 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SpeechYOLO: Detection and Localization of Speech Objects
Apr 14, 2019
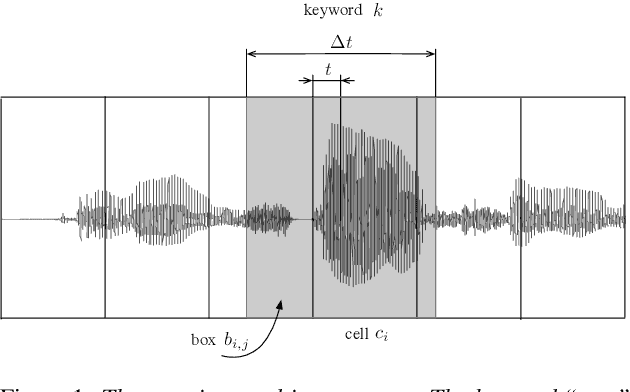
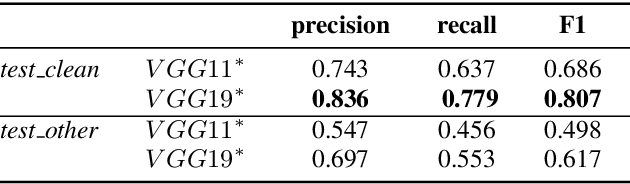
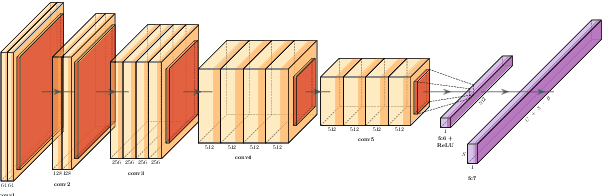
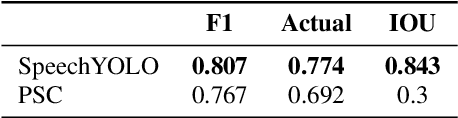
In this paper, we propose to apply object detection methods from the vision domain on the speech recognition domain, by treating audio fragments as objects. More specifically, we present SpeechYOLO, which is inspired by the YOLO algorithm for object detection in images. The goal of SpeechYOLO is to localize boundaries of utterances within the input signal, and to correctly classify them. Our system is composed of a convolutional neural network, with a simple least-mean-squares loss function. We evaluated the system on several keyword spotting tasks, that include corpora of read speech and spontaneous speech. Our system compares favorably with other algorithms trained for both localization and classification.
PSO-Convolutional Neural Networks with Heterogeneous Learning Rate
May 20, 2022
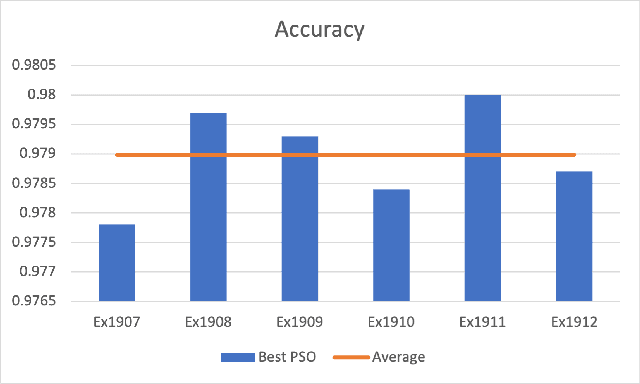
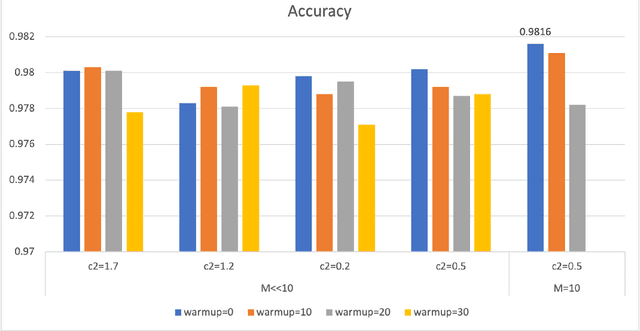
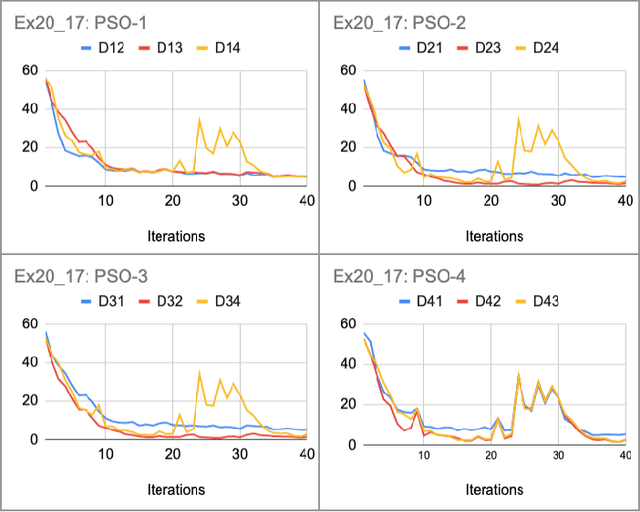
Convolutional Neural Networks (ConvNets) have been candidly deployed in the scope of computer vision and related fields. Nevertheless, the dynamics of training of these neural networks lie still elusive: it is hard and computationally expensive to train them. A myriad of architectures and training strategies have been proposed to overcome this challenge and address several problems in image processing such as speech, image and action recognition as well as object detection. In this article, we propose a novel Particle Swarm Optimization (PSO) based training for ConvNets. In such framework, the vector of weights of each ConvNet is typically cast as the position of a particle in phase space whereby PSO collaborative dynamics intertwines with Stochastic Gradient Descent (SGD) in