 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Bias and Fairness In Deep Speaker Recognition
Mar 14, 2023



With the ubiquity of smart devices that use speaker recognition (SR) systems as a means of authenticating individuals and personalizing their services, fairness of SR systems has becomes an important point of focus. In this paper we study the notion of fairness in recent SR systems based on 3 popular and relevant definitions, namely Statistical Parity, Equalized Odds, and Equal Opportunity. We examine 5 popular neural architectures and 5 commonly used loss functions in training SR systems, while evaluating their fairness against gender and nationality groups. Our detailed experiments shed light on this concept and demonstrate that more sophisticated encoder architectures better align with the definitions of fairness. Additionally, we find that the choice of loss functions can significantly impact the bias of SR models.
Audio Representation Learning by Distilling Video as Privileged Information
Feb 06, 2023Deep audio representation learning using multi-modal audio-visual data often leads to a better performance compared to uni-modal approaches. However, in real-world scenarios both modalities are not always available at the time of inference, leading to performance degradation by models trained for multi-modal inference. In this work, we propose a novel approach for deep audio representation learning using audio-visual data when the video modality is absent at inference. For this purpose, we adopt teacher-student knowledge distillation under the framework of learning using privileged information (LUPI). While the previous methods proposed for LUPI use soft-labels generated by the teacher, in our proposed method we use embeddings learned by the teacher to train the student network. We integrate our method in two different settings: sequential data where the features are divided into multiple segments throughout time, and non-sequential data where the entire features are treated as one whole segment. In the non-sequential setting both the teacher and student networks are comprised of an encoder component and a task header. We use the embeddings produced by the encoder component of the teacher to train the encoder of the student, while the task header of the student is trained using ground-truth labels. In the sequential setting, the networks have an additional aggregation component that is placed between the encoder and task header. We use two sets of embeddings produced by the encoder and aggregation component of the teacher to train the student. Similar to the non-sequential setting, the task header of the student network is trained using ground-truth labels. We test our framework on two different audio-visual tasks, namely speaker recognition and speech emotion recognition and show considerable improvements over sole audio-based recognition as well as prior works that use LUPI.
Fine-grained Early Frequency Attention for Deep Speaker Recognition
Jul 20, 2022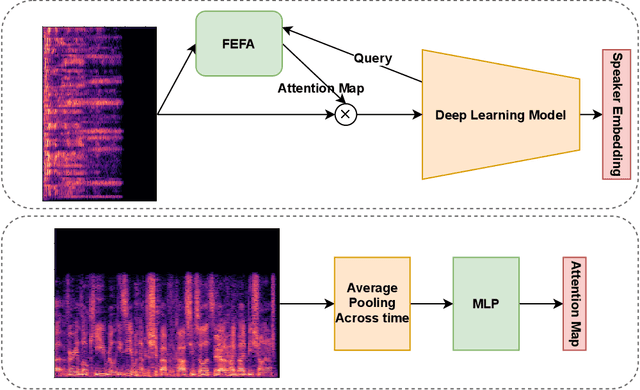

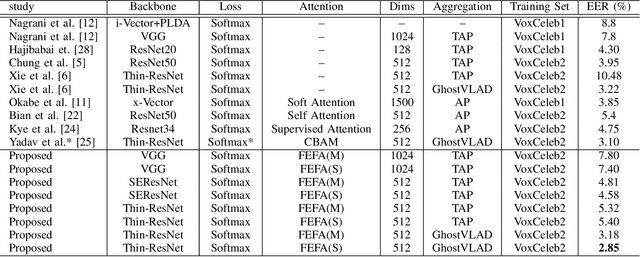
Attention mechanisms have emerged as important tools that boost the performance of deep models by allowing them to focus on key parts of learned embeddings. However, current attention mechanisms used in speaker recognition tasks fail to consider fine-grained information items such as frequency bins in input spectral representations used by the deep networks. To address this issue, we propose the novel Fine-grained Early Frequency Attention (FEFA) for speaker recognition in-the-wild. Once integrated into a deep neural network, our proposed mechanism works by obtaining queries from early layers of the network and generating learnable weights to attend to information items as small as the frequency bins in the input spectral representations. To evaluate the performance of FEFA, we use several well-known deep models as backbone networks and integrate our attention module in their pipelines. The overall performance of these networks (with and without FEFA) are evaluated on the VoxCeleb1 dataset, where we observe considerable improvements when FEFA is used.
