 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis
Jun 23, 2022
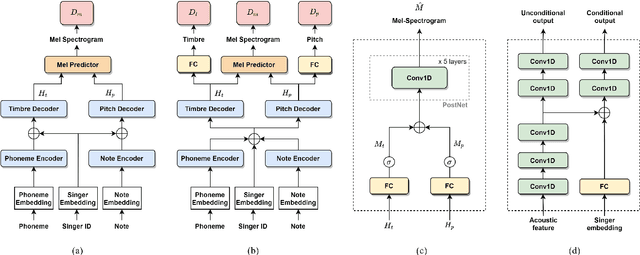
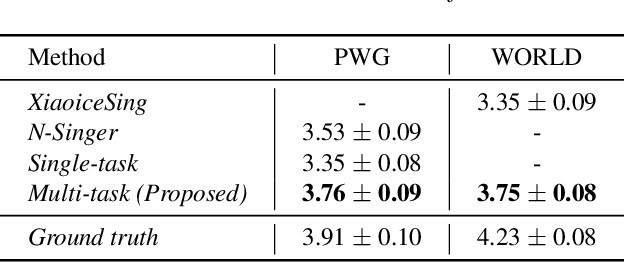
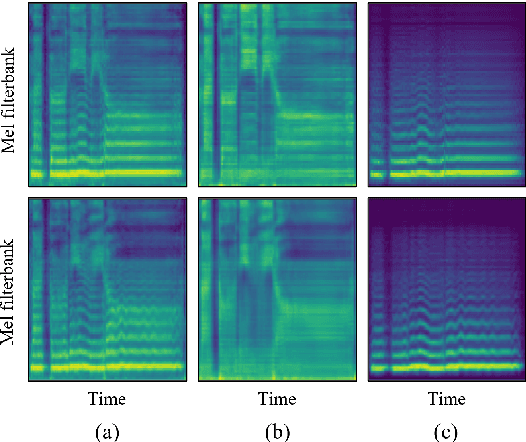
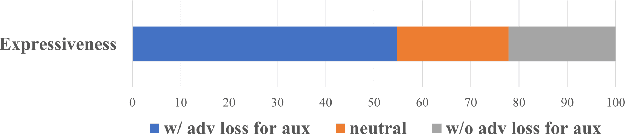
Recently, deep learning-based generative models have been introduced to generate singing voices. One approach is to predict the parametric vocoder features consisting of explicit speech parameters. This approach has the advantage that the meaning of each feature is explicitly distinguished. Another approach is to predict mel-spectrograms for a neural vocoder. However, parametric vocoders have limitations of voice quality and the mel-spectrogram features are difficult to model because the timbre and pitch information are entangled. In this study, we propose a singing voice synthesis model with multi-task learning to use both approaches -- acoustic features for a parametric vocoder and mel-spectrograms for a neural vocoder. By using the parametric vocoder features as auxiliary features, the proposed model can efficiently disentangle and control the timbre and pitch components of the mel-spectrogram. Moreover, a generative adversarial network framework is applied to improve the quality of singing voices in a multi-singer model. Experimental results demonstrate that our proposed model can generate more natural singing voices than the single-task models, while performing better than the conventional parametric vocoder-based model.
