 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
An Empirical Study of End-to-end Simultaneous Speech Translation Decoding Strategies
Mar 04, 2021
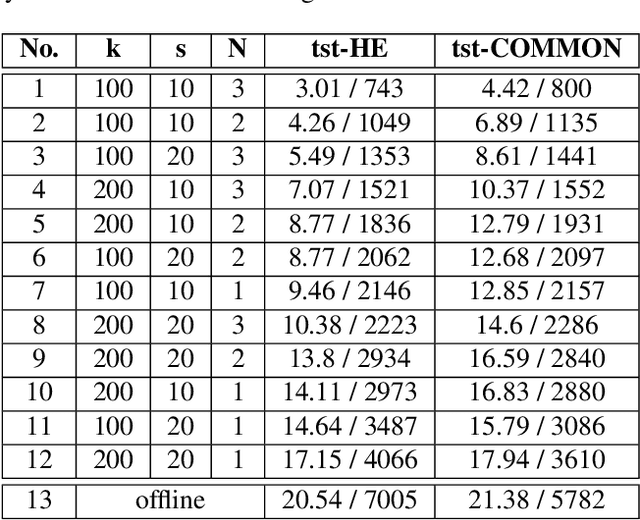
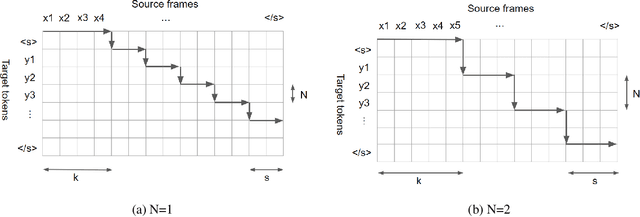
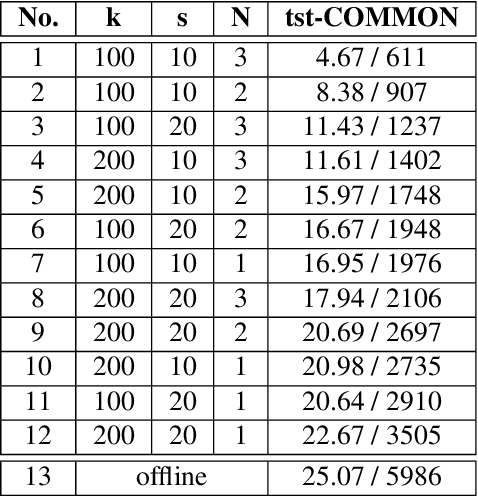
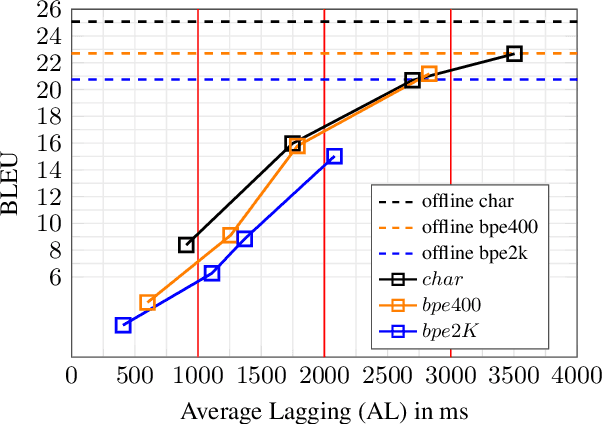
This paper proposes a decoding strategy for end-to-end simultaneous speech translation. We leverage end-to-end models trained in offline mode and conduct an empirical study for two language pairs (English-to-German and English-to-Portuguese). We also investigate different output token granularities including characters and Byte Pair Encoding (BPE) units. The results show that the proposed decoding approach allows to control BLEU/Average Lagging trade-off along different latency regimes. Our best decoding settings achieve comparable results with a strong cascade model evaluated on the simultaneous translation track of IWSLT 2020 shared task.
