 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open Research Dataset of the 1932 Cairo Congress of Arab Music
Jun 17, 2025This paper introduces ORD-CC32 , an open research dataset derived from the 1932 Cairo Congress of Arab Music recordings, a historically significant collection representing diverse Arab musical traditions. The dataset includes structured metadata, melodic and rhythmic mode tags (maqam and iqa), manually labeled tonic information, and acoustic features extracted using state-of-the-art pitch detection methods. These resources support computational studies of tuning, temperament, and regional variations in Arab music. A case study using pitch histograms demonstrates the potential for data-driven analysis of microtonal differences across regions. By making this dataset openly available, we aim to enable interdisciplinary research in computational ethnomusicology, music information retrieval (MIR), cultural studies, and digital heritage preservation. ORD-CC32 is shared on Zenodo with tools for feature extraction and metadata retrieval.
Glottal Source Estimation using an Automatic Chirp Decomposition
May 16, 2020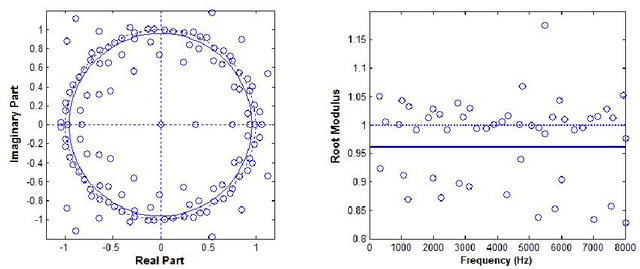

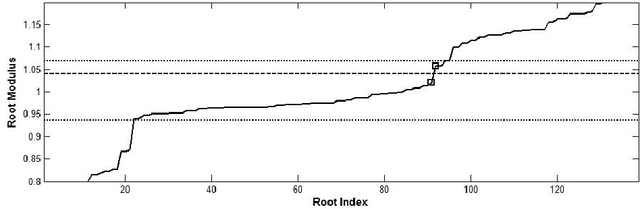
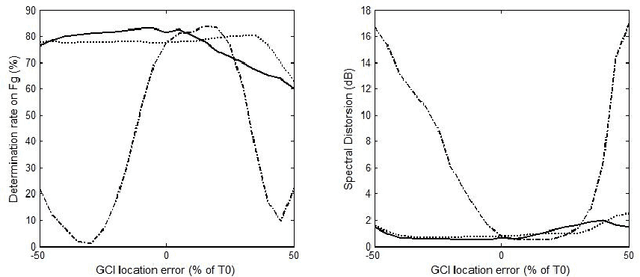
In a previous work, we showed that the glottal source can be estimated from speech signals by computing the Zeros of the Z-Transform (ZZT). Decomposition was achieved by separating the roots inside (causal contribution) and outside (anticausal contribution) the unit circle. In order to guarantee a correct deconvolution, time alignment on the Glottal Closure Instants (GCIs) was shown to be essential. This paper extends the formalism of ZZT by evaluating the Z-transform on a contour possibly different from the unit circle. A method is proposed for determining automatically this contour by inspecting the root distribution. The derived Zeros of the Chirp Z-Transform (ZCZT)-based technique turns out to be much more robust to GCI location errors.
