 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Latency Sequence-to-Sequence Speech Recognition and Translation by Partial Hypothesis Selection
Paper and Code
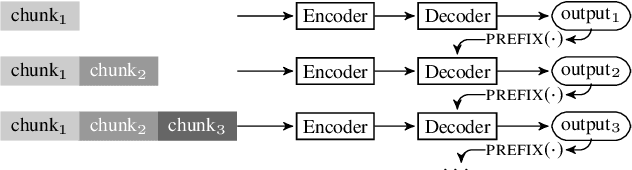
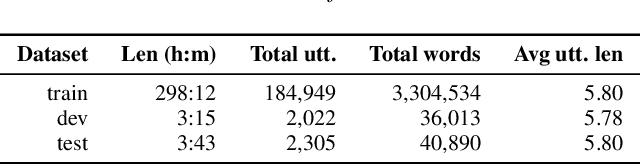
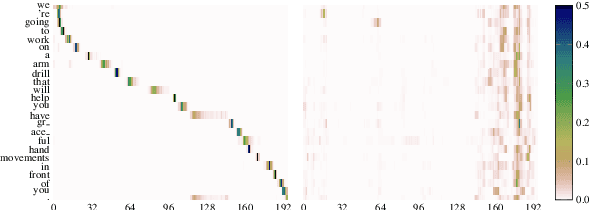
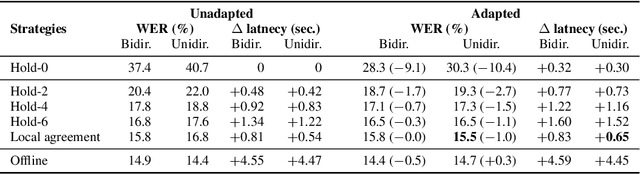
Encoder-decoder models provide a generic architecture for sequence-to-sequence tasks such as speech recognition and translation. While offline systems are often evaluated on quality metrics like word error rates (WER) and BLEU, latency is also a crucial factor in many practical use-cases. We propose three latency reduction techniques for chunk-based incremental inference and evaluate their efficiency in terms of accuracy-latency trade-off. On the 300-hour How2 dataset, we reduce latency by 83% to 0.8 second by sacrificing 1% WER (6% rel.) compared to offline transcription. Although our experiments use the Transformer, the hypothesis selection strategies are applicable to other encoder-decoder models. To avoid expensive re-computation, we use a unidirectionally-attending encoder. After an adaptation procedure to partial sequences, the unidirectional model performs on-par with the original model. We further show that our approach is also applicable to low-latency speech translation. On How2 English-Portuguese speech translation, we reduce latency to 0.7 second (-84% rel.) while incurring a loss of 2.4 BLEU points (5% rel.) compared to the offline system.