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020
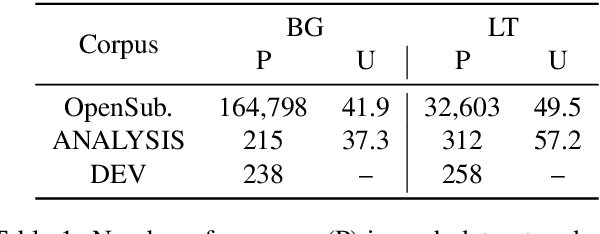
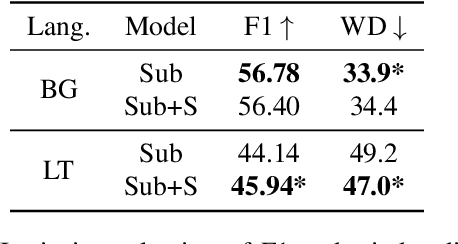

In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Temporarily-Aware Context Modelling using Generative Adversarial Networks for Speech Activity Detection
Apr 02, 2020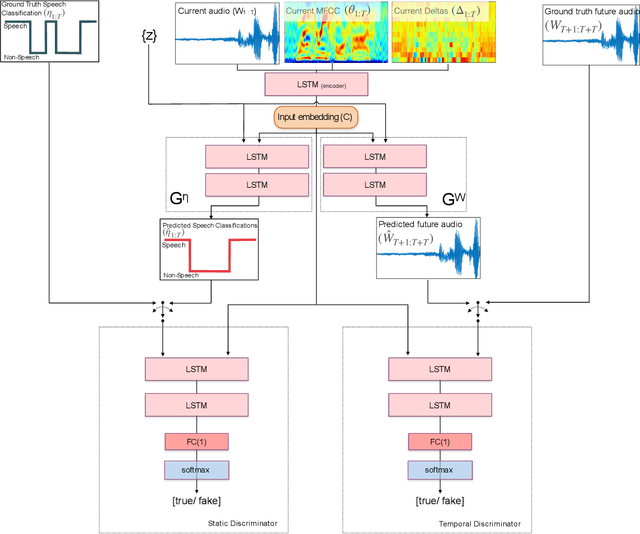
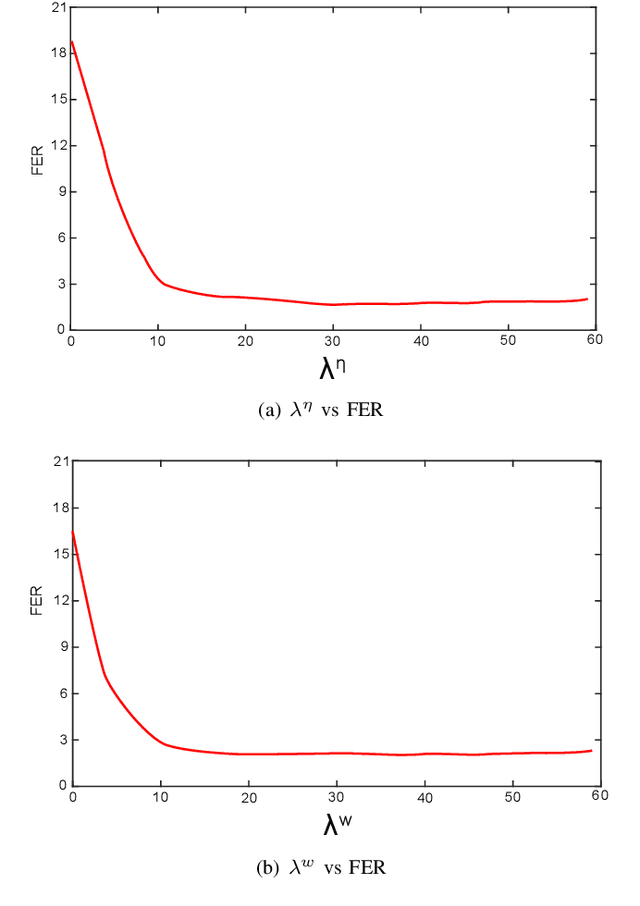
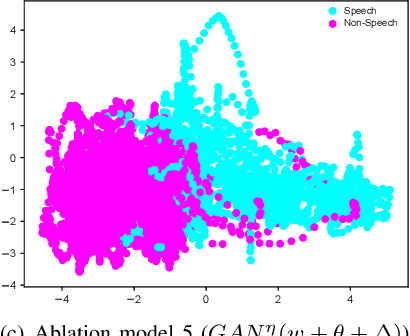

This paper presents a novel framework for Speech Activity Detection (SAD). Inspired by the recent success of multi-task learning approaches in the speech processing domain, we propose a novel joint learning framework for SAD. We utilise generative adversarial networks to automatically learn a loss function for joint prediction of the frame-wise speech/ non-speech classifications together with the next audio segment. In order to exploit the temporal relationships within the input signal, we propose a temporal discriminator which aims to ensure that the predicted signal is temporally consistent. We evaluate the proposed framework on multiple public benchmarks, including NIST OpenSAT' 17, AMI Meeting and HAVIC, where we demonstrate its capability to outperform state-of-the-art SAD approaches. Furthermore, our cross-database evaluations demonstrate the robustness of the proposed approach across different languages, accents, and acoustic environments.