order to boost training performance and generalization. Our approach goes as follows: i) [warm-up phase] each ConvNet is trained independently via SGD; ii) [collaborative phase] ConvNets share among themselves their current vector of weights (or particle-position) along with their gradient estimates of the Loss function. Distinct step sizes are coined by distinct ConvNets. By properly blending ConvNets with large (possibly random) step-sizes along with more conservative ones, we propose an algorithm with competitive performance with respect to other PSO-based approaches on Cifar-10 (accuracy of 98.31%). These accuracy levels are obtained by resorting to only four ConvNets -- such results are expected to scale with the number of collaborative ConvNets accordingly. We make our source codes available for download https://github.com/leonlha/PSO-ConvNet-Dynamics.
Complex Cepstrum-based Decomposition of Speech for Glottal Source Estimation
Dec 29, 2019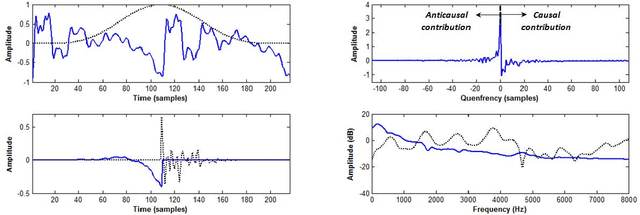
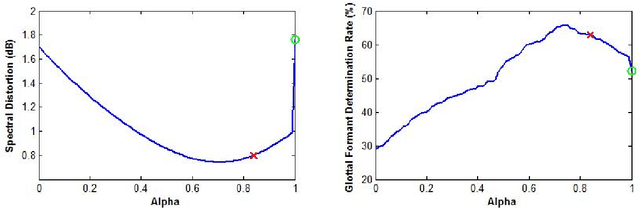
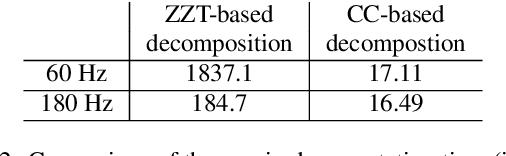
Homomorphic analysis is a well-known method for the separation of non-linearly combined signals. More particularly, the use of complex cepstrum for source-tract deconvolution has been discussed in various articles. However there exists no study which proposes a glottal flow estimation methodology based on cepstrum and reports effective results. In this paper, we show that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of a windowed speech signal as done by the Zeros of the Z-Transform (ZZT) decomposition. Based on exactly the same principles presented for ZZT decomposition, windowing should be applied such that the windowed speech signals exhibit mixed-phase characteristics which conform the speech production model that the anticausal component is mainly due to the glottal flow open phase. The advantage of the complex cepstrum-based approach compared to the ZZT decomposition is its much higher speed.