Siamese Capsule Network for End-to-End Speaker Recognition In The Wild
Sep 28, 2020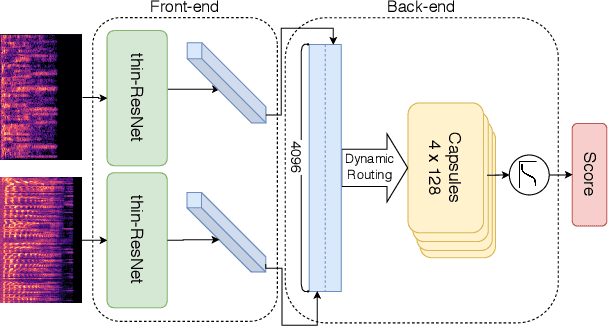

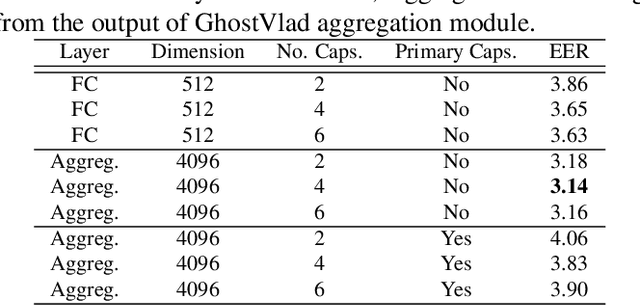
We propose an end-to-end deep model for speaker verification in the wild. Our model uses thin-ResNet for extracting speaker embeddings from utterances and a Siamese capsule network and dynamic routing as the Back-end to calculate a similarity score between the embeddings. We conduct a series of experiments and comparisons on our model to state-of-the-art solutions, showing that our model outperforms all the other models using substantially less amount of training data. We also perform additional experiments to study the impact of different speaker embeddings on the Siamese capsule network. We show that the best performance is achieved by using embeddings obtained directly from the feature aggregation module of the Front-end and passing them to higher capsules using dynamic routing.
FluentNet: End-to-End Detection of Speech Disfluency with Deep Learning
Sep 23, 2020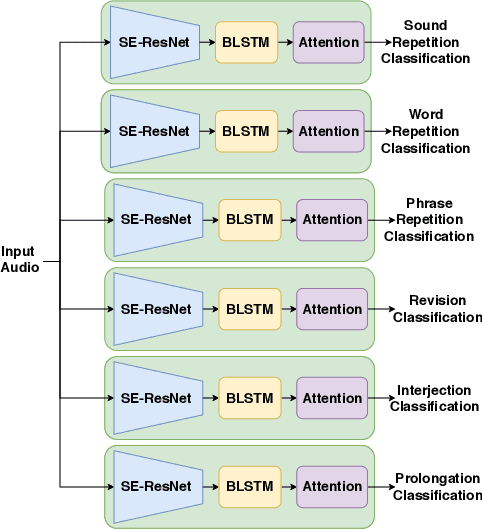
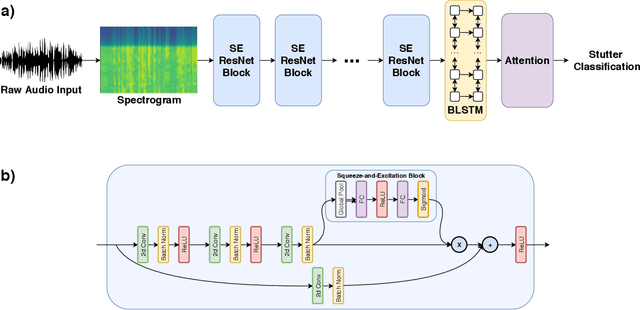
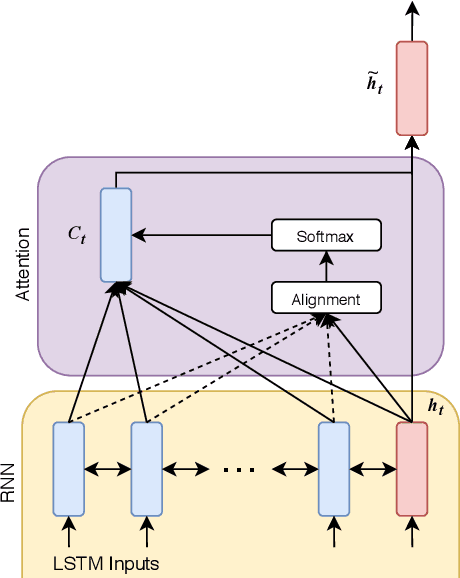
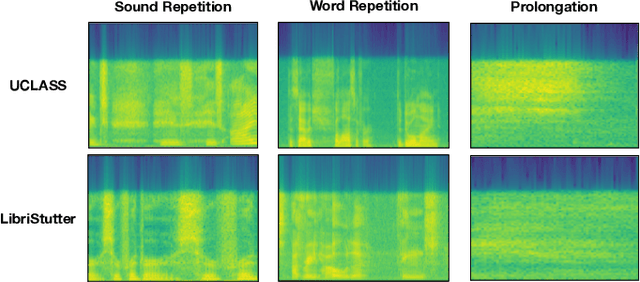
Strong presentation skills are valuable and sought-after in workplace and classroom environments alike. Of the possible improvements to vocal presentations, disfluencies and stutters in particular remain one of the most common and prominent factors of someone's demonstration. Millions of people are affected by stuttering and other speech disfluencies, with the majority of the world having experienced mild stutters while communicating under stressful conditions. While there has been much research in the field of automatic speech recognition and language models, there lacks the sufficient body of work when it comes to disfluency detection and recognition. To this end, we propose an end-to-end deep neural network, FluentNet, capable of detecting a number of different disfluency types. FluentNet consists of a Squeeze-and-Excitation Residual convolutional neural network which facilitate the learning of strong spectral frame-level representations, followed by a set of bidirectional long short-term memory layers that aid in learning effective temporal relationships. Lastly, FluentNet uses an attention mechanism to focus on the important parts of speech to obtain a better performance. We perform a number of different experiments, comparisons, and ablation studies to evaluate our model. Our model achieves state-of-the-art results by outperforming other solutions in the field on the publicly available UCLASS dataset. Additionally, we present LibriStutter: a disfluency dataset based on the public LibriSpeech dataset with synthesized stutters. We also evaluate FluentNet on this dataset, showing the strong performance of our model versus a number of benchmark techniques.