Analysis of French Phonetic Idiosyncrasies for Accent Recognition
Oct 18, 2021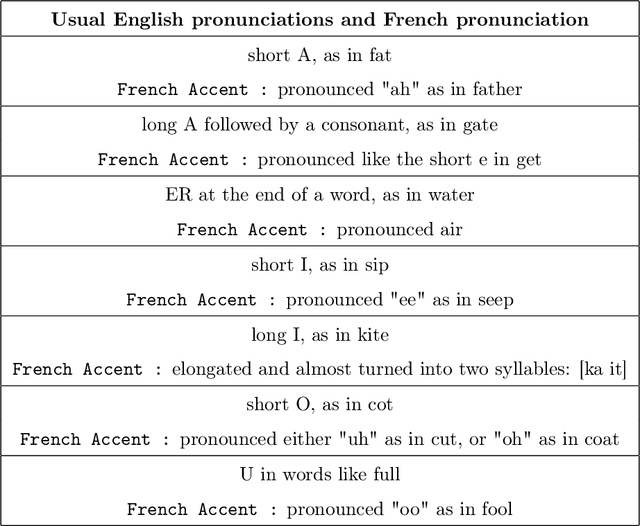
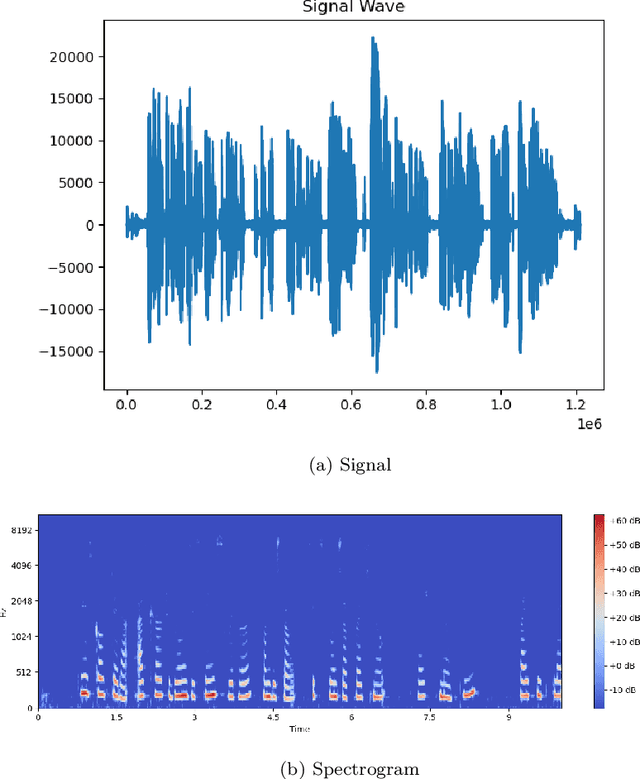
Speech recognition systems have made tremendous progress since the last few decades. They have developed significantly in identifying the speech of the speaker. However, there is a scope of improvement in speech recognition systems in identifying the nuances and accents of a speaker. It is known that any specific natural language may possess at least one accent. Despite the identical word phonemic composition, if it is pronounced in different accents, we will have sound waves, which are different from each other. Differences in pronunciation, in accent and intonation of speech in general, create one of the most common problems of speech recognition. If there are a lot of accents in language we should create the acoustic model for each separately. We carry out a systematic analysis of the problem in the accurate classification of accents. We use traditional machine learning techniques and convolutional neural networks, and show that the classical techniques are not sufficiently efficient to solve this problem. Using spectrograms of speech signals, we propose a multi-class classification framework for accent recognition. In this paper, we focus our attention on the French accent. We also identify its limitation by understanding the impact of French idiosyncrasies on its spectrograms.