Emotion Intensity and its Control for Emotional Voice Conversion
Jan 10, 2022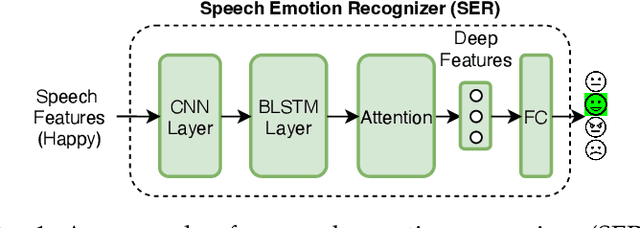

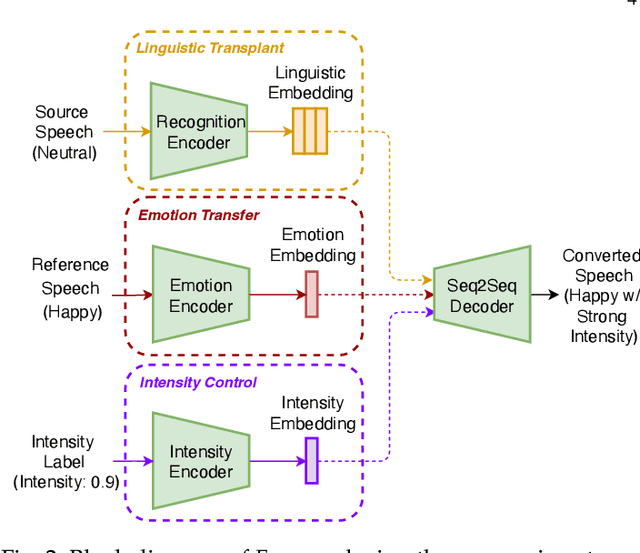

Emotional voice conversion (EVC) seeks to convert the emotional state of an utterance while preserving the linguistic content and speaker identity. In EVC, emotions are usually treated as discrete categories overlooking the fact that speech also conveys emotions with various intensity levels that the listener can perceive. In this paper, we aim to explicitly characterize and control the intensity of emotion. We propose to disentangle the speaker style from linguistic content and encode the speaker style into a style embedding in a continuous space that forms the prototype of emotion embedding. We further learn the actual emotion encoder from an emotion-labelled database and study the use of relative attributes to represent fine-grained emotion intensity. To ensure emotional intelligibility, we incorporate emotion classification loss and emotion embedding similarity loss into the training of the EVC network. As desired, the proposed network controls the fine-grained emotion intensity in the output speech. Through both objective and subjective evaluations, we validate the effectiveness of the proposed network for emotional expressiveness and emotion intensity control.