Non-autoregressive Mandarin-English Code-switching Speech Recognition with Pinyin Mask-CTC and Word Embedding Regularization
Apr 06, 2021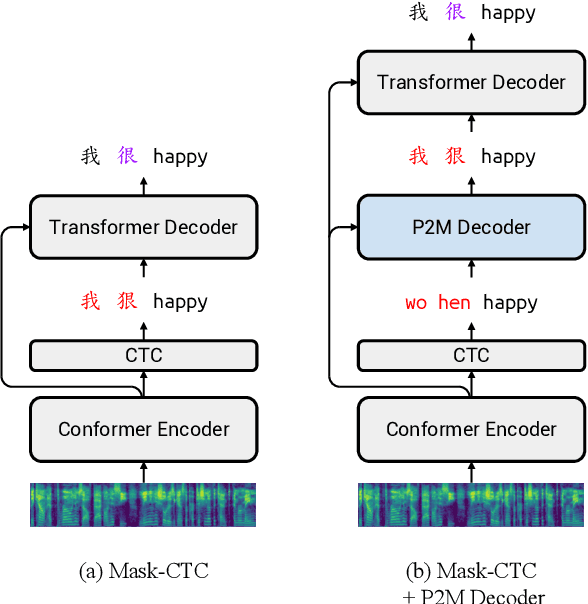
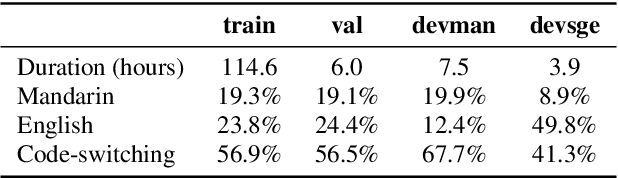
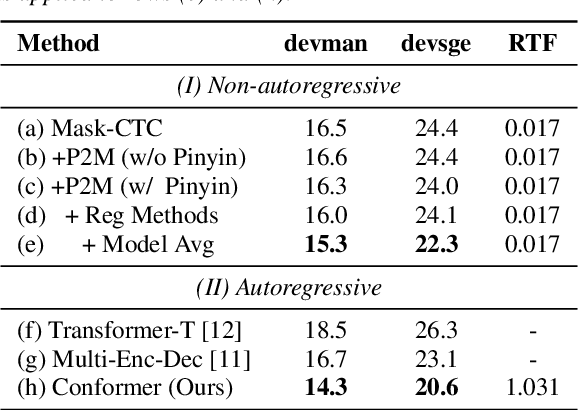
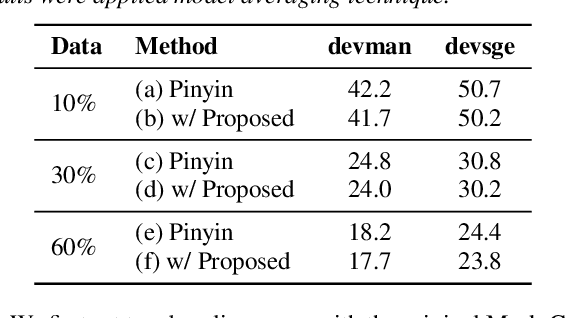
Mandarin-English code-switching (CS) is frequently used among East and Southeast Asian people. However, the intra-sentence language switching of the two very different languages makes recognizing CS speech challenging. Meanwhile, the recent successful non-autoregressive (NAR) ASR models remove the need for left-to-right beam decoding in autoregressive (AR) models and achieved outstanding performance and fast inference speed. Therefore, in this paper, we took advantage of the Mask-CTC NAR ASR framework to tackle the CS speech recognition issue. We propose changing the Mandarin output target of the encoder to Pinyin for faster encoder training, and introduce Pinyin-to-Mandarin decoder to learn contextualized information. Moreover, we propose word embedding label smoothing to regularize the decoder with contextualized information and projection matrix regularization to bridge that gap between the encoder and decoder. We evaluate the proposed methods on the SEAME corpus and achieved exciting results.
End-to-End Adversarial Text-to-Speech
Jun 05, 2020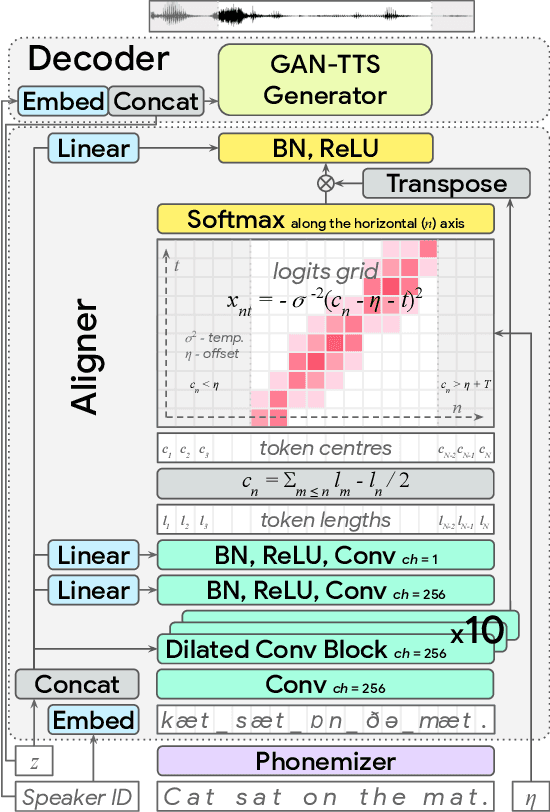
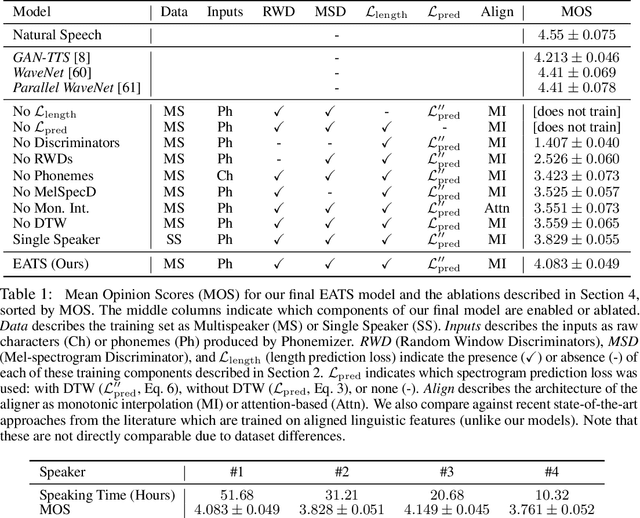