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021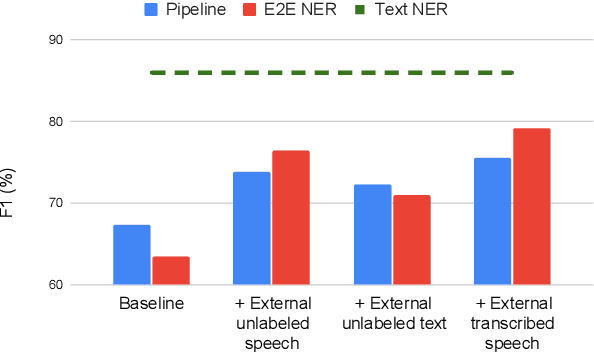

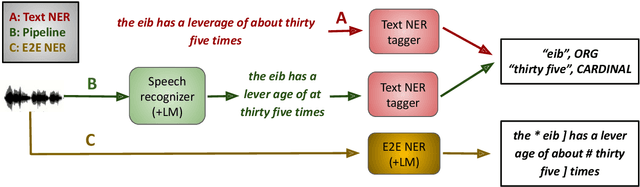
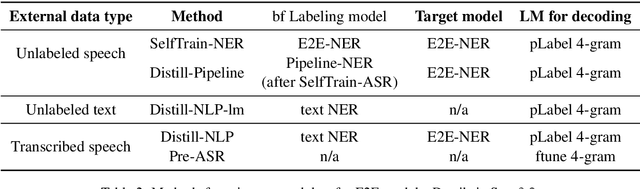
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
FluentNet: End-to-End Detection of Speech Disfluency with Deep Learning
Sep 23, 2020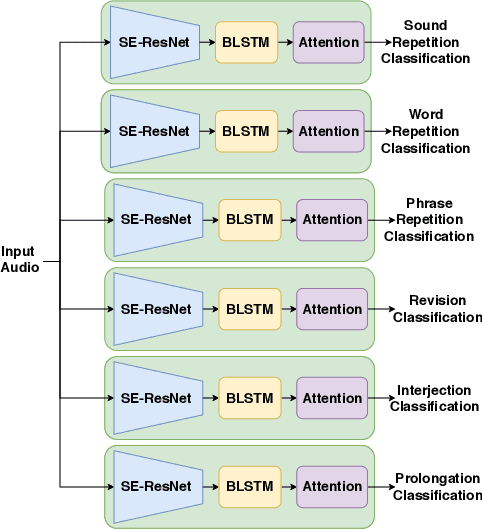
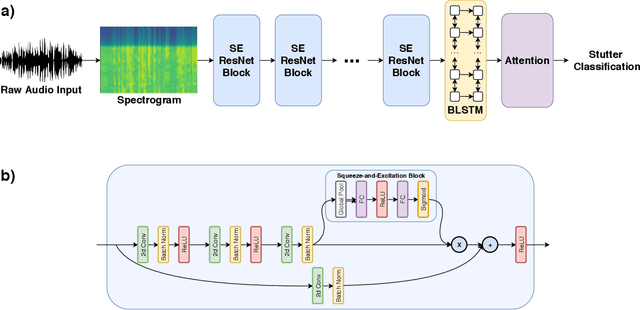
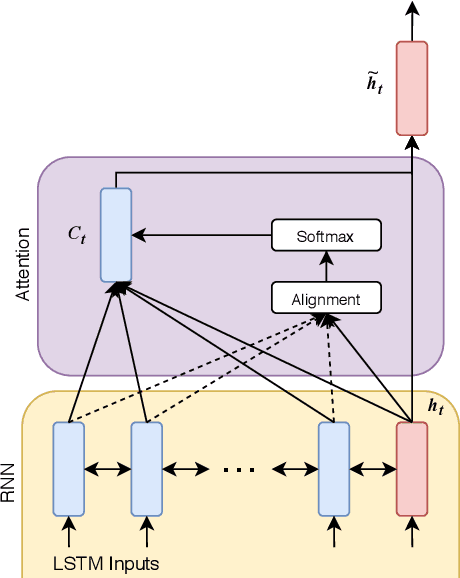
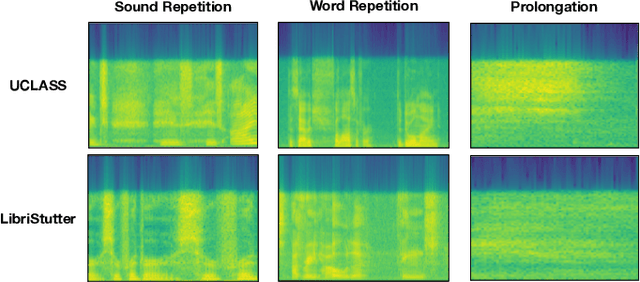
Strong presentation skills are valuable and sought-after in workplace and classroom environments alike. Of the possible improvements to vocal presentations, disfluencies and stutters in particular remain one of the most common and prominent factors of someone's demonstration. Millions of people are affected by stuttering and other speech disfluencies, with the majority of the world having experienced mild stutters while communicating under stressful conditions. While there has been much research in the field of automatic speech recognition and language models, there lacks the sufficient body of work when it comes to disfluency detection and recognition. To this end, we propose an end-to-end deep neural network, FluentNet, capable of detecting a number of different disfluency types. FluentNet consists of a Squeeze-and-Excitation Residual convolutional neural network which facilitate the learning of strong spectral frame-level representations, followed by a set of bidirectional long short-term memory layers that aid in learning effective temporal relationships. Lastly, FluentNet uses an attention mechanism to focus on the important parts of speech to obtain a better performance. We perform a number of different experiments, comparisons, and ablation studies to evaluate our model. Our model achieves state-of-the-art results by outperforming other solutions in the field on the publicly available UCLASS dataset. Additionally, we present LibriStutter: a disfluency dataset based on the public LibriSpeech dataset with synthesized stutters. We also evaluate FluentNet on this dataset, showing the strong performance of our model versus a number of benchmark techniques.
