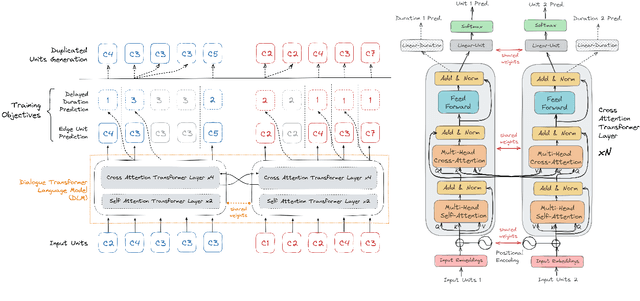
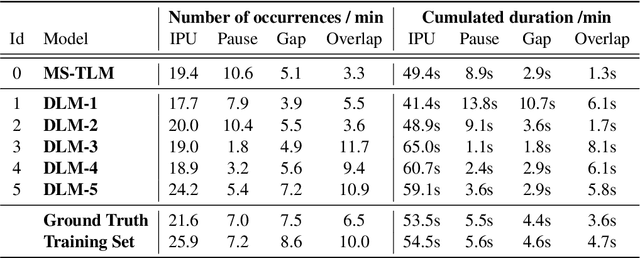
We introduce dGSLM, the first "textless" model able to generate audio samples of naturalistic spoken dialogues. It uses recent work on unsupervised spoken unit discovery coupled with a dual-tower transformer architecture with cross-attention trained on 2000 hours of two-channel raw conversational audio (Fisher dataset) without any text or labels. It is able to generate speech, laughter and other paralinguistic signals in the two channels simultaneously and reproduces naturalistic turn taking. Generation samples can be found at: https://speechbot.github.io/dgslm.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022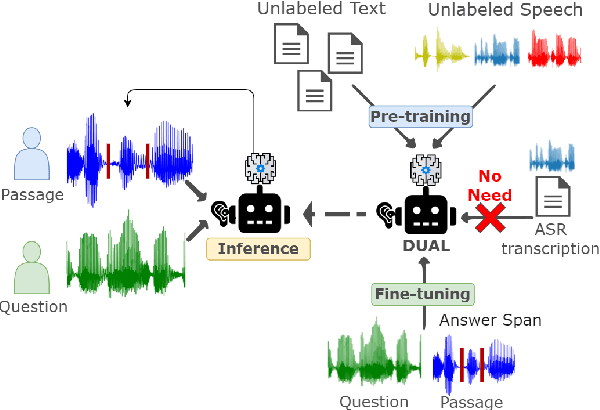
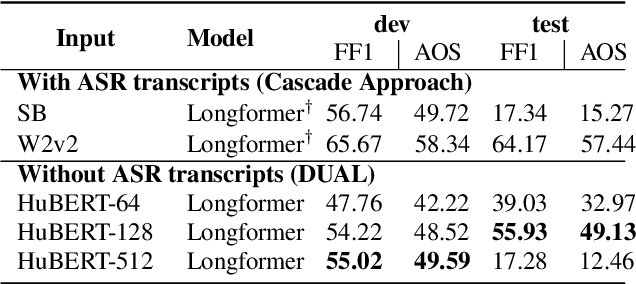
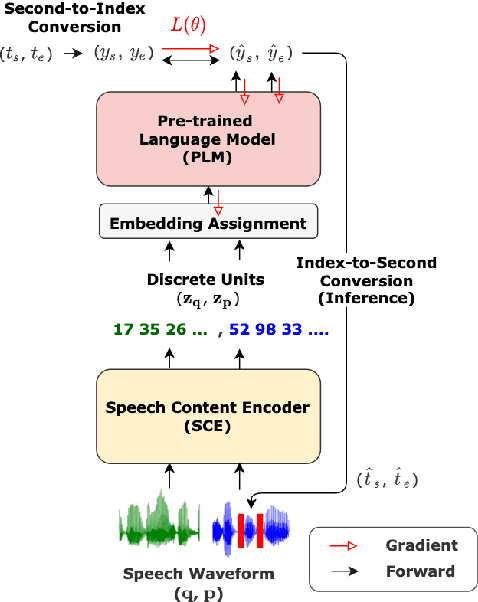
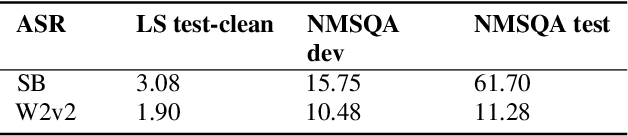
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities
Mar 14, 2022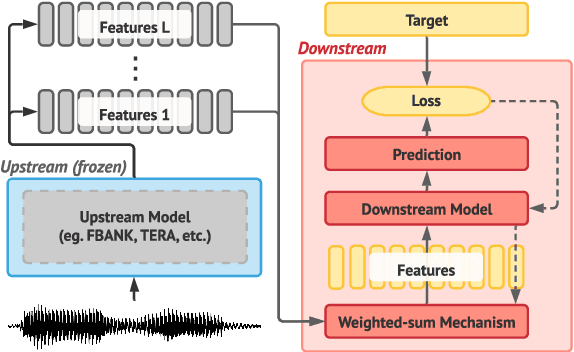
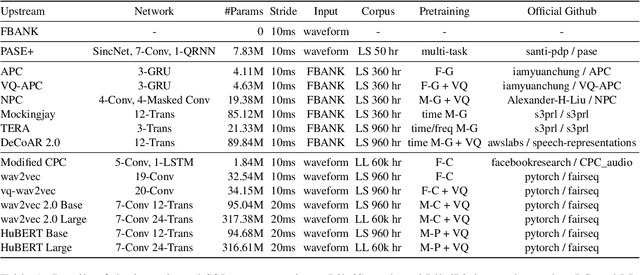
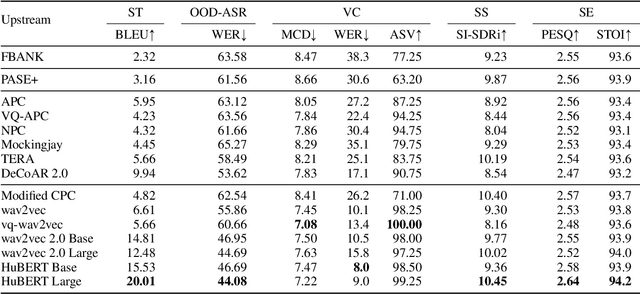
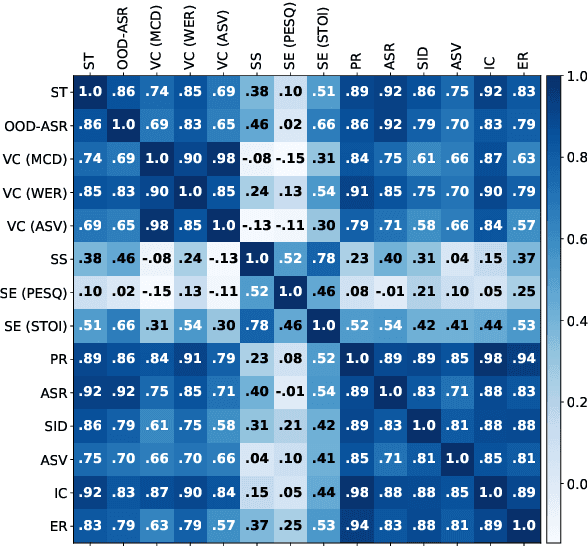
Transfer learning has proven to be crucial in advancing the state of speech and natural language processing research in recent years. In speech, a model pre-trained by self-supervised learning transfers remarkably well on multiple tasks. However, the lack of a consistent evaluation methodology is limiting towards a holistic understanding of the efficacy of such models. SUPERB was a step towards introducing a common benchmark to evaluate pre-trained models across various speech tasks. In this paper, we introduce SUPERB-SG, a new benchmark focused on evaluating the semantic and generative capabilities of pre-trained models by increasing task diversity and difficulty over SUPERB. We use a lightweight methodology to test the robustness of representations learned by pre-trained models under shifts in data domain and quality across different types of tasks. It entails freezing pre-trained model parameters, only using simple task-specific trainable heads. The goal is to be inclusive of all researchers, and encourage efficient use of computational resources. We also show that the task diversity of SUPERB-SG coupled with limited task supervision is an effective recipe for evaluating the generalizability of model representation.
