 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Batch Normalization
Feb 28, 2017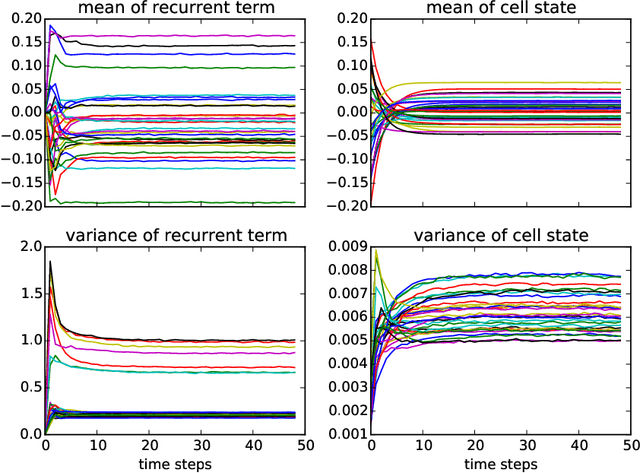
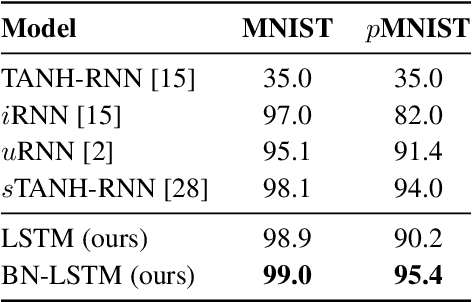
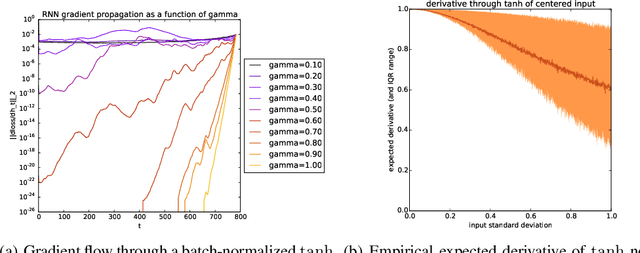
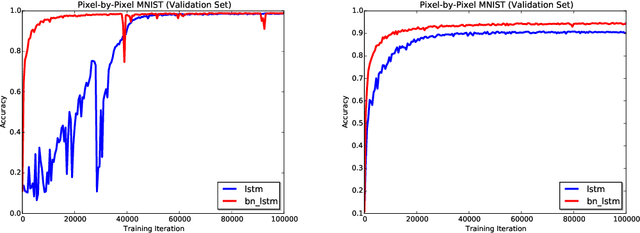
We propose a reparameterization of LSTM that brings the benefits of batch normalization to recurrent neural networks. Whereas previous works only apply batch normalization to the input-to-hidden transformation of RNNs, we demonstrate that it is both possible and beneficial to batch-normalize the hidden-to-hidden transition, thereby reducing internal covariate shift between time steps. We evaluate our proposal on various sequential problems such as sequence classification, language modeling and question answering. Our empirical results show that our batch-normalized LSTM consistently leads to faster convergence and improved generalization.