Self-Supervised Audio-and-Text Pre-training with Extremely Low-Resource Parallel Data
Apr 10, 2022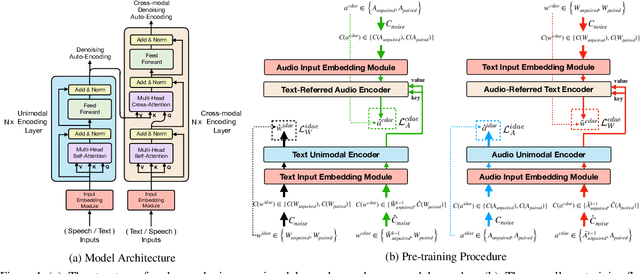
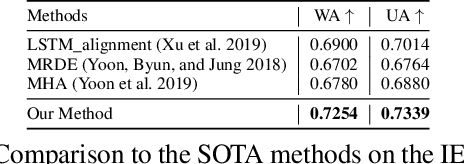
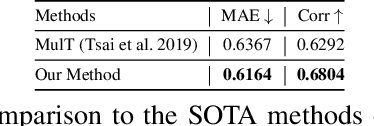
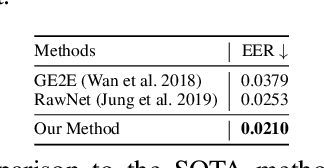
Multimodal pre-training for audio-and-text has recently been proved to be effective and has significantly improved the performance of many downstream speech understanding tasks. However, these state-of-the-art pre-training audio-text models work well only when provided with large amount of parallel audio-and-text data, which brings challenges on many languages that are rich in unimodal corpora but scarce of parallel cross-modal corpus. In this paper, we investigate whether it is possible to pre-train an audio-text multimodal model with extremely low-resource parallel data and extra non-parallel unimodal data. Our pre-training framework consists of the following components: (1) Intra-modal Denoising Auto-Encoding (IDAE), which is able to reconstruct input text (audio) representations from a noisy version of itself. (2) Cross-modal Denoising Auto-Encoding (CDAE), which is pre-trained to reconstruct the input text (audio), given both a noisy version of the input text (audio) and the corresponding translated noisy audio features (text embeddings). (3) Iterative Denoising Process (IDP), which iteratively translates raw audio (text) and the corresponding text embeddings (audio features) translated from previous iteration into the new less-noisy text embeddings (audio features). We adapt a dual cross-modal Transformer as our backbone model which consists of two unimodal encoders for IDAE and two cross-modal encoders for CDAE and IDP. Our method achieves comparable performance on multiple downstream speech understanding tasks compared with the model pre-trained on fully parallel data, demonstrating the great potential of the proposed method. Our code is available at: \url{https://github.com/KarlYuKang/Low-Resource-Multimodal-Pre-training}.