Knowing What to Listen to: Early Attention for Deep Speech Representation Learning
Sep 03, 2020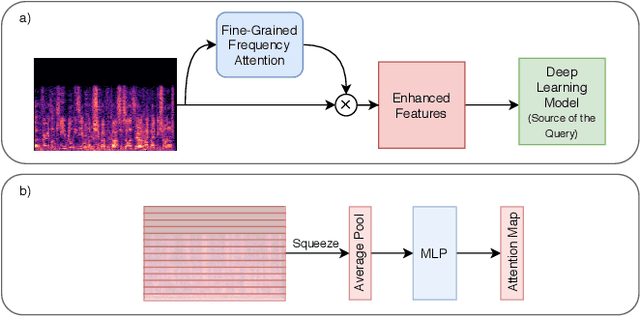
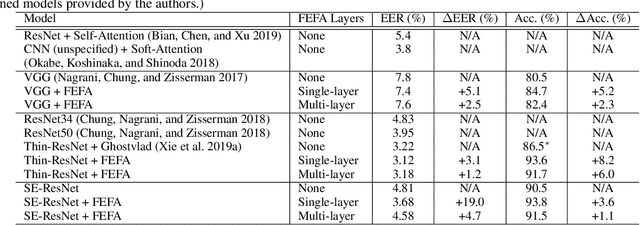
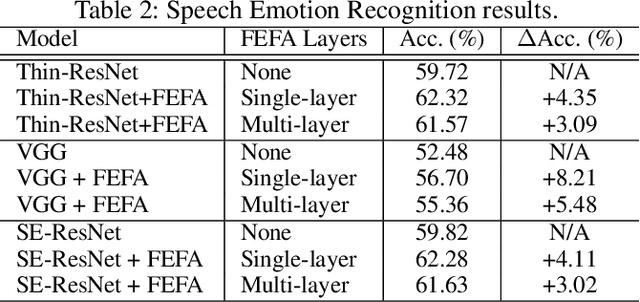
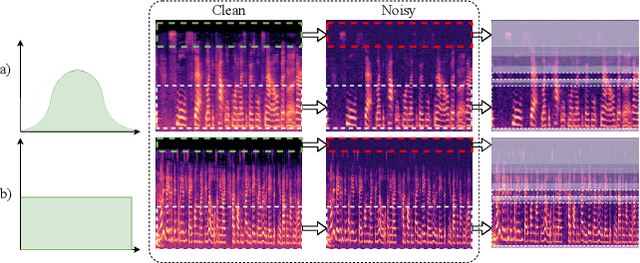
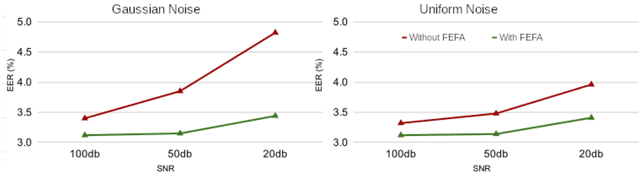
Deep learning techniques have considerably improved speech processing in recent years. Speech representations extracted by deep learning models are being used in a wide range of tasks such as speech recognition, speaker recognition, and speech emotion recognition. Attention models play an important role in improving deep learning models. However current attention mechanisms are unable to attend to fine-grained information items. In this paper we propose the novel Fine-grained Early Frequency Attention (FEFA) for speech signals. This model is capable of focusing on information items as small as frequency bins. We evaluate the proposed model on two popular tasks of speaker recognition and speech emotion recognition. Two widely used public datasets, VoxCeleb and IEMOCAP, are used for our experiments. The model is implemented on top of several prominent deep models as backbone networks to evaluate its impact on performance compared to the original networks and other related work. Our experiments show that by adding FEFA to different CNN architectures, performance is consistently improved by substantial margins, even setting a new state-of-the-art for the speaker recognition task. We also tested our model against different levels of added noise showing improvements in robustness and less sensitivity compared to the backbone networks.