Modern text-to-speech synthesis pipelines typically involve multiple processing stages, each of which is designed or learnt independently from the rest. In this work, we take on the challenging task of learning to synthesise speech from normalised text or phonemes in an end-to-end manner, resulting in models which operate directly on character or phoneme input sequences and produce raw speech audio outputs. Our proposed generator is feed-forward and thus efficient for both training and inference, using a differentiable monotonic interpolation scheme to predict the duration of each input token. It learns to produce high fidelity audio through a combination of adversarial feedback and prediction losses constraining the generated audio to roughly match the ground truth in terms of its total duration and mel-spectrogram. To allow the model to capture temporal variation in the generated audio, we employ soft dynamic time warping in the spectrogram-based prediction loss. The resulting model achieves a mean opinion score exceeding 4 on a 5 point scale, which is comparable to the state-of-the-art models relying on multi-stage training and additional supervision.
Linguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Apr 07, 2022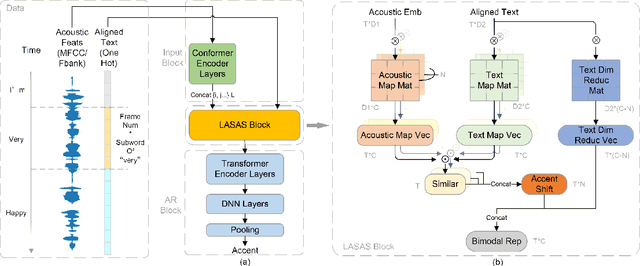
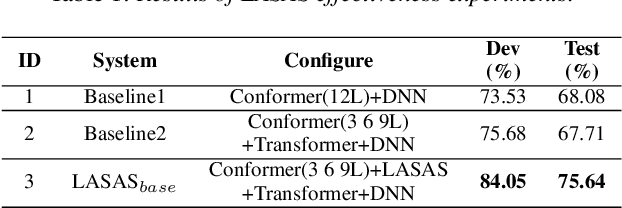
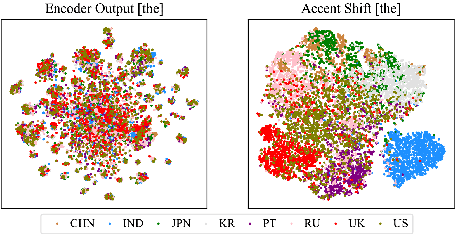
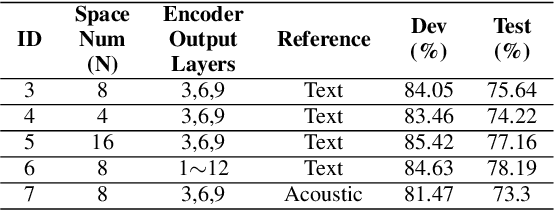
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.