textless-lib: a Library for Textless Spoken Language Processing
Feb 15, 2022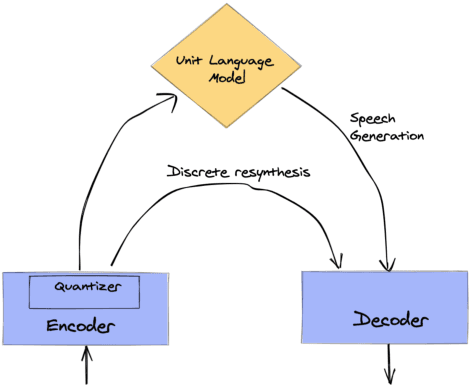
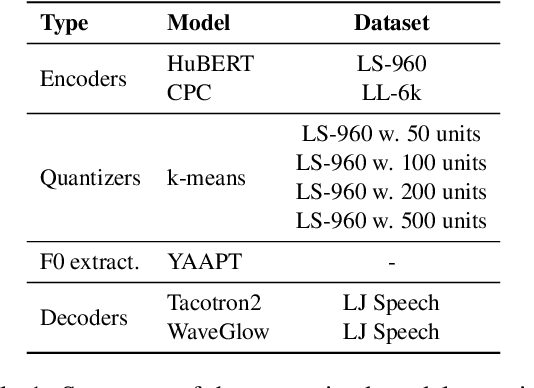
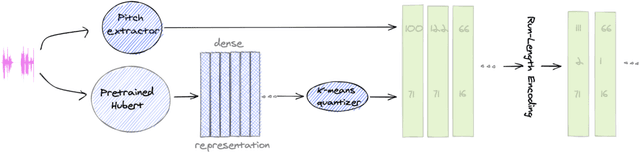
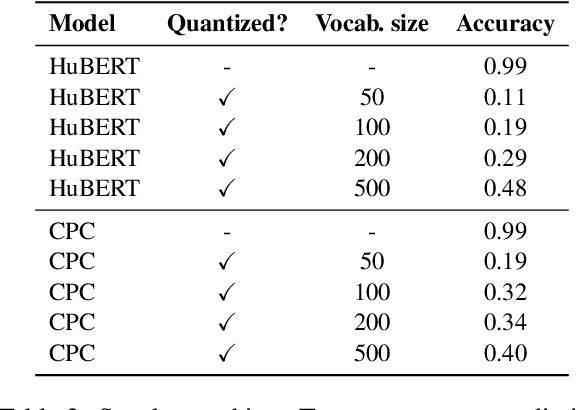
Textless spoken language processing research aims to extend the applicability of standard NLP toolset onto spoken language and languages with few or no textual resources. In this paper, we introduce textless-lib, a PyTorch-based library aimed to facilitate research in this research area. We describe the building blocks that the library provides and demonstrate its usability by discuss three different use-case examples: (i) speaker probing, (ii) speech resynthesis and compression, and (iii) speech continuation. We believe that textless-lib substantially simplifies research the textless setting and will be handful not only for speech researchers but also for the NLP community at large. The code, documentation, and pre-trained models are available at https://github.com/facebookresearch/textlesslib/ .
Object Detection in Aerial Images: What Improves the Accuracy?