Calibrating Energy-based Generative Adversarial Networks
Feb 24, 2017
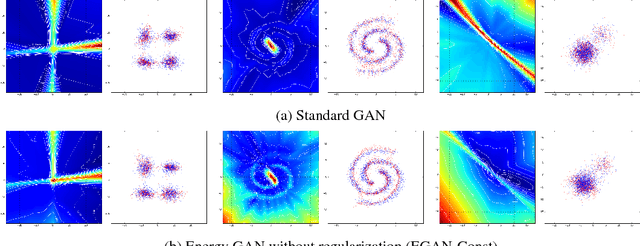
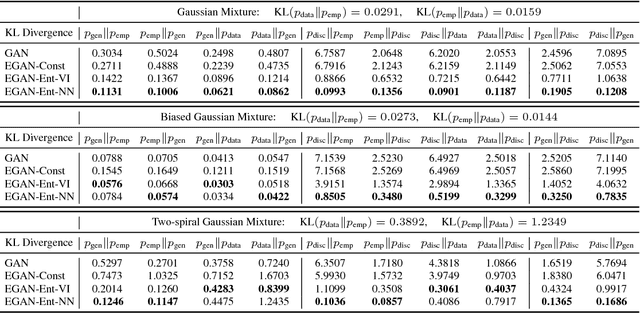
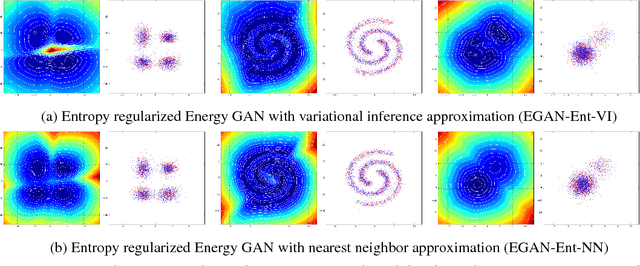
In this paper, we propose to equip Generative Adversarial Networks with the ability to produce direct energy estimates for samples.Specifically, we propose a flexible adversarial training framework, and prove this framework not only ensures the generator converges to the true data distribution, but also enables the discriminator to retain the density information at the global optimal. We derive the analytic form of the induced solution, and analyze the properties. In order to make the proposed framework trainable in practice, we introduce two effective approximation techniques. Empirically, the experiment results closely match our theoretical analysis, verifying the discriminator is able to recover the energy of data distribution.
Adversarially Learned Inference
Feb 21, 2017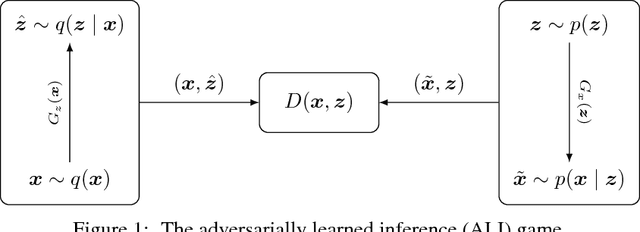
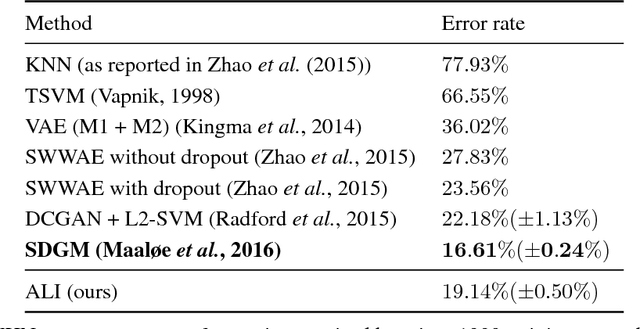

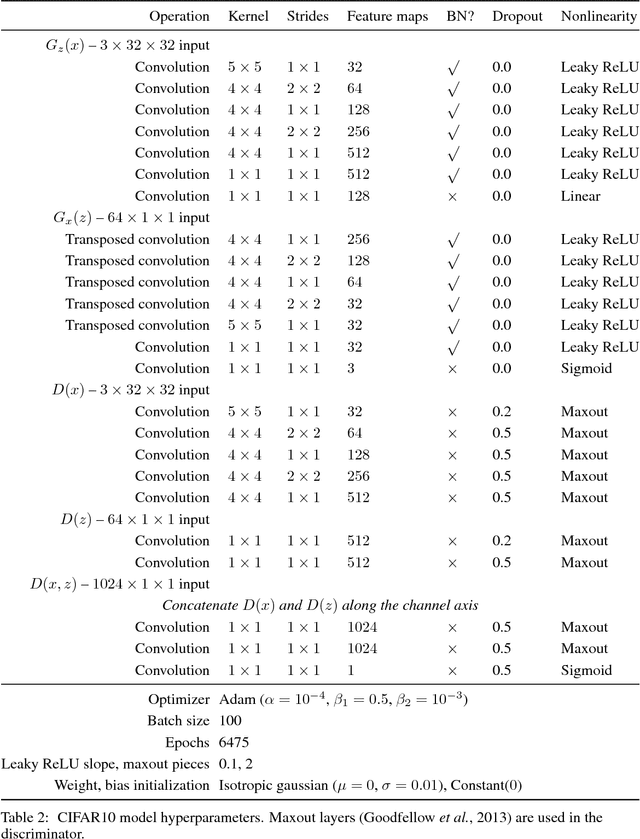
We introduce the adversarially learned inference (ALI) model, which jointly learns a generation network and an inference network using an adversarial process. The generation network maps samples from stochastic latent variables to the data space while the inference network maps training examples in data space to