Integration of deep learning with expectation maximization for spatial cue based speech separation in reverberant conditions
Feb 26, 2021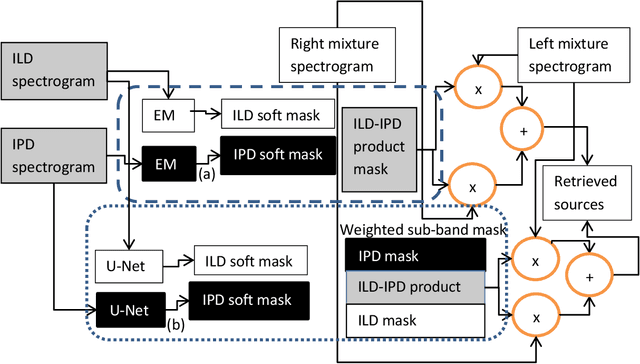
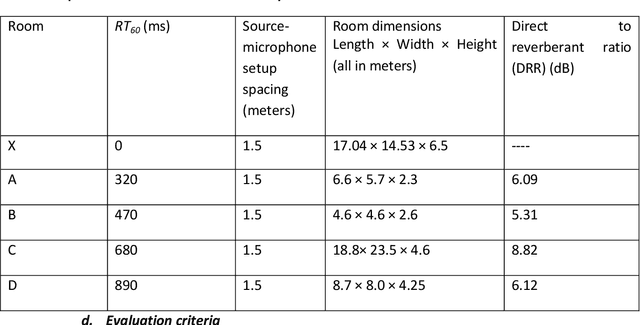
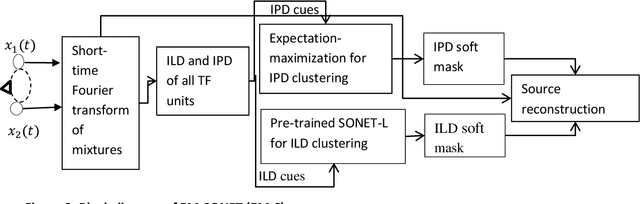

In this paper, we formulate a blind source separation (BSS) framework, which allows integrating U-Net based deep learning source separation network with probabilistic spatial machine learning expectation maximization (EM) algorithm for separating speech in reverberant conditions. Our proposed model uses a pre-trained deep learning convolutional neural network, U-Net, for clustering the interaural level difference (ILD) cues and machine learning expectation maximization (EM) algorithm for clustering the interaural phase difference (IPD) cues. The integrated model exploits the complementary strengths of the two approaches to BSS: the strong modeling power of supervised neural networks and the ease of unsupervised machine learning algorithms, whose few parameters can be estimated on as little as a single segment of an audio mixture. The results show an average improvement of 4.3 dB in signal to distortion ratio (SDR) and 4.3% in short time speech intelligibility (STOI) over the EM based source separation algorithm MESSL-GS (model-based expectation-maximization source separation and localization with garbage source) and 4.5 dB in SDR and 8% in STOI over deep learning convolutional neural network (U-Net) based speech separation algorithm SONET under the reverberant conditions ranging from anechoic to those mostly encountered in the real world.
WHALETRANS: E2E WHisper to nAturaL spEech conversion using modified TRANSformer network