Jan 21, 2022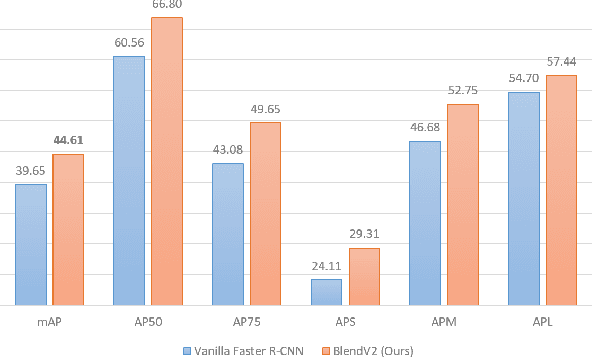
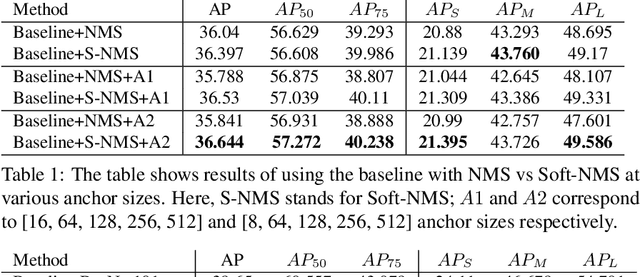
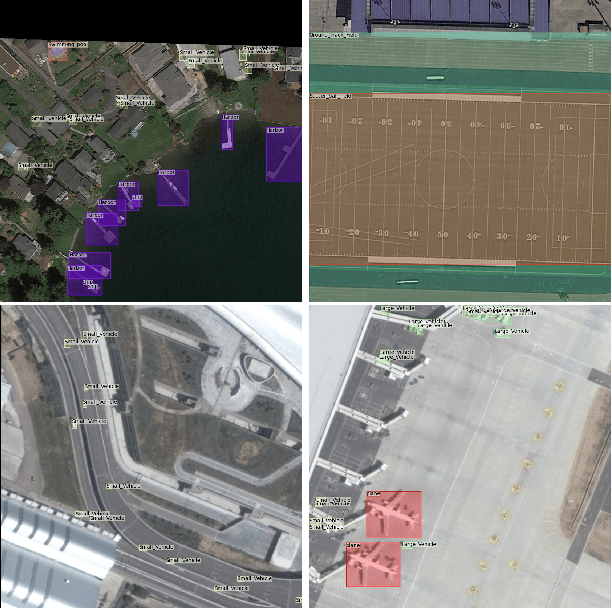
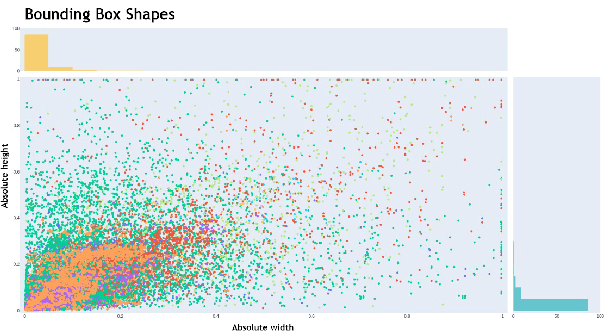
Object detection is a challenging and popular computer vision problem. The problem is even more challenging in aerial images due to significant variation in scale and viewpoint in a diverse set of object categories. Recently, deep learning-based object detection approaches have been actively explored for the problem of object detection in aerial images. In this work, we investigate the impact of Faster R-CNN for aerial object detection and explore numerous strategies to improve its performance for aerial images. We conduct extensive experiments on the challenging iSAID dataset. The resulting adapted Faster R-CNN obtains a significant mAP gain of 4.96% over its vanilla baseline counterpart on the iSAID validation set, demonstrating the impact of different strategies investigated in this work.