the space of latent variables. An adversarial game is cast between these two networks and a discriminative network is trained to distinguish between joint latent/data-space samples from the generative network and joint samples from the inference network. We illustrate the ability of the model to learn mutually coherent inference and generation networks through the inspections of model samples and reconstructions and confirm the usefulness of the learned representations by obtaining a performance competitive with state-of-the-art on the semi-supervised SVHN and CIFAR10 tasks.
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
Feb 11, 2017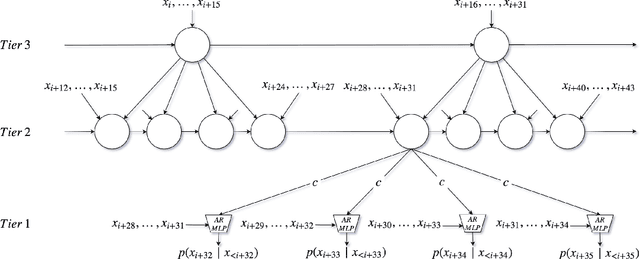

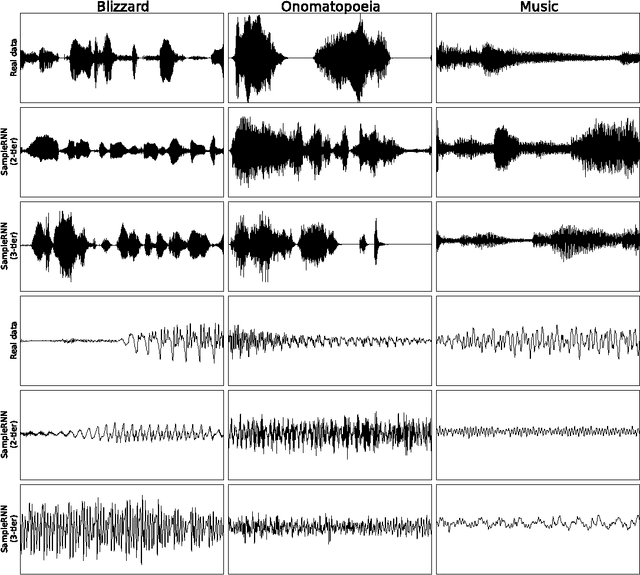
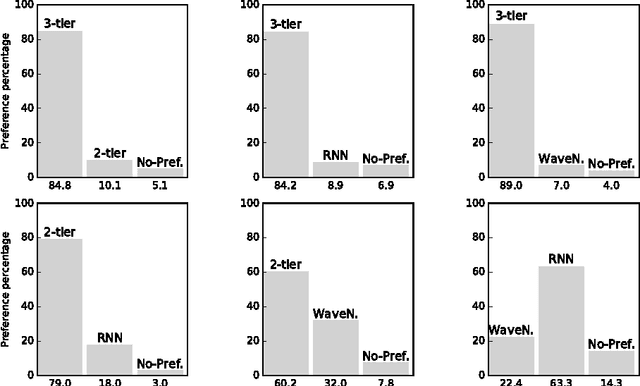
In this paper we propose a novel model for unconditional audio generation based on generating one audio sample at a time. We show that our model, which profits from combining memory-less modules, namely autoregressive multilayer perceptrons, and stateful recurrent neural networks in a hierarchical structure is able to capture underlying sources of variations in the temporal sequences over very long time spans, on three datasets of different nature. Human evaluation on the generated samples indicate that our model is preferred over competing models. We also show how each component of the model contributes to the exhibited performance.
