 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling by Showing: i-Mimic: A Video-based Method to Control Robotic Arms
Jan 27, 2021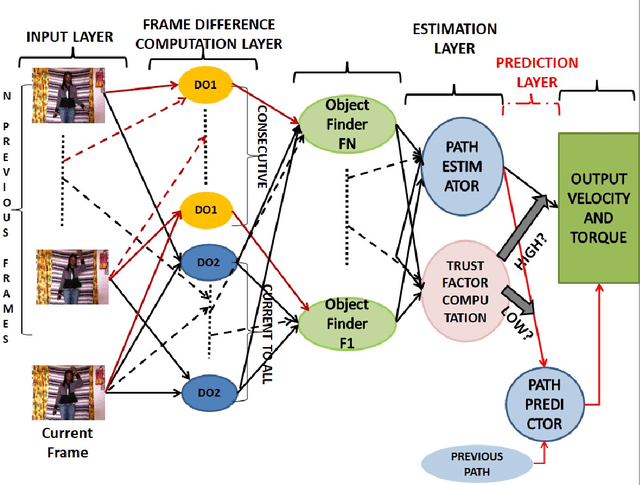

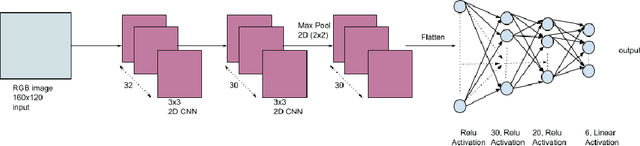
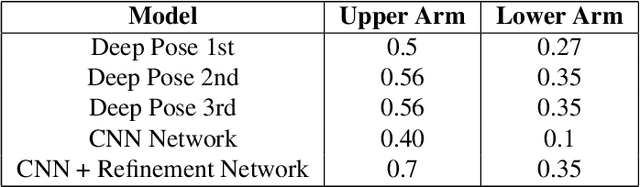
A novel concept of vision-based intelligent control of robotic arms is developed here in this work. This work enables the controlling of robotic arms motion only with visual inputs, that is, controlling by showing the videos of correct movements. This work can broadly be sub-divided into two segments. The first part of this work is to develop an unsupervised vision-based method to control robotic arm in 2-D plane, and the second one is with deep CNN in the same task in 3-D plane. The first method is unsupervised, where our aim is to perform mimicking of human arm motion in real-time by a manipulator. We developed a network, namely the vision-to-motion optical network (DON), where the input should be a video stream containing hand movements of human, the the output would be out the velocity and torque information of the hand movements shown in the videos. The output information of the DON is then fed to the robotic arm by enabling it to generate motion according to the real hand videos. The method has been tested with both live-stream video feed as well as on recorded video obtained from a monocular camera even by intelligently predicting the trajectory of human hand hand when it gets occluded. This is why the mimicry of the arm incorporates some intelligence to it and becomes intelligent mimic (i-mimic). Alongside the unsupervised method another method has also been developed deploying the deep neural network technique with CNN (Convolutional Neural Network) to perform the mimicking, where labelled datasets are used for training. The same dataset, as used in the unsupervised DON-based method, is used in the deep CNN method, after manual annotations. Both the proposed methods are validated with off-line as well as with on-line video datasets in real-time. The entire methodology is validated with real-time 1-link and simulated n-link manipulators alongwith suitable comparisons.