Robust Self-Supervised Audio-Visual Speech Recognition
Jan 05, 2022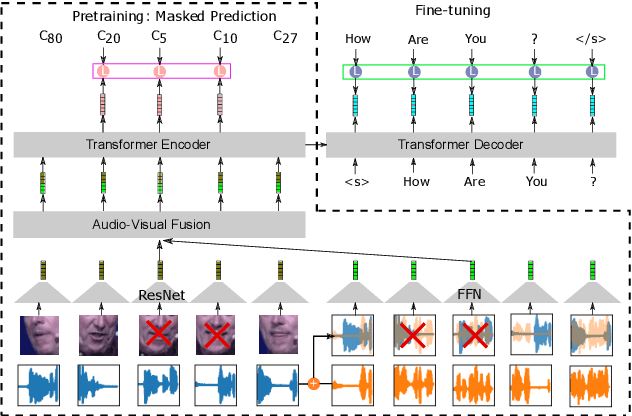

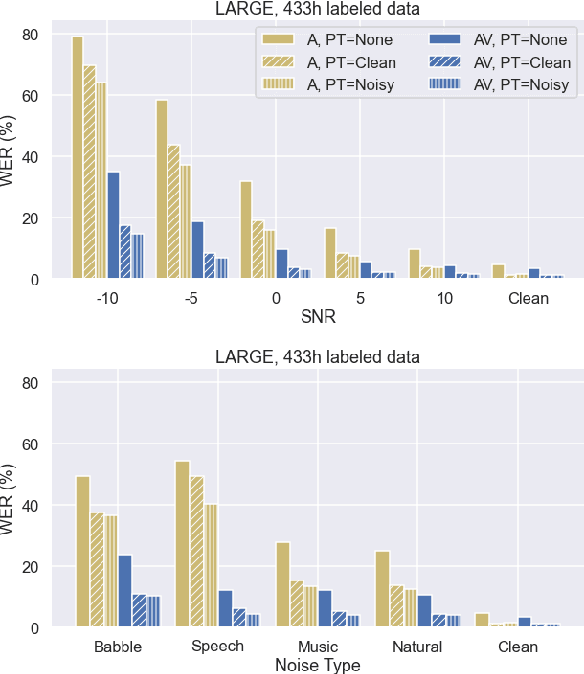
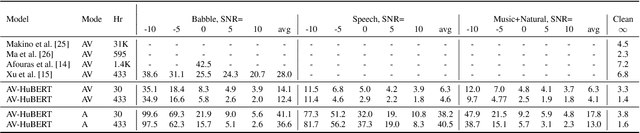
Audio-based automatic speech recognition (ASR) degrades significantly in noisy environments and is particularly vulnerable to interfering speech, as the model cannot determine which speaker to transcribe. Audio-visual speech recognition (AVSR) systems improve robustness by complementing the audio stream with the visual information that is invariant to noise and helps the model focus on the desired speaker. However, previous AVSR work focused solely on the supervised learning setup; hence the progress was hindered by the amount of labeled data available. In this work, we present a self-supervised AVSR framework built upon Audio-Visual HuBERT (AV-HuBERT), a state-of-the-art audio-visual speech representation learning model. On the largest available AVSR benchmark dataset LRS3, our approach outperforms prior state-of-the-art by ~50% (28.0% vs. 14.1%) using less than 10% of labeled data (433hr vs. 30hr) in the presence of babble noise, while reducing the WER of an audio-based model by over 75% (25.8% vs. 5.8%) on average.