GuessWhat?! Visual object discovery through multi-modal dialogue
Feb 06, 2017
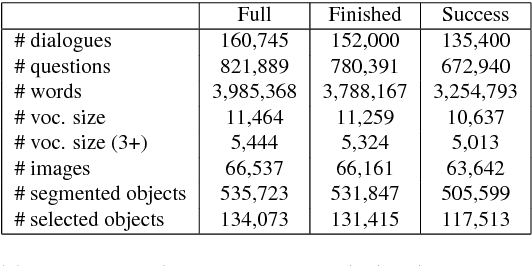

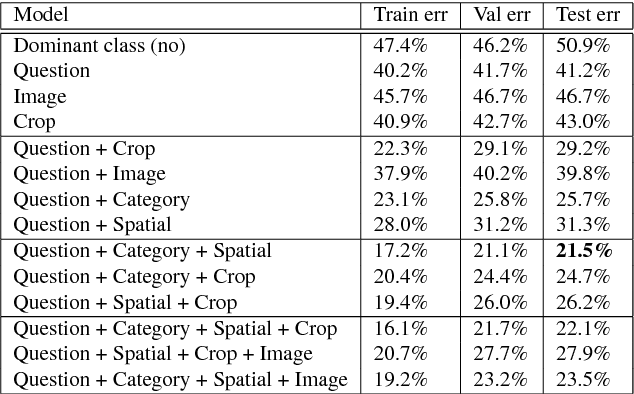
We introduce GuessWhat?!, a two-player guessing game as a testbed for research on the interplay of computer vision and dialogue systems. The goal of the game is to locate an unknown object in a rich image scene by asking a sequence of questions. Higher-level image understanding, like spatial reasoning and language grounding, is required to solve the proposed task. Our key contribution is the collection of a large-scale dataset consisting of 150K human-played games with a total of 800K visual question-answer pairs on 66K images. We explain our design decisions in collecting the dataset and introduce the oracle and questioner tasks that are associated with the two players of the game. We prototyped deep learning models to establish initial baselines of the introduced tasks.
A dataset and exploration of models for understanding video data through fill-in-the-blank question-answering
Feb 05, 2017
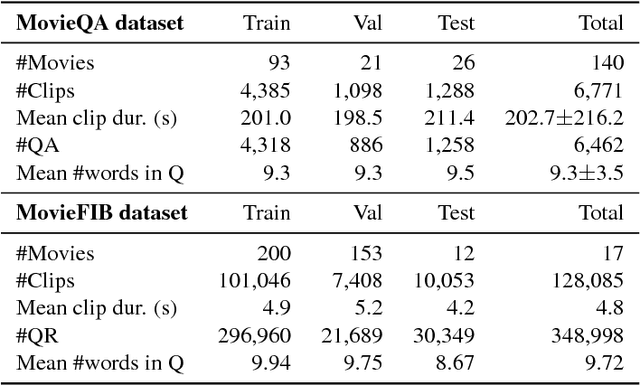
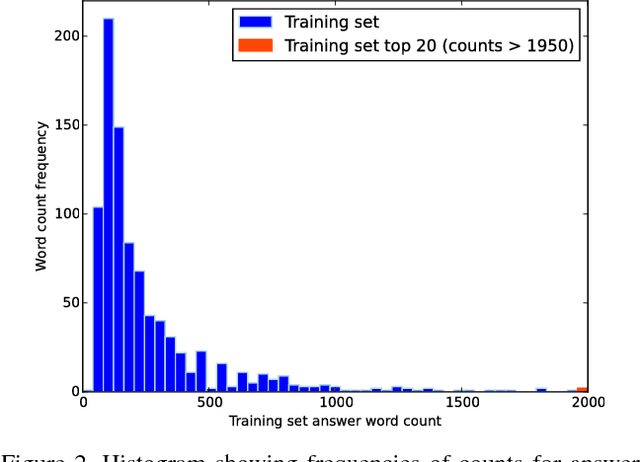
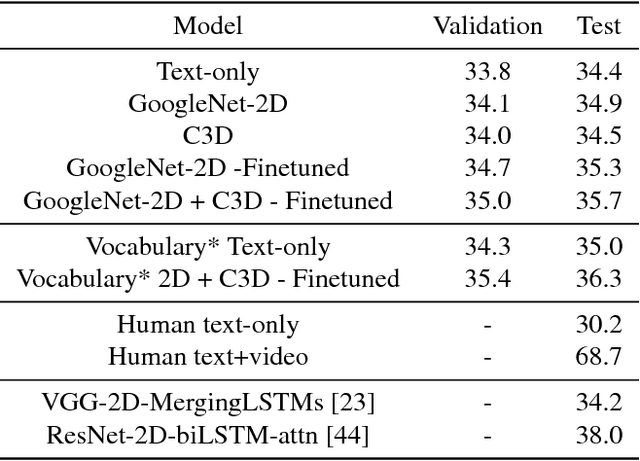
While deep convolutional neural networks frequently approach or exceed human-level performance at benchmark tasks involving static images, extending this success to moving images is not straightforward. Having models which can learn to understand video is of interest for many applications, including content recommendation, prediction, summarization, event/object detection and understanding human visual perception, but many domains lack sufficient data to explore and perfect video models. In order to address the need for a simple, quantitative benchmark for developing and understanding video, we present MovieFIB, a fill-in-the-blank question-answering dataset with over 