Detecting Multiple Speech Disfluencies using a Deep Residual Network with Bidirectional Long Short-Term Memory
Oct 17, 2019
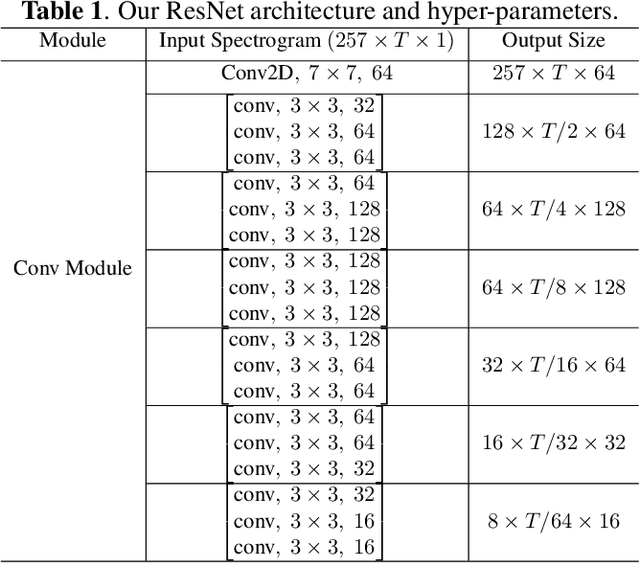


Stuttering is a speech impediment affecting tens of millions of people on an everyday basis. Even with its commonality, there is minimal data and research on the identification and classification of stuttered speech. This paper tackles the problem of detection and classification of different forms of stutter. As opposed to most existing works that identify stutters with language models, our work proposes a model that relies solely on acoustic features, allowing for identification of several variations of stutter disfluencies without the need for speech recognition. Our model uses a deep residual network and bidirectional long short-term memory layers to classify different types of stutters and achieves an average miss rate of 10.03%, outperforming the state-of-the-art by almost 27%
A Deep Neural Network for Short-Segment Speaker Recognition
Jul 22, 2019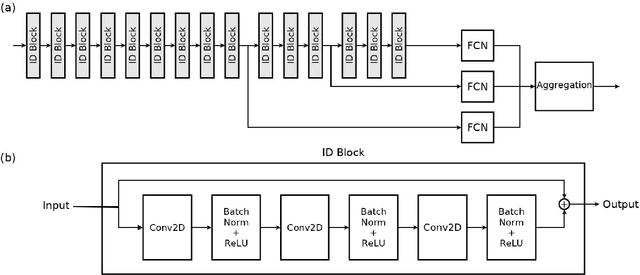
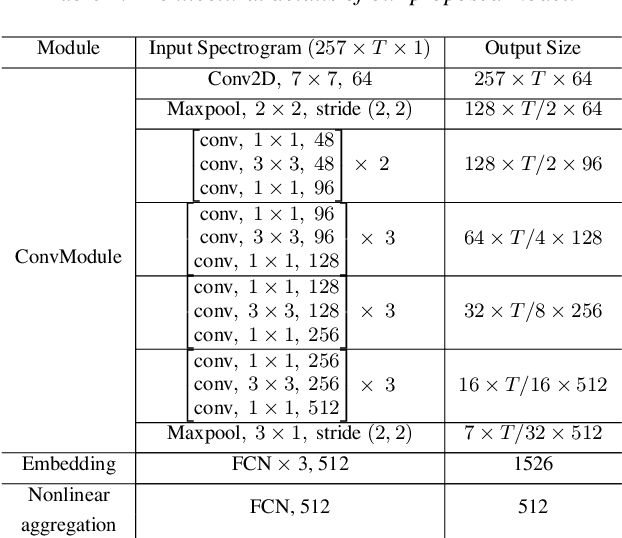

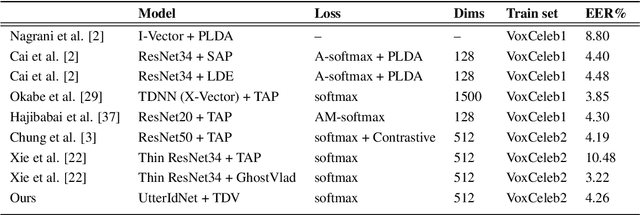
Todays interactive devices such as smart-phone assistants and smart speakers often deal with short-duration speech segments. As a result, speaker recognition systems integrated into such devices will be much better suited with models capable of performing the recognition task with short-duration utterances. In this paper, a new deep neural network, UtterIdNet, capable of performing speaker recognition with short speech segments is proposed. Our proposed model utilizes a novel architecture that makes it suitable for short-segment speaker recognition through an efficiently increased use of information in short speech segments. UtterIdNet has been trained and tested on the VoxCeleb datasets, the latest benchmarks in speaker recognition. Evaluations for different segment durations show consistent and stable performance for short segments, with significant improvement over the previous models for segments of 2 seconds, 1 second, and especially sub-second durations (250 ms and 500 ms).