The Vicomtech Spoofing-Aware Biometric System for the SASV Challenge
Apr 04, 2022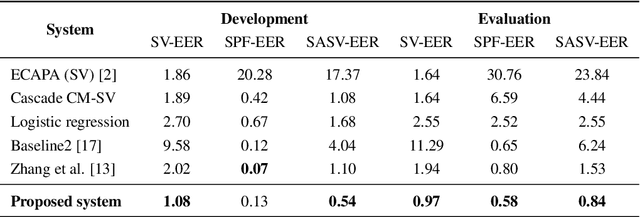
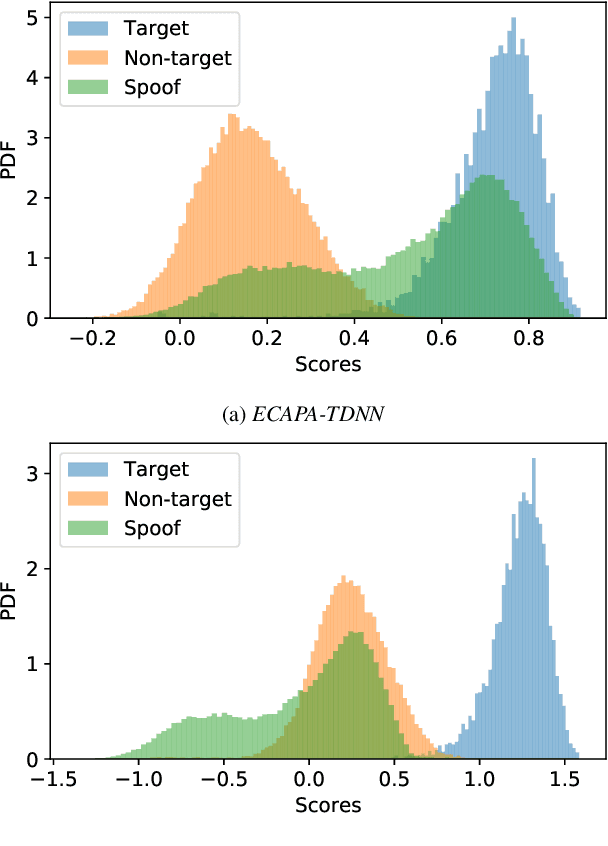
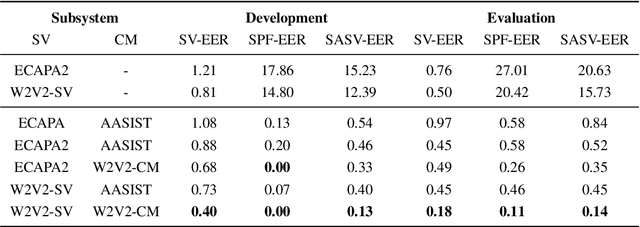
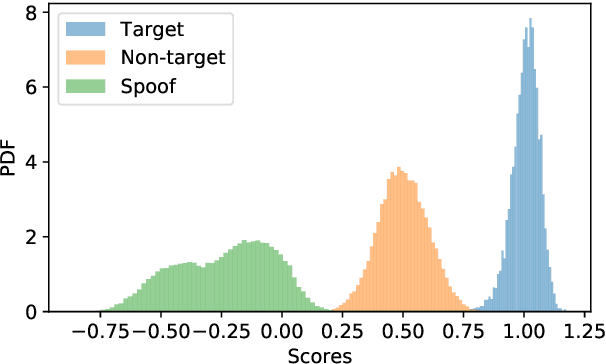
This paper describes our proposed integration system for the spoofing-aware speaker verification challenge. It consists of a robust spoofing-aware verification system that use the speaker verification and antispoofing embeddings extracted from specialized neural networks. First, an integration network, fed with the test utterance's speaker verification and spoofing embeddings, is used to compute a spoof-based score. This score is then linearly combined with the cosine similarity between the speaker verification embeddings from the enrollment and test utterances, thus obtaining the final scoring decision. Moreover, the integration network is trained using a one-class loss function to discriminate between target trials and unauthorized accesses. Our proposed system is evaluated in the ASVspoof19 database, exhibiting competitive performance compared to other integration approaches. In addition, we test, along with our integration approach, state of the art speaker verification and antispoofing systems based on self-supervised learning, yielding high-performance speech biometric systems.