300,000 examples, based on descriptive video annotations for the visually impaired. In addition to presenting statistics and a description of the dataset, we perform a detailed analysis of 5 different models' predictions, and compare these with human performance. We investigate the relative importance of language, static (2D) visual features, and moving (3D) visual features; the effects of increasing dataset size, the number of frames sampled; and of vocabulary size. We illustrate that: this task is not solvable by a language model alone; our model combining 2D and 3D visual information indeed provides the best result; all models perform significantly worse than human-level. We provide human evaluations for responses given by different models and find that accuracy on the MovieFIB evaluation corresponds well with human judgement. We suggest avenues for improving video models, and hope that the proposed dataset can be useful for measuring and encouraging progress in this very interesting field.
Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks
Jan 10, 2017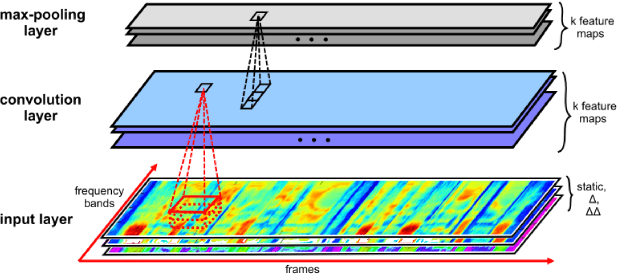
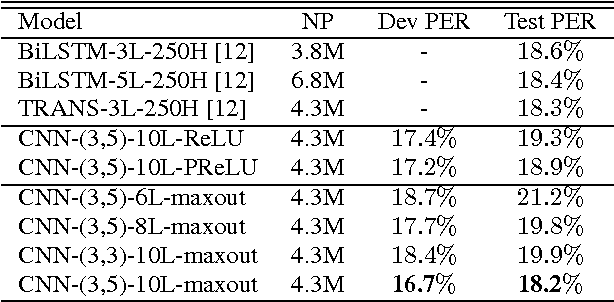
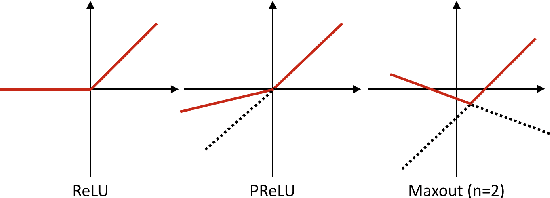
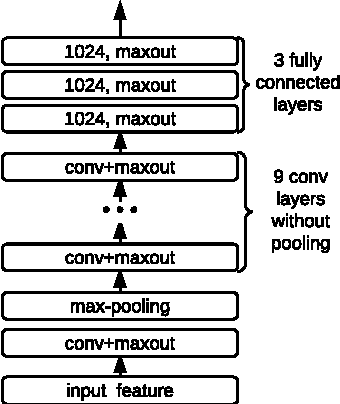
Convolutional Neural Networks (CNNs) are effective models for reducing spectral variations and modeling spectral correlations in acoustic features for automatic speech recognition (ASR). Hybrid speech recognition systems incorporating CNNs with Hidden Markov Models/Gaussian Mixture Models (HMMs/GMMs) have achieved the state-of-the-art in various benchmarks. Meanwhile, Connectionist Temporal Classification (CTC) with Recurrent Neural Networks (RNNs), which is proposed for labeling unsegmented sequences, makes it feasible to train an end-to-end speech recognition system instead of hybrid settings. However, RNNs are computationally