Apr 20, 2020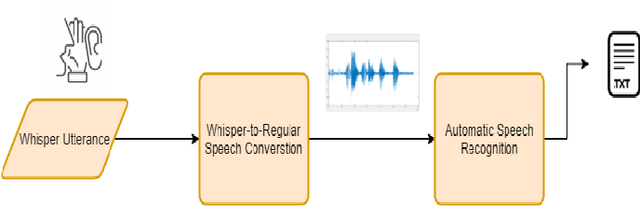
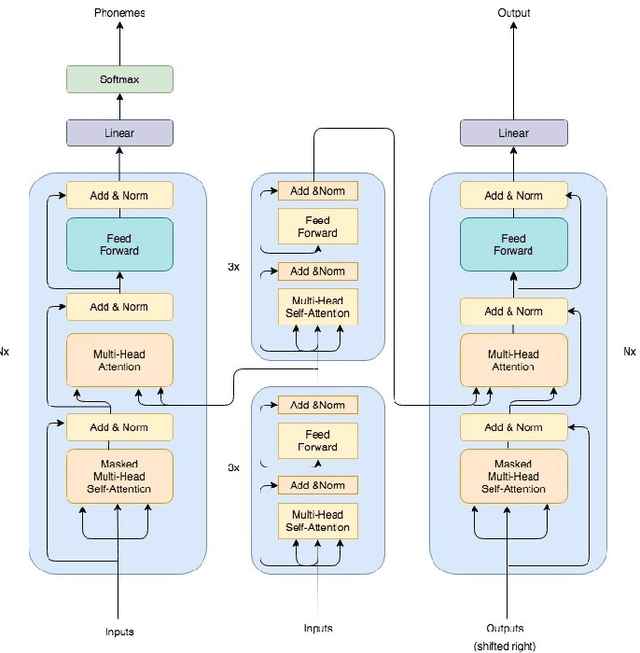
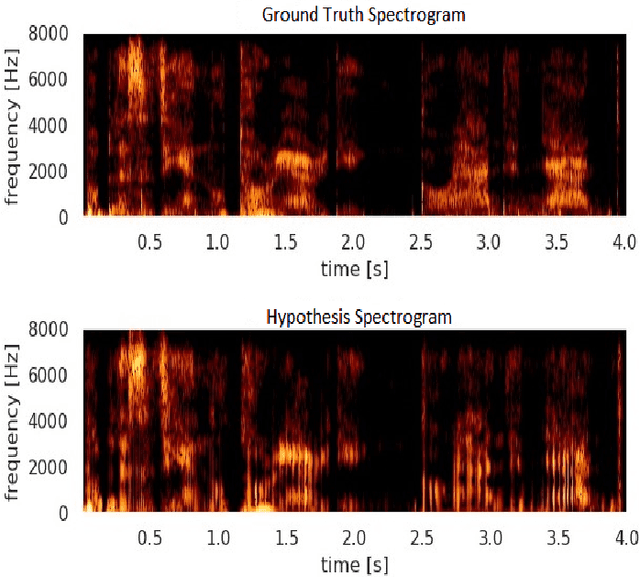
In this article, we investigate whispered-to natural-speech conversion method using sequence to sequence generation approach by proposing modified transformer architecture. We investigate different kinds of features such as mel frequency cepstral coefficients (MFCCs) and smoothed spectral features. The network is trained end-to-end (E2E) using supervised approach. We investigate the effectiveness of embedded auxillary decoder used after N encoder sub-layers, and is trained with the frame level objective function for identifying source phoneme labels. We predict target audio features and generate audio using these for testing. We test on standard wTIMIT dataset and CHAINS dataset. We report results as word-error-rate (WER) generated by using automatic speech recognition (ASR) system and also BLEU scores. %intelligibility and naturalness using mean opinion score and additionally using word error rate using automatic speech recognition system. In addition, we measure spectral shape of an output speech signal by measuring formant distributions w.r.t the reference speech signal, at frame level. In relation to this aspect, we also found that the whispered-to-natural converted speech formants probability distribution is closer to ground truth distribution. To the authors' best knowledge, this is the first time transformer with auxiliary decoder has been applied for whispered-to-natural speech conversion. [This pdf is TASLP submission draft version 1.0, 14th April 2020.]