Hierarchical prosody modeling and control in non-autoregressive parallel neural TTS
Oct 06, 2021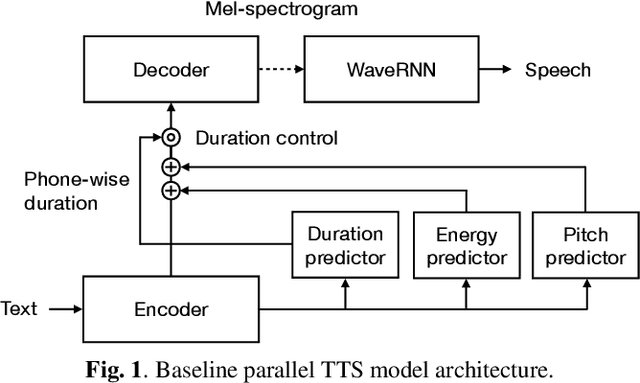
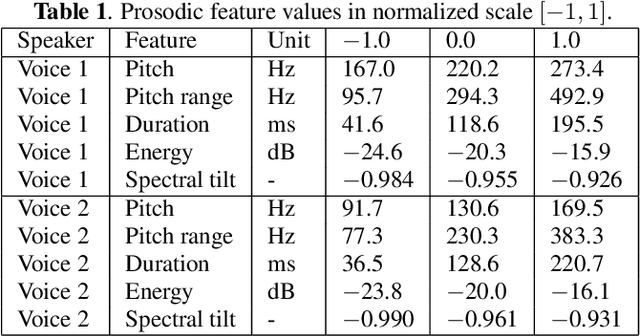
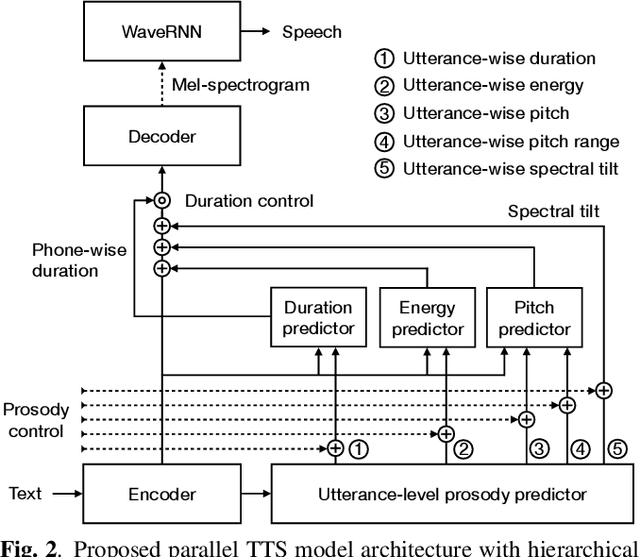
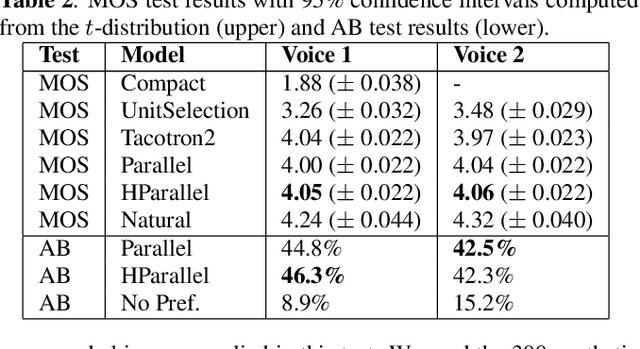
Neural text-to-speech (TTS) synthesis can generate speech that is indistinguishable from natural speech. However, the synthetic speech often represents the average prosodic style of the database instead of having more versatile prosodic variation. Moreover, many models lack the ability to control the output prosody, which does not allow for different styles for the same text input. In this work, we train a non-autoregressive parallel neural TTS model hierarchically conditioned on both coarse and fine-grained acoustic speech features to learn a latent prosody space with intuitive and meaningful dimensions. Experiments show that a non-autoregressive TTS model hierarchically conditioned on utterance-wise pitch, pitch range, duration, energy, and spectral tilt can effectively control each prosodic dimension, generate a wide variety of speaking styles, and provide word-wise emphasis control, while maintaining equal or better quality to the baseline model.