A Comparative Study on Transformer vs RNN in Speech Applications
Sep 28, 2019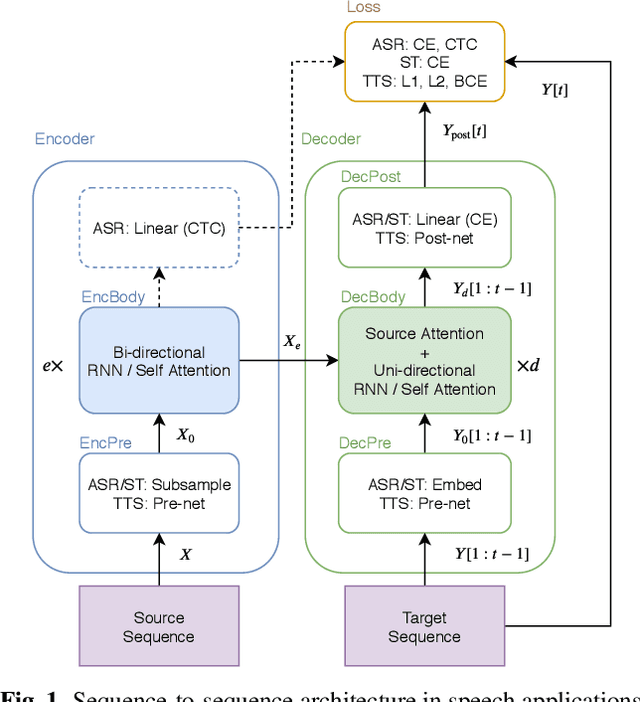
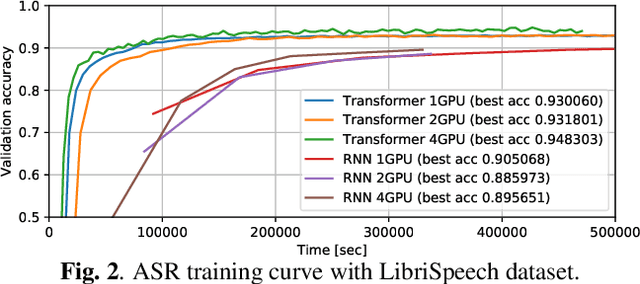
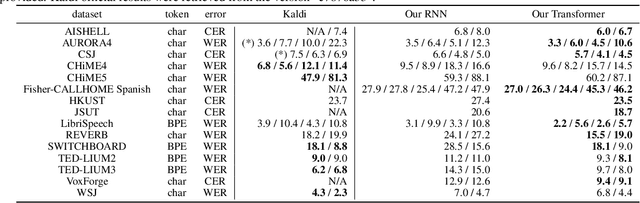
Sequence-to-sequence models have been widely used in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). This paper focuses on an emergent sequence-to-sequence model called Transformer, which achieves state-of-the-art performance in neural machine translation and other natural language processing applications. We undertook intensive studies in which we experimentally compared and analyzed Transformer and conventional recurrent neural networks (RNN) in a total of 15 ASR, one multilingual ASR, one ST, and two TTS benchmarks. Our experiments revealed various training tips and significant performance benefits obtained with Transformer for each task including the surprising superiority of Transformer in 13/15 ASR benchmarks in comparison with RNN. We are preparing to release Kaldi-style reproducible recipes using open source and publicly available datasets for all the ASR, ST, and TTS tasks for the community to succeed our exciting outcomes.