GestureLens: Visual Analysis of Gestures in Presentation Videos
Apr 23, 2022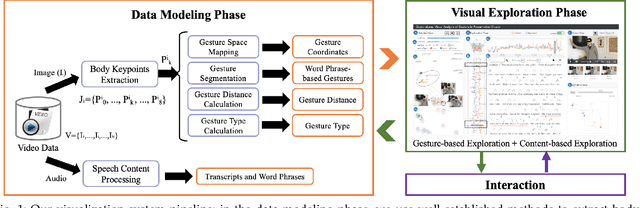
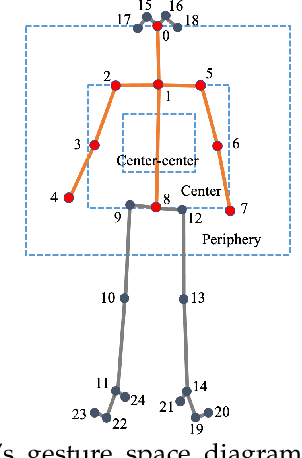
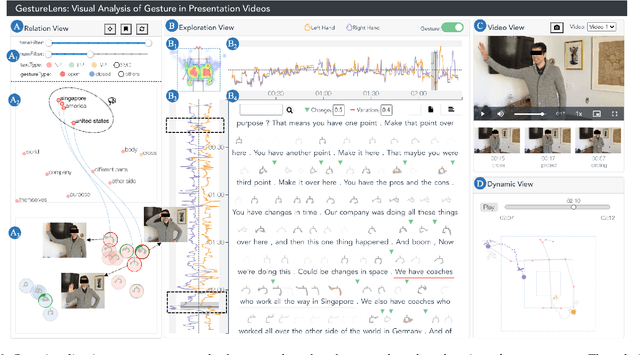
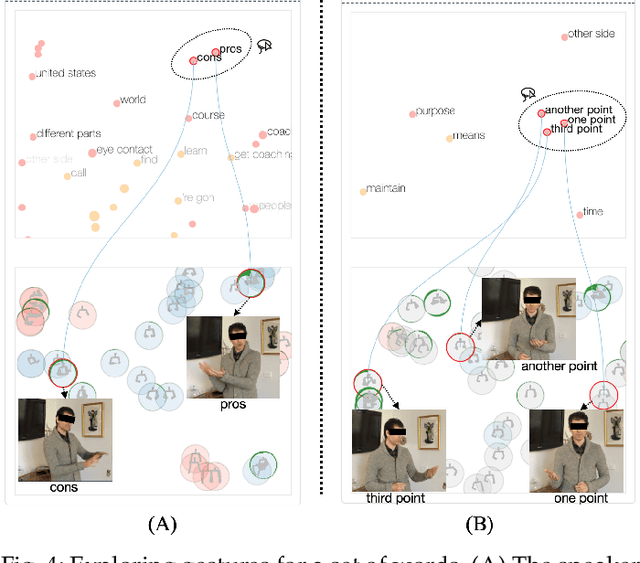
Appropriate gestures can enhance message delivery and audience engagement in both daily communication and public presentations. In this paper, we contribute a visual analytic approach that assists professional public speaking coaches in improving their practice of gesture training through analyzing presentation videos. Manually checking and exploring gesture usage in the presentation videos is often tedious and time-consuming. There lacks an efficient method to help users conduct gesture exploration, which is challenging due to the intrinsically temporal evolution of gestures and their complex correlation to speech content. In this paper, we propose GestureLens, a visual analytics system to facilitate gesture-based and content-based exploration of gesture usage in presentation videos. Specifically, the exploration view enables users to obtain a quick overview of the spatial and temporal distributions of gestures. The dynamic hand movements are firstly aggregated through a heatmap in the gesture space for uncovering spatial patterns, and then decomposed into two mutually perpendicular timelines for revealing temporal patterns. The relation view allows users to explicitly explore the correlation between speech content and gestures by enabling linked analysis and intuitive glyph designs. The video view and dynamic view show the context and