A Comparative Study on Neural Architectures and Training Methods for Japanese Speech Recognition
Jun 09, 2021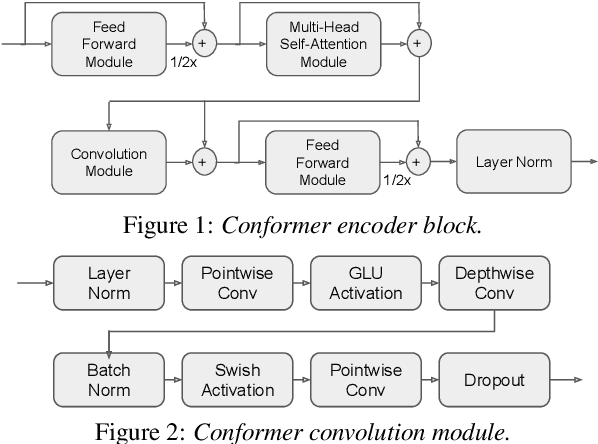
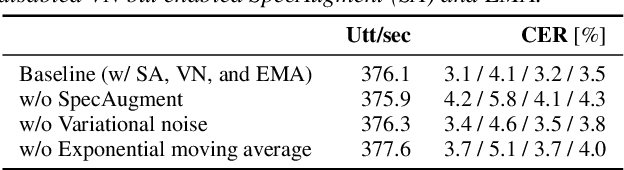
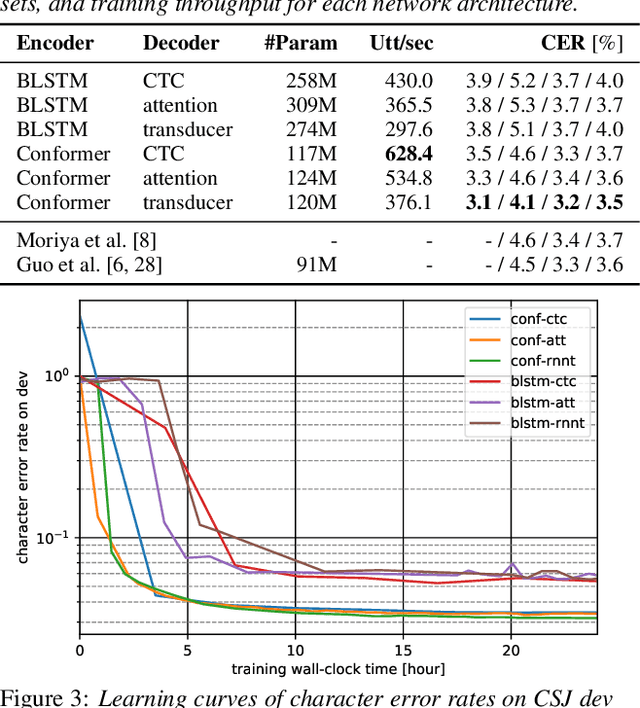
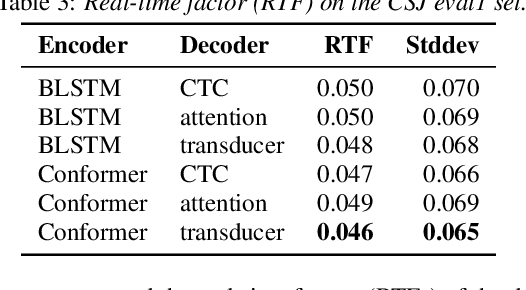
End-to-end (E2E) modeling is advantageous for automatic speech recognition (ASR) especially for Japanese since word-based tokenization of Japanese is not trivial, and E2E modeling is able to model character sequences directly. This paper focuses on the latest E2E modeling techniques, and investigates their performances on character-based Japanese ASR by conducting comparative experiments. The results are analyzed and discussed in order to understand the relative advantages of long short-term memory (LSTM), and Conformer models in combination with connectionist temporal classification, transducer, and attention-based loss functions. Furthermore, the paper investigates on effectivity of the recent training techniques such as data augmentation (SpecAugment), variational noise injection, and exponential moving average. The best configuration found in the paper achieved the state-of-the-art character error rates of 4.1%, 3.2%, and 3.5% for Corpus of Spontaneous Japanese (CSJ) eval1, eval2, and eval3 tasks, respectively. The system is also shown to be computationally efficient thanks to the efficiency of Conformer transducers.