* Accepted at ASRU 2019
Shallow Fusion of Weighted Finite-State Transducer and Language Model for Text Normalization
Mar 29, 2022
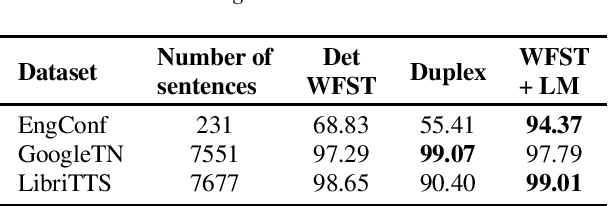
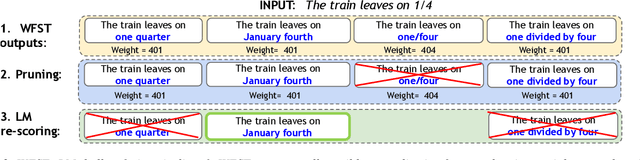

Text normalization (TN) systems in production are largely rule-based using weighted finite-state transducers (WFST). However, WFST-based systems struggle with ambiguous input when the normalized form is context-dependent. On the other hand, neural text normalization systems can take context into account but they suffer from unrecoverable errors and require labeled normalization datasets, which are hard to collect. We propose a new hybrid approach that combines the benefits of rule-based and neural systems. First, a non-deterministic WFST outputs all normalization candidates, and then a neural language model picks the best one -- similar to shallow fusion for automatic speech recognition. While the WFST prevents unrecoverable errors, the language model resolves contextual ambiguity. The approach is easy to extend and we show it is effective. It achieves comparable or better results than existing state-of-the-art TN models.
tPLCnet: Real-time Deep Packet Loss Concealment in the Time Domain Using a Short Temporal Context
Apr 04, 2022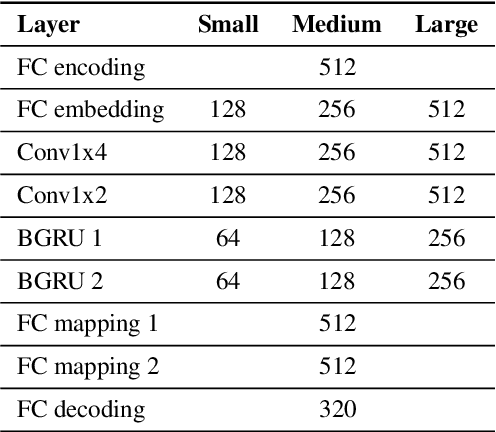
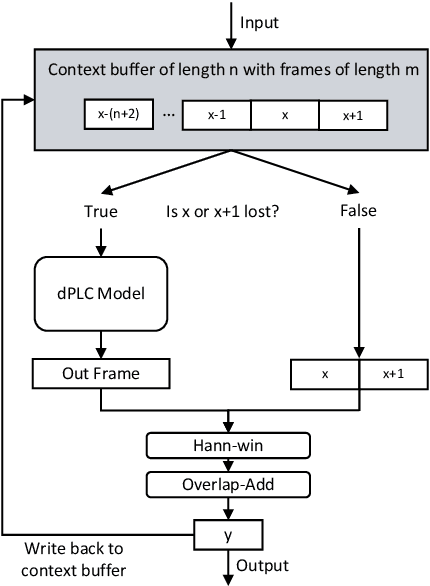
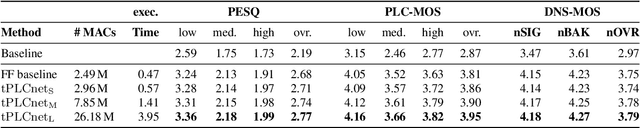
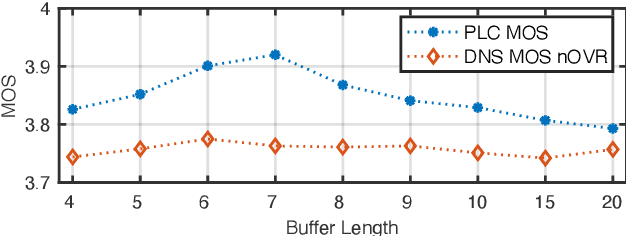
This paper introduces a real-time time-domain packet loss concealment (PLC) neural-network (tPLCnet). It efficiently predicts lost frames from a short context buffer in a sequence-to-one (seq2one) fashion. Because of its seq2one structure, a continuous inference of the model is not required since it can be triggered when packet loss is actually detected. It is trained on 64h of open-source speech data and packet-loss traces of real calls provided by the Audio PLC Challenge. The model with the lowest complexity described in this paper reaches a robust PLC performance and consistent improvements over the zero-filling baseline for all metrics. A configuration with higher complexity is submitted to the PLC Challenge and shows a performance increase of 1.07 compared to the zero-filling baseline in terms of PLC-MOS on the blind test set and reaches a competitive 3rd place in the challenge ranking.