overall dynamic movement of the selected gestures, respectively. Two usage scenarios and expert interviews with professional presentation coaches demonstrate the effectiveness and usefulness of GestureLens in facilitating gesture exploration and analysis of presentation videos.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jul 08, 2021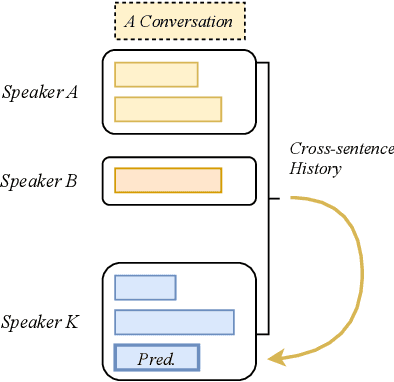
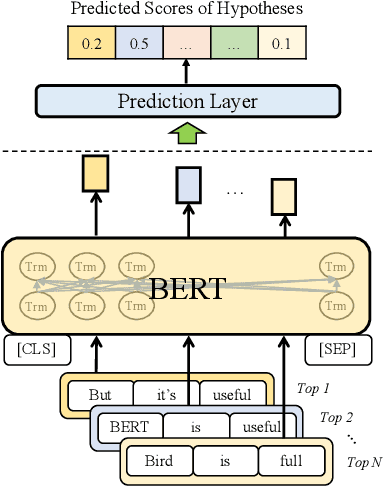
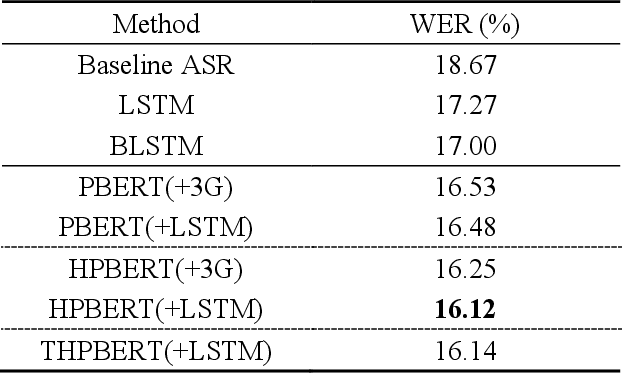
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Jointly Fine-Tuning "BERT-like" Self Supervised Models to Improve Multimodal Speech Emotion Recognition
Aug 15, 2020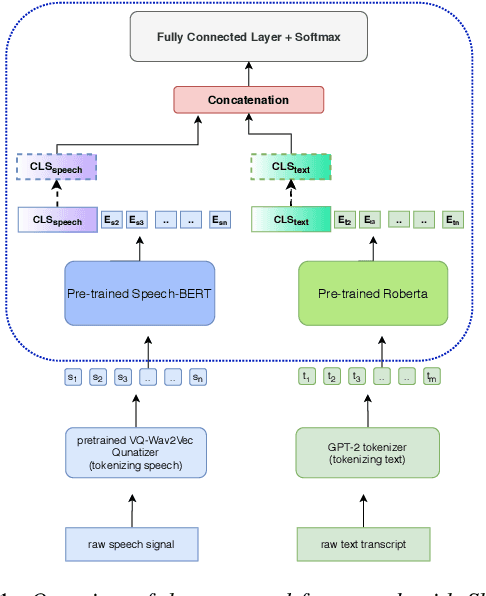
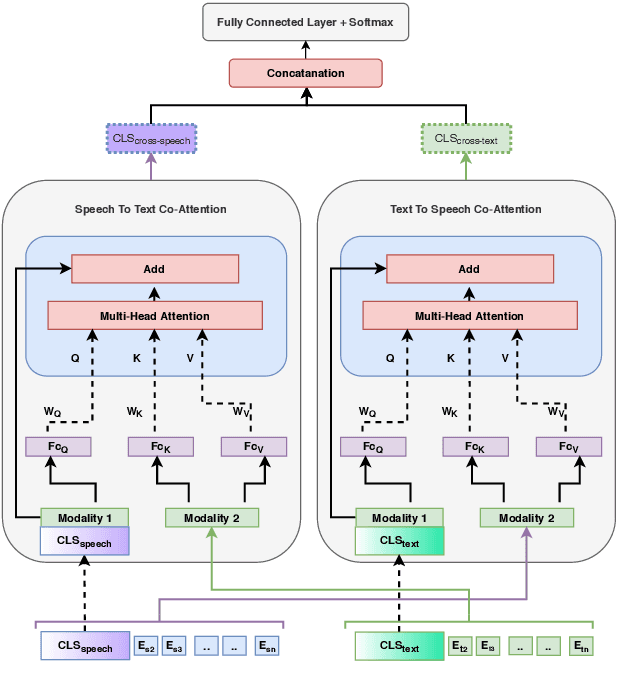
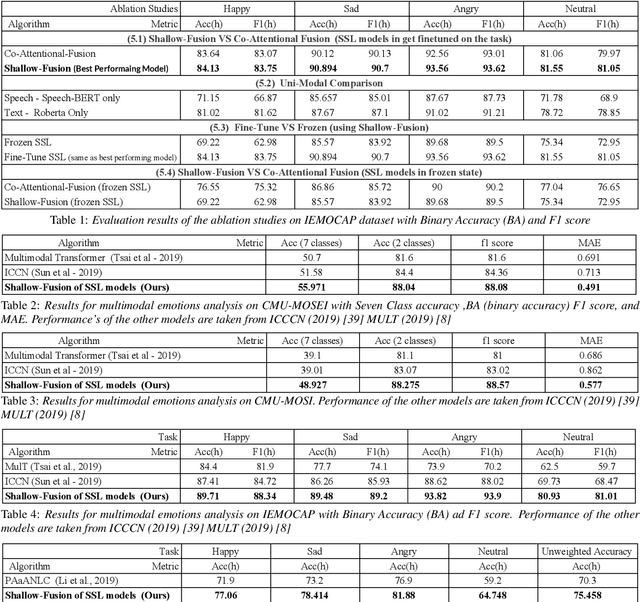
Multimodal emotion recognition from speech is an important area in affective computing. Fusing multiple data modalities and learning representations with limited amounts of labeled data is a challenging task. In this paper, we explore the use of modality-specific "BERT-like" pretrained Self Supervised Learning (SSL) architectures to represent both speech and text modalities for the task of multimodal speech emotion recognition. By conducting experiments on three publicly available datasets (IEMOCAP, CMU-MOSEI, and CMU-MOSI), we show that jointly fine-tuning "BERT-like" SSL architectures achieve state-of-the-art (SOTA) results. We also evaluate two methods of fusing speech and text modalities and show that a simple fusion mechanism can outperform more complex ones when using SSL models that have similar architectural properties to BERT.