Excitation-based Voice Quality Analysis and Modification
Jan 02, 2020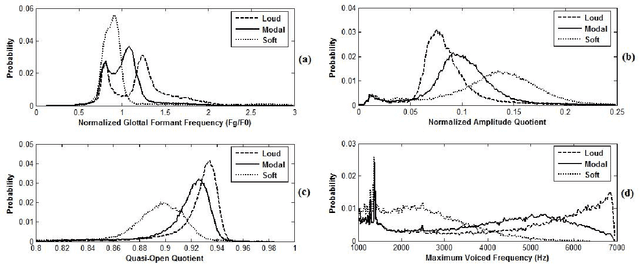
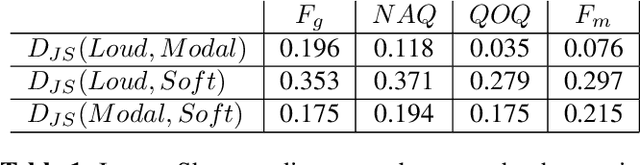
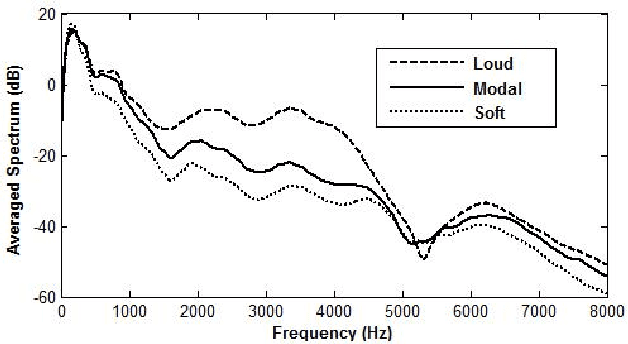

This paper investigates the differences occuring in the excitation for different voice qualities. Its goal is two-fold. First a large corpus containing three voice qualities (modal, soft and loud) uttered by the same speaker is analyzed and significant differences in characteristics extracted from the excitation are observed. Secondly rules of modification derived from the analysis are used to build a voice quality transformation system applied as a post-process to HMM-based speech synthesis. The system is shown to effectively achieve the transformations while maintaining the delivered quality.
Causal-Anticausal Decomposition of Speech using Complex Cepstrum for Glottal Source Estimation
Dec 30, 2019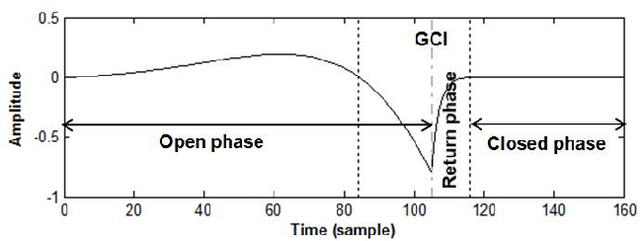
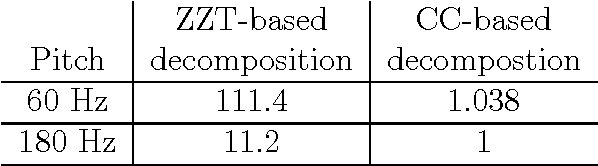

Complex cepstrum is known in the literature for linearly separating causal and anticausal components. Relying on advances achieved by the Zeros of the Z-Transform (ZZT) technique, we here investigate the possibility of using complex cepstrum for glottal flow estimation on a large-scale database. Via a systematic study of the windowing effects on the deconvolution quality, we show that the complex cepstrum causal-anticausal decomposition can be effectively used for glottal flow estimation when specific windowing criteria are met. It is also shown that this complex cepstral decomposition gives similar glottal estimates as obtained with the ZZT method. However, as complex cepstrum uses FFT operations instead of requiring the factoring of high-degree polynomials, the method benefits from a much higher speed. Finally in our tests on a large corpus of real expressive speech, we show that the proposed method has the potential to be used for voice quality analysis.