Low-Latency Sequence-to-Sequence Speech Recognition and Translation by Partial Hypothesis Selection
May 22, 2020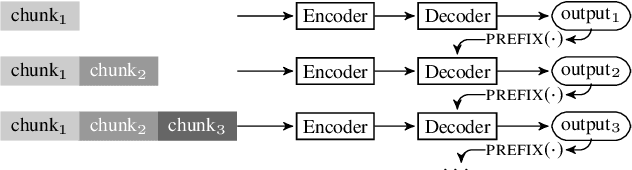
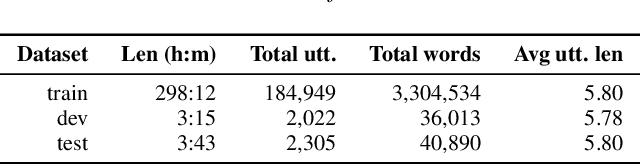
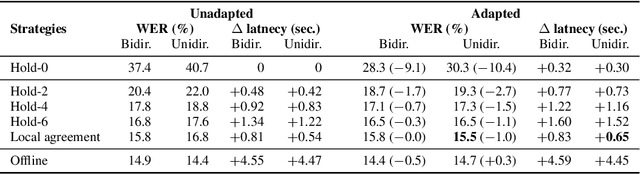
Encoder-decoder models provide a generic architecture for sequence-to-sequence tasks such as speech recognition and translation. While offline systems are often evaluated on quality metrics like word error rates (WER) and BLEU, latency is also a crucial factor in many practical use-cases. We propose three latency reduction techniques for chunk-based incremental inference and evaluate their efficiency in terms of accuracy-latency trade-off. On the 300-hour How2 dataset, we reduce latency by 83% to 0.8 second by sacrificing 1% WER (6% rel.) compared to offline transcription. Although our experiments use the Transformer, the hypothesis selection strategies are applicable to other encoder-decoder models. To avoid expensive re-computation, we use a unidirectionally-attending encoder. After an adaptation procedure to partial sequences, the unidirectional model performs on-par with the original model. We further show that our approach is also applicable to low-latency speech translation. On How2 English-Portuguese speech translation, we reduce latency to 0.7 second (-84% rel.) while incurring a loss of 2.4 BLEU points (5% rel.) compared to the offline system.
