 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMode-Seeking for Inverse Problems with Diffusion Models
Dec 11, 2025A pre-trained unconditional diffusion model, combined with posterior sampling or maximum a posteriori (MAP) estimation techniques, can solve arbitrary inverse problems without task-specific training or fine-tuning. However, existing posterior sampling and MAP estimation methods often rely on modeling approximations and can be computationally demanding. In this work, we propose the variational mode-seeking loss (VML), which, when minimized during each reverse diffusion step, guides the generated sample towards the MAP estimate. VML arises from a novel perspective of minimizing the Kullback-Leibler (KL) divergence between the diffusion posterior $p(\mathbf{x}_0|\mathbf{x}_t)$ and the measurement posterior $p(\mathbf{x}_0|\mathbf{y})$, where $\mathbf{y}$ denotes the measurement. Importantly, for linear inverse problems, VML can be analytically derived and need not be approximated. Based on further theoretical insights, we propose VML-MAP, an empirically effective algorithm for solving inverse problems, and validate its efficacy over existing methods in both performance and computational time, through extensive experiments on diverse image-restoration tasks across multiple datasets.
WHALETRANS: E2E WHisper to nAturaL spEech conversion using modified TRANSformer network
Apr 20, 2020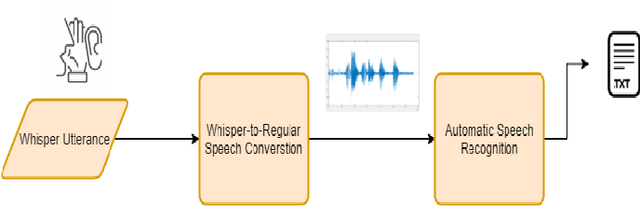
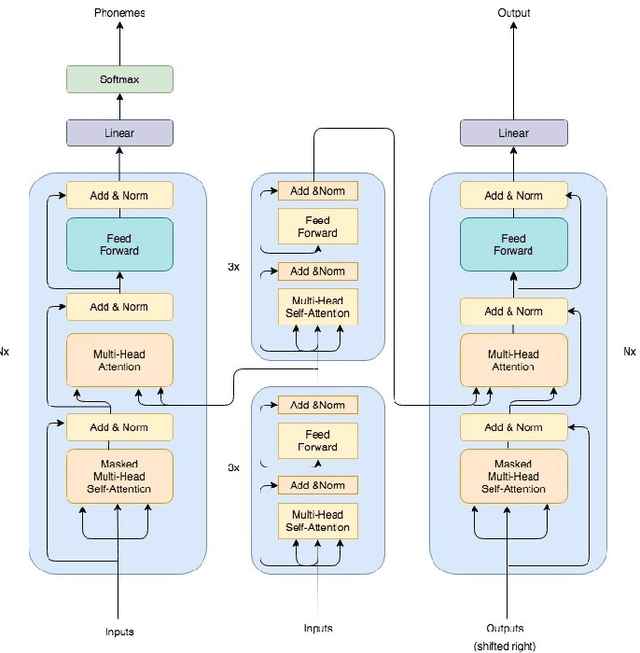
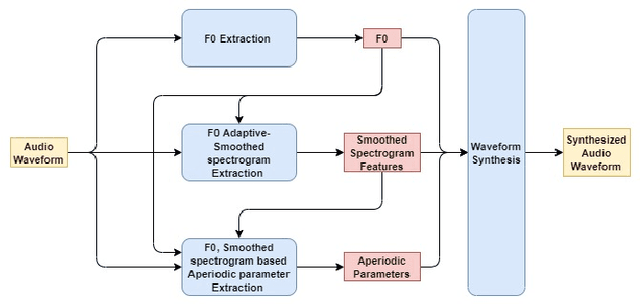
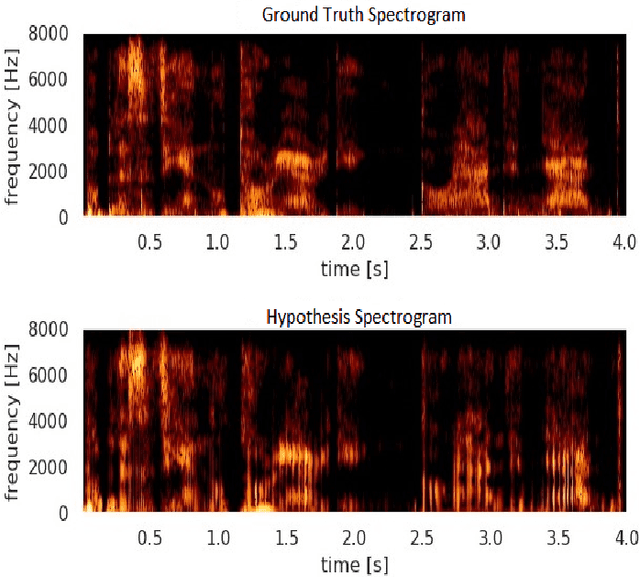
In this article, we investigate whispered-to natural-speech conversion method using sequence to sequence generation approach by proposing modified transformer architecture. We investigate different kinds of features such as mel frequency cepstral coefficients (MFCCs) and smoothed spectral features. The network is trained end-to-end (E2E) using supervised approach. We investigate the effectiveness of embedded auxillary decoder used after N encoder sub-layers, and is trained with the frame level objective function for identifying source phoneme labels. We predict target audio features and generate audio using these for testing. We test on standard wTIMIT dataset and CHAINS dataset. We report results as word-error-rate (WER) generated by using automatic speech recognition (ASR) system and also BLEU scores. %intelligibility and naturalness using mean opinion score and additionally using word error rate using automatic speech recognition system. In addition, we measure spectral shape of an output speech signal by measuring formant distributions w.r.t the reference speech signal, at frame level. In relation to this aspect, we also found that the whispered-to-natural converted speech formants probability distribution is closer to ground truth distribution. To the authors' best knowledge, this is the first time transformer with auxiliary decoder has been applied for whispered-to-natural speech conversion. [This pdf is TASLP submission draft version 1.0, 14th April 2020.]