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
Jan 05, 2022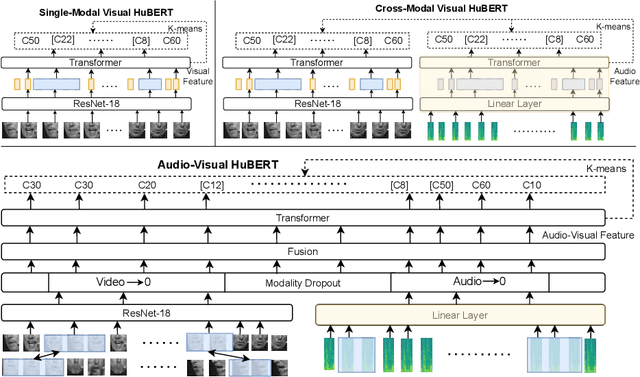
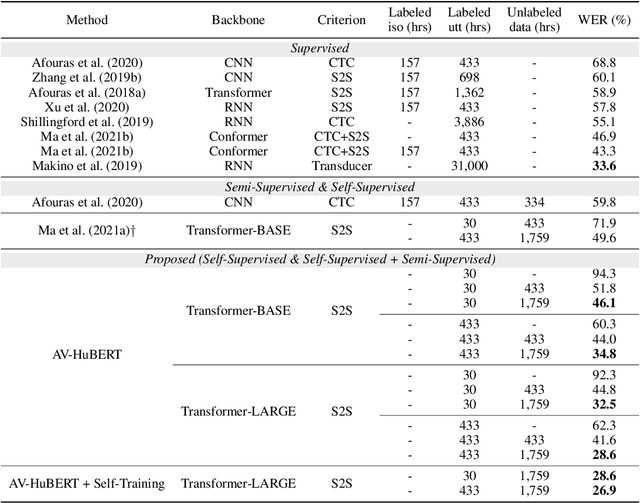


Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker's lip movements and the produced sound. We introduce Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition. On the largest public lip-reading benchmark LRS3 (433 hours), AV-HuBERT achieves 32.5% WER with only 30 hours of labeled data, outperforming the former state-of-the-art approach (33.6%) trained with a thousand times more transcribed video data (31K hours). The lip-reading WER is further reduced to 26.9% when using all 433 hours of labeled data from LRS3 and combined with self-training. Using our audio-visual representation on the same benchmark for audio-only speech recognition leads to a 40% relative WER reduction over the state-of-the-art performance (1.3% vs 2.3%). Our code and models are available at https://github.com/facebookresearch/av_hubert
Scaling ASR Improves Zero and Few Shot Learning
Nov 29, 2021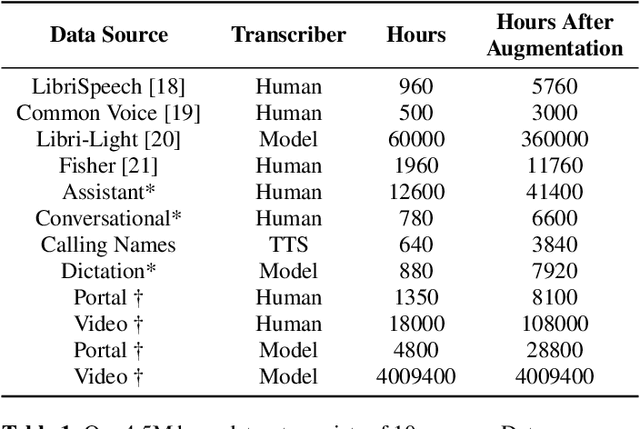
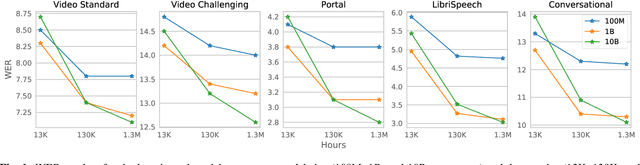
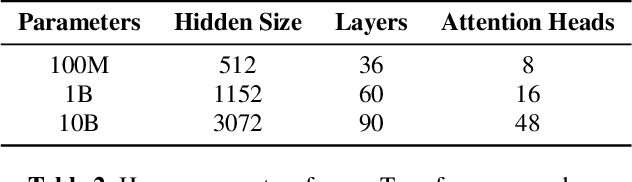
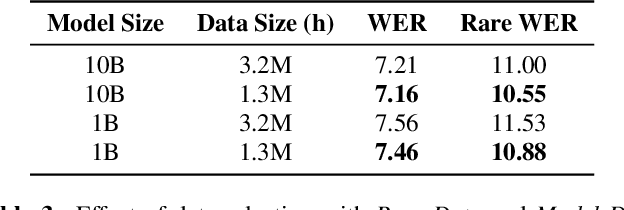
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.