Speech Paralinguistic Approach for Detecting Dementia Using Gated Convolutional Neural Network
Apr 16, 2020

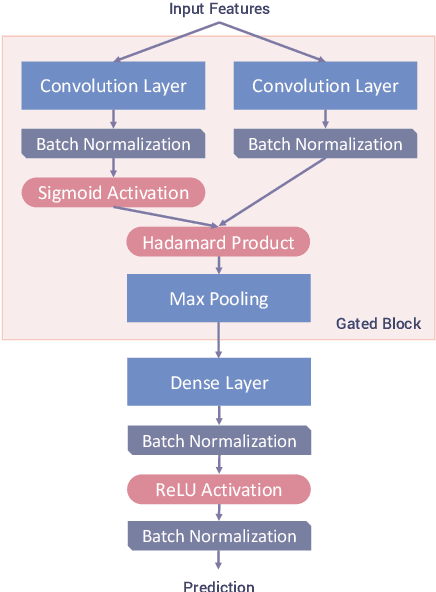
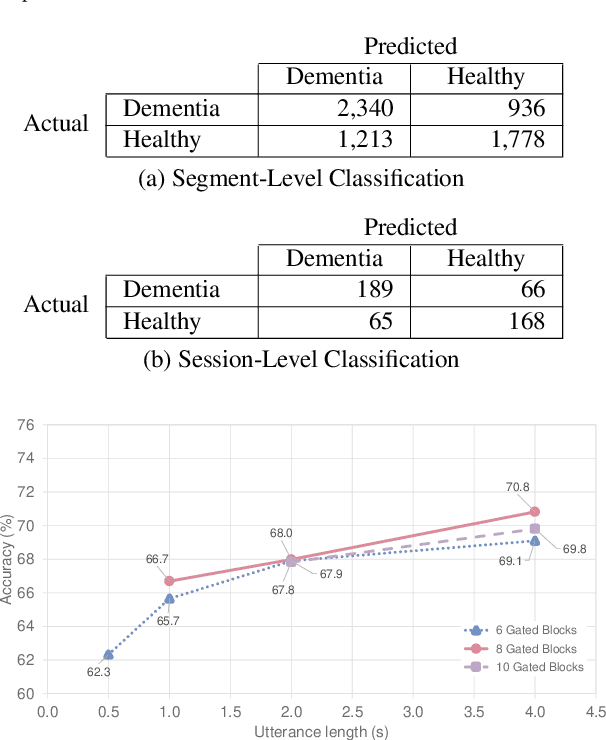
We propose a non-invasive and cost-effective method to automatically detect dementia by utilizing solely speech audio data without any linguistic features. We extract paralinguistic features for a short speech utterance segment and use Gated Convolutional Neural Networks (GCNN) to classify it into dementia or healthy. We evaluate our method by using the Pitt Corpus and our own dataset, the PROMPT Database. Our method yields the accuracy of 73.1% on the Pitt Corpus using an average of 114 seconds of speech data. In the PROMPT Database, our method yields the accuracy of 74.7% using 4 seconds of speech data and it improves to 79.0% when we use 5 minutes of speech data. Furthermore, we evaluate our method on a three-class classification problem in which we included the Mild Cognitive Impairment (MCI) class and achieved the accuracy of 60.6%.