Speech Prediction in Silent Videos using Variational Autoencoders
Nov 14, 2020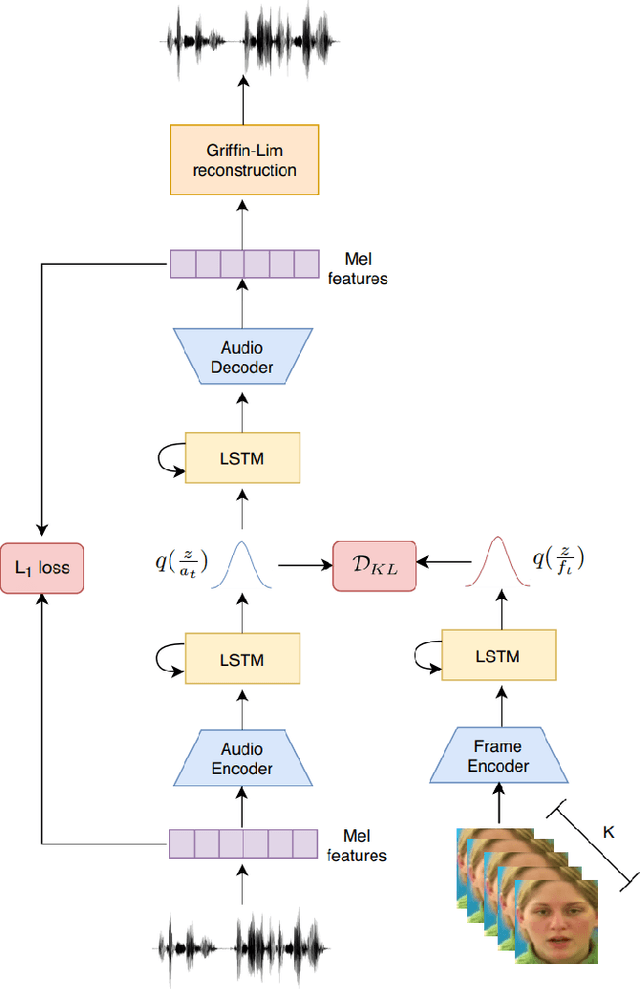
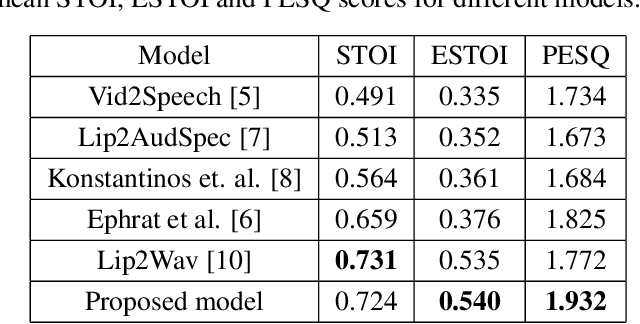
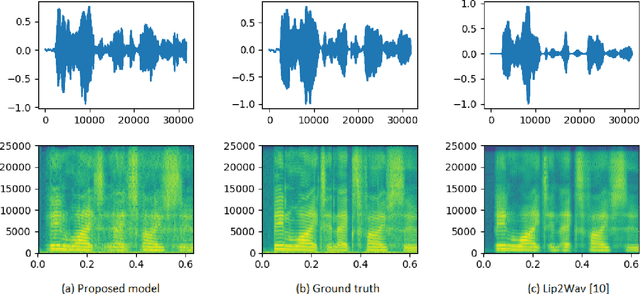
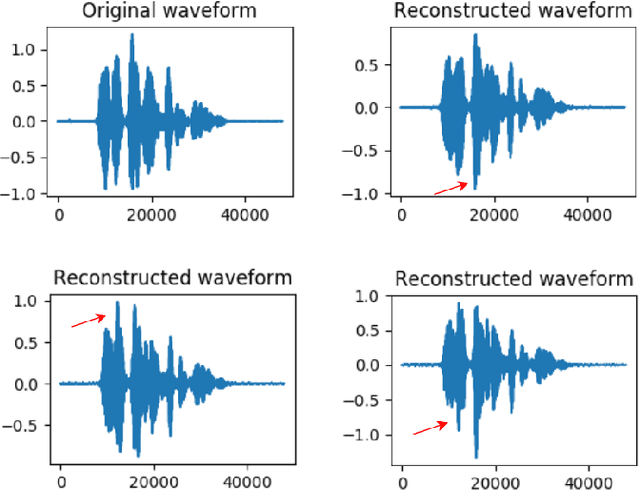
Understanding the relationship between the auditory and visual signals is crucial for many different applications ranging from computer-generated imagery (CGI) and video editing automation to assisting people with hearing or visual impairments. However, this is challenging since the distribution of both audio and visual modality is inherently multimodal. Therefore, most of the existing methods ignore the multimodal aspect and assume that there only exists a deterministic one-to-one mapping between the two modalities. It can lead to low-quality predictions as the model collapses to optimizing the average behavior rather than learning the full data distributions. In this paper, we present a stochastic model for generating speech in a silent video. The proposed model combines recurrent neural networks and variational deep generative models to learn the auditory signal's conditional distribution given the visual signal. We demonstrate the performance of our model on the GRID dataset based on standard benchmarks.