 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of External Data for Spoken Named Entity Recognition
Paper and Code
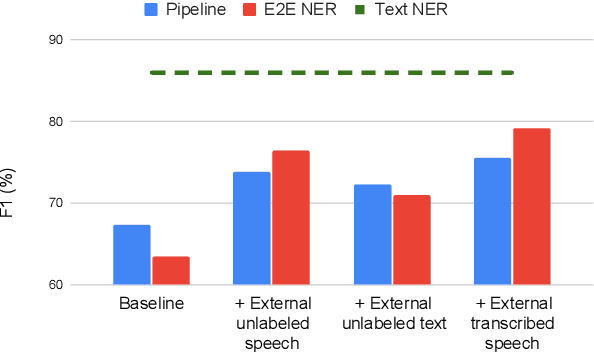

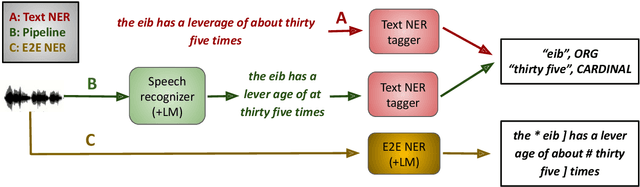
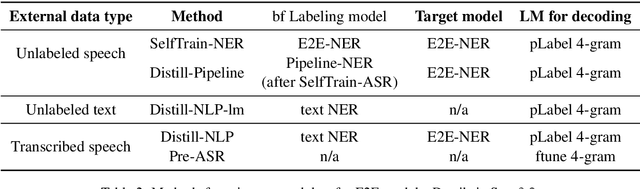
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.