On Investigation of Unsupervised Speech Factorization Based on Normalization Flow
Oct 29, 2019
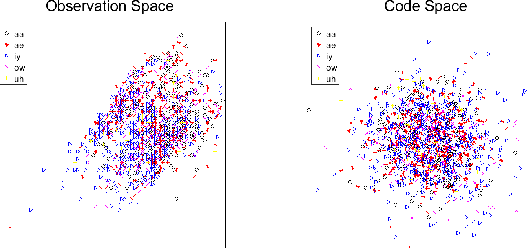
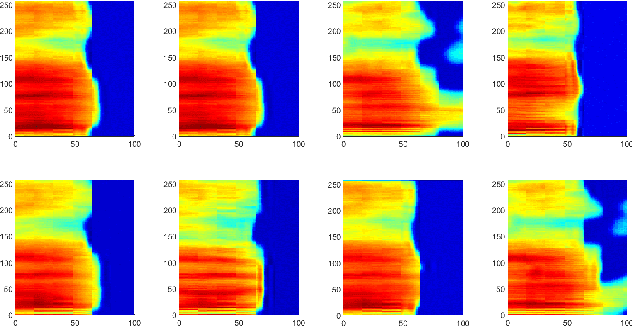
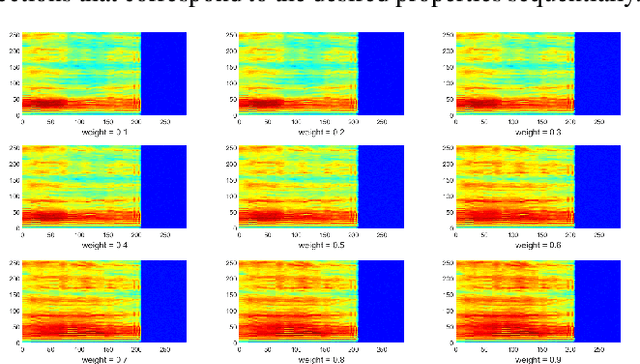
Speech signals are complex composites of various information, including phonetic content, speaker traits, channel effect, etc. Decomposing this complicated mixture into independent factors, i.e., speech factorization, is fundamentally important and plays the central role in many important algorithms of modern speech processing tasks. In this paper, we present a preliminary investigation on unsupervised speech factorization based on the normalization flow model. This model constructs a complex invertible transform, by which we can project speech segments into a latent code space where the distribution is a simple diagonal Gaussian. Our preliminary investigation on the TIMIT database shows that this code space exhibits favorable properties such as denseness and pseudo linearity, and perceptually important factors such as phonetic content and speaker trait can be represented as particular directions within the code space.