expensive and sometimes difficult to train. In this paper, inspired by the advantages of both CNNs and the CTC approach, we propose an end-to-end speech framework for sequence labeling, by combining hierarchical CNNs with CTC directly without recurrent connections. By evaluating the approach on the TIMIT phoneme recognition task, we show that the proposed model is not only computationally efficient, but also competitive with the existing baseline systems. Moreover, we argue that CNNs have the capability to model temporal correlations with appropriate context information.
Generalizable Features From Unsupervised Learning
Dec 12, 2016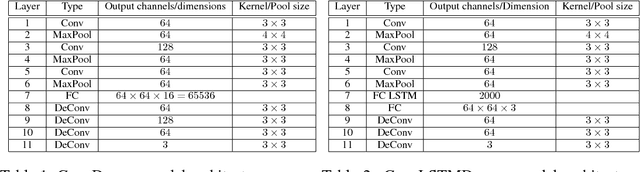


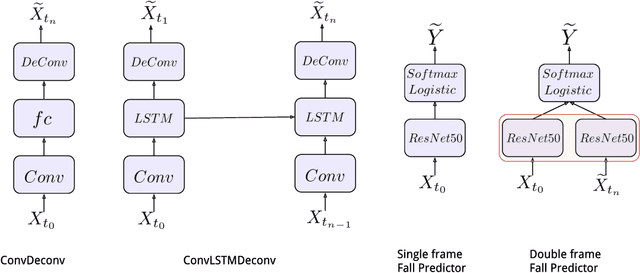
Humans learn a predictive model of the world and use this model to reason about future events and the consequences of actions. In contrast to most machine predictors, we exhibit an impressive ability to generalize to unseen scenarios and reason intelligently in these settings. One important aspect of this ability is physical intuition(Lake et al., 2016). In this work, we explore the potential of unsupervised learning to find features that promote better generalization to settings outside the supervised training distribution. Our task is predicting the stability of towers of square blocks. We demonstrate that an unsupervised model, trained to predict future frames of a video sequence of stable and unstable block configurations, can yield features that support extrapolating stability prediction to blocks configurations outside the training set distribution
A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images
Dec 02, 2016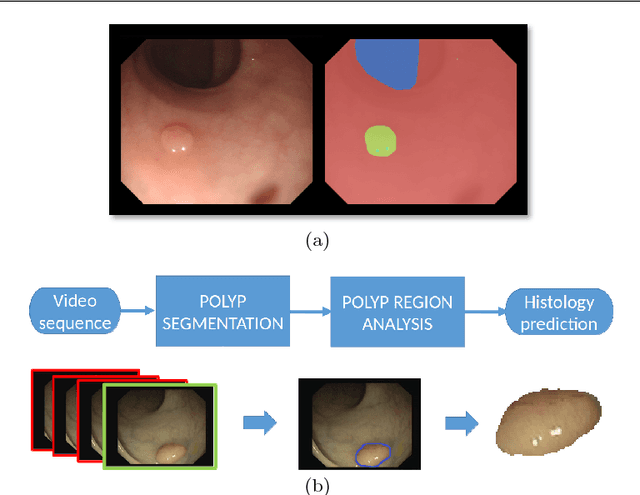
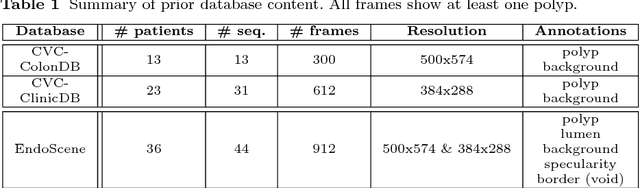

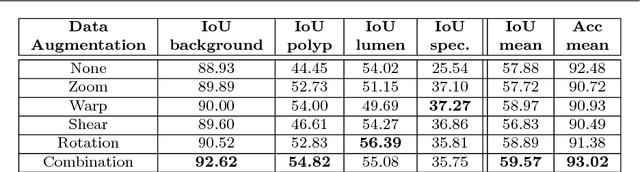