Textless Speech Emotion Conversion using Decomposed and Discrete Representations
Nov 14, 2021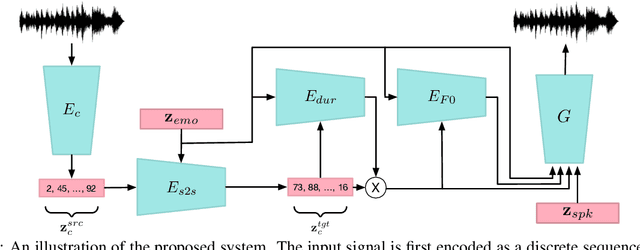
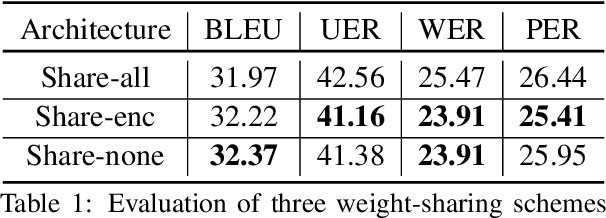
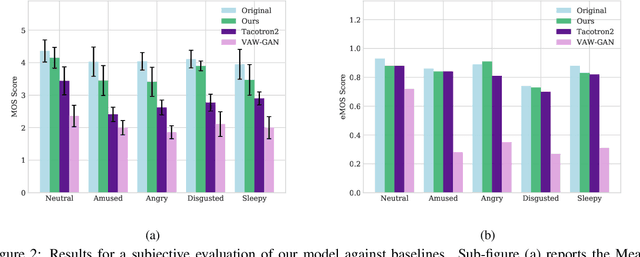
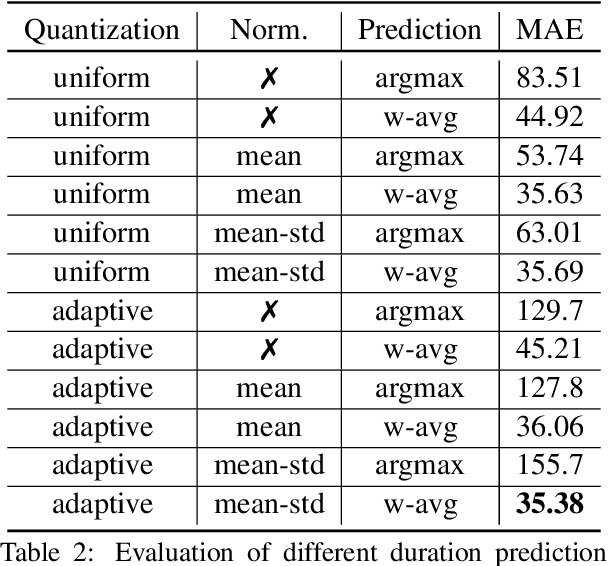
Speech emotion conversion is the task of modifying the perceived emotion of a speech utterance while preserving the lexical content and speaker identity. In this study, we cast the problem of emotion conversion as a spoken language translation task. We decompose speech into discrete and disentangled learned representations, consisting of content units, F0, speaker, and emotion. First, we modify the speech content by translating the content units to a target emotion, and then predict the prosodic features based on these units. Finally, the speech waveform is generated by feeding the predicted representations into a neural vocoder. Such a paradigm allows us to go beyond spectral and parametric changes of the signal, and model non-verbal vocalizations, such as laughter insertion, yawning removal, etc. We demonstrate objectively and subjectively that the proposed method is superior to the baselines in terms of perceived emotion and audio quality. We rigorously evaluate all components of such a complex system and conclude with an extensive model analysis and ablation study to better emphasize the architectural choices, strengths and weaknesses of the proposed method. Samples and code will be publicly available under the following link: https://speechbot.github.io/emotion.