WHALETRANS: E2E WHisper to nAturaL spEech conversion using modified TRANSformer network
Apr 20, 2020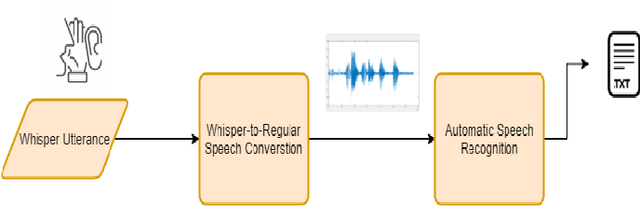
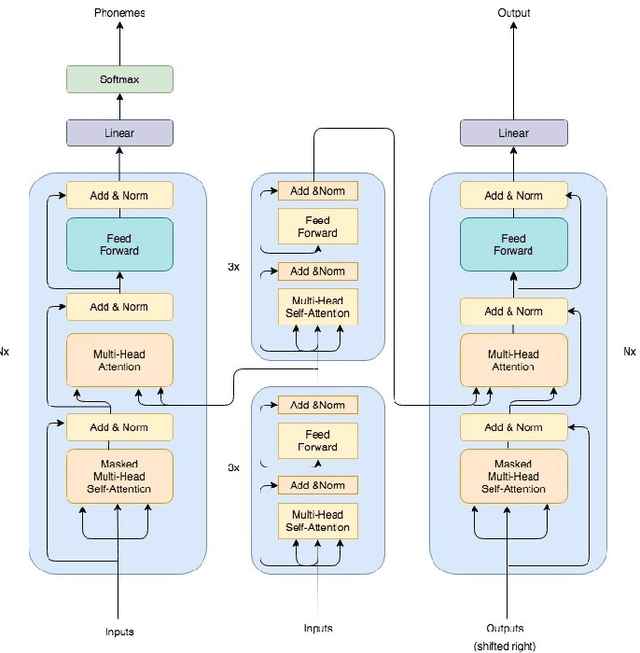
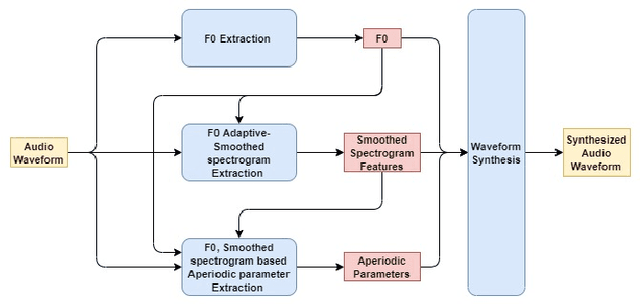
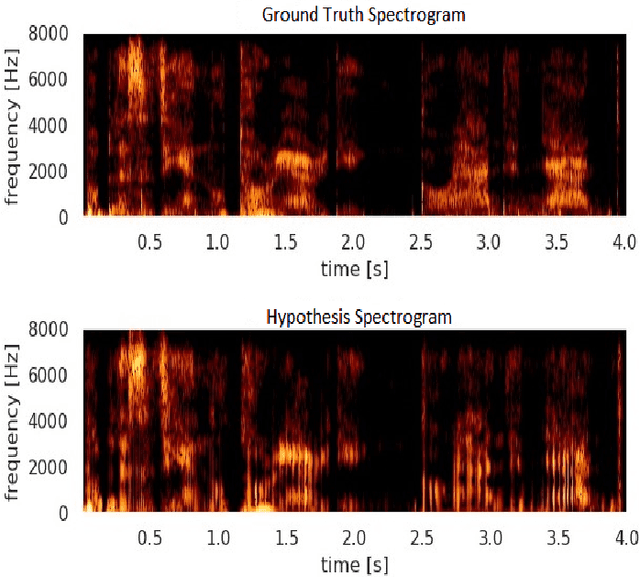
In this article, we investigate whispered-to natural-speech conversion method using sequence to sequence generation approach by proposing modified transformer architecture. We investigate different kinds of features such as mel frequency cepstral coefficients (MFCCs) and smoothed spectral features. The network is trained end-to-end (E2E) using supervised approach. We investigate the effectiveness of embedded auxillary decoder used after N encoder sub-layers, and is trained with the frame level objective function for identifying source phoneme labels. We predict target audio features and generate audio using these for testing. We test on standard wTIMIT dataset and CHAINS dataset. We report results as word-error-rate (WER) generated by using automatic speech recognition (ASR) system and also BLEU scores. %intelligibility and naturalness using mean opinion score and additionally using word error rate using automatic speech recognition system. In addition, we measure spectral shape of an output speech signal by measuring formant distributions w.r.t the reference speech signal, at frame level. In relation to this aspect, we also found that the whispered-to-natural converted speech formants probability distribution is closer to ground truth distribution. To the authors' best knowledge, this is the first time transformer with auxiliary decoder has been applied for whispered-to-natural speech conversion. [This pdf is TASLP submission draft version 1.0, 14th April 2020.]