Colorectal cancer (CRC) is the third cause of cancer death worldwide. Currently, the standard approach to reduce CRC-related mortality is to perform regular screening in search for polyps and colonoscopy is the screening tool of choice. The main limitations of this screening procedure are polyp miss-rate and inability to perform visual assessment of polyp malignancy. These drawbacks can be reduced by designing Decision Support Systems (DSS) aiming to help clinicians in the different stages of the procedure by providing endoluminal scene segmentation. Thus, in this paper, we introduce an extended benchmark of colonoscopy image, with the hope of establishing a new strong benchmark for colonoscopy image analysis research. We provide new baselines on this dataset by training standard fully convolutional networks (FCN) for semantic segmentation and significantly outperforming, without any further post-processing, prior results in endoluminal scene segmentation.
PixelVAE: A Latent Variable Model for Natural Images
Nov 15, 2016
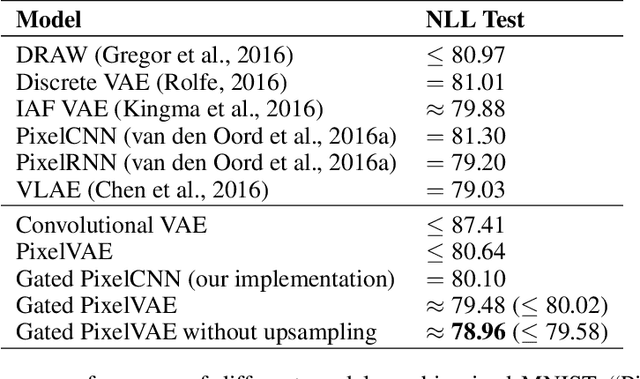


Natural image modeling is a landmark challenge of unsupervised learning. Variational Autoencoders (VAEs) learn a useful latent representation and model global structure well but have difficulty capturing small details. PixelCNN models details very well, but lacks a latent code and is difficult to scale for capturing large structures. We present PixelVAE, a VAE model with an autoregressive decoder based on PixelCNN. Our model requires very few expensive autoregressive layers compared to PixelCNN and learns latent codes that are more compressed than a standard VAE while still capturing most non-trivial structure. Finally, we extend our model to a hierarchy of latent variables at different scales. Our model achieves state-of-the-art performance on binarized MNIST, competitive performance on 64x64 ImageNet, and high-quality samples on the LSUN bedrooms dataset.