Complex Cepstrum-based Decomposition of Speech for Glottal Source Estimation
Dec 29, 2019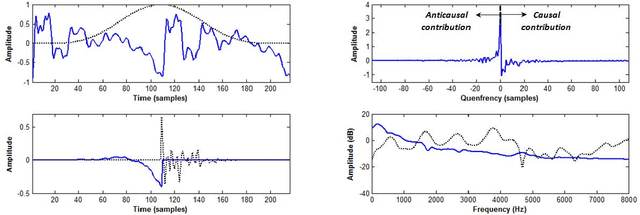
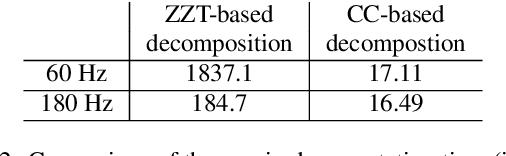
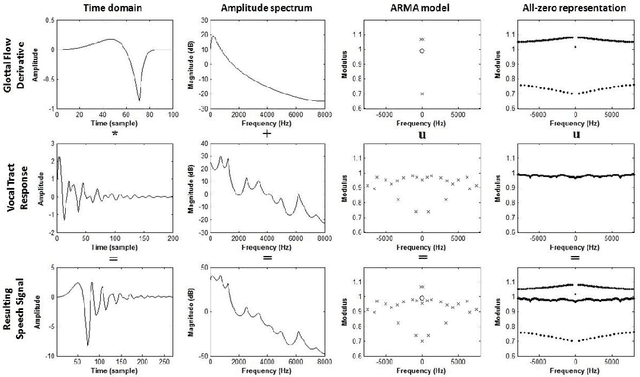
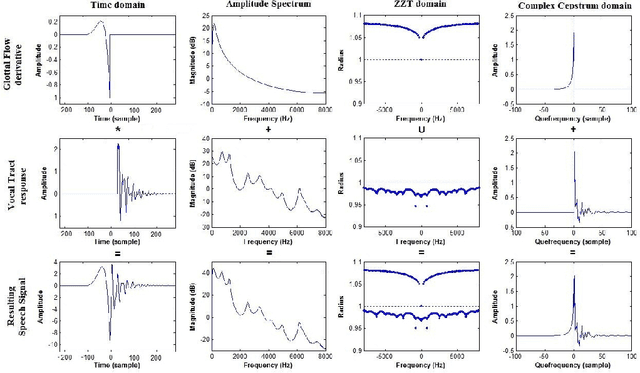
Homomorphic analysis is a well-known method for the separation of non-linearly combined signals. More particularly, the use of complex cepstrum for source-tract deconvolution has been discussed in various articles. However there exists no study which proposes a glottal flow estimation methodology based on cepstrum and reports effective results. In this paper, we show that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of a windowed speech signal as done by the Zeros of the Z-Transform (ZZT) decomposition. Based on exactly the same principles presented for ZZT decomposition, windowing should be applied such that the windowed speech signals exhibit mixed-phase characteristics which conform the speech production model that the anticausal component is mainly due to the glottal flow open phase. The advantage of the complex cepstrum-based approach compared to the ZZT decomposition is its much higher speed.
A Comparative Study of Glottal Source Estimation Techniques
Dec 28, 2019

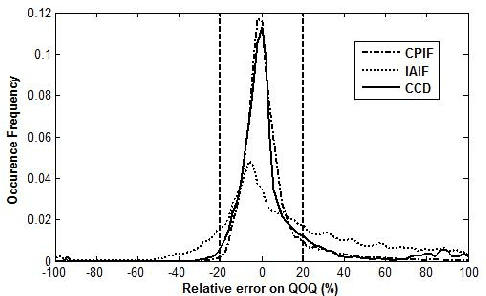
Source-tract decomposition (or glottal flow estimation) is one of the basic problems of speech processing. For this, several techniques have been proposed in the literature. However studies comparing different approaches are almost nonexistent. Besides, experiments have been systematically performed either on synthetic speech or on sustained vowels. In this study we compare three of the main representative state-of-the-art methods of glottal flow estimation: closed-phase inverse filtering, iterative and adaptive inverse filtering, and mixed-phase decomposition. These techniques are first submitted to an objective assessment test on synthetic speech signals. Their sensitivity to various factors affecting the estimation quality, as well as their robustness to noise are studied. In a second experiment, their ability to label voice quality (tensed, modal, soft) is studied on a large corpus of real connected speech. It is shown that changes of voice quality are reflected by significant modifications in glottal feature distributions. Techniques based on the mixed-phase decomposition and on a closed-phase inverse filtering process turn out to give the best results on both clean synthetic and real speech signals. On the other hand, iterative and adaptive inverse filtering is recommended in noisy environments for its high robustness.