 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Attention Transformer Architecture For Syntactic Spell Correction
May 11, 2020
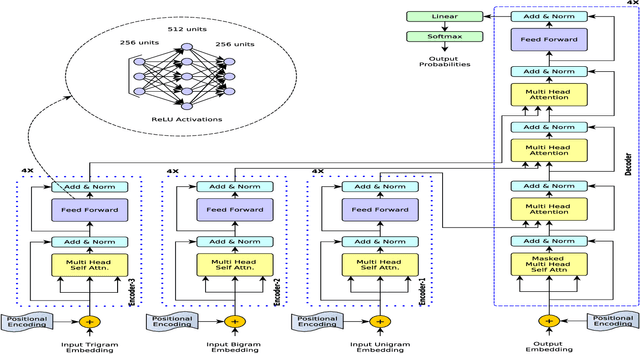

The attention mechanisms are playing a boosting role in advancements in sequence-to-sequence problems. Transformer architecture achieved new state of the art results in machine translation, and it's variants are since being introduced in several other sequence-to-sequence problems. Problems which involve a shared vocabulary, can benefit from the similar semantic and syntactic structure in the source and target sentences. With the motivation of building a reliable and fast post-processing textual module to assist all the text-related use cases in mobile phones, we take on the popular spell correction problem. In this paper, we propose multi encoder-single decoder variation of conventional transformer. Outputs from the three encoders with character level 1-gram, 2-grams and 3-grams inputs are attended in hierarchical fashion in the decoder. The context vectors from the encoders clubbed with self-attention amplify the n-gram properties at the character level and helps in accurate decoding. We demonstrate our model on spell correction dataset from Samsung Research, and report significant improvement of 0.11\%, 0.32\% and 0.69\% in character (CER), word (WER) and sentence (SER) error rates from existing state-of-the-art machine-translation architectures. Our architecture is also trains ~7.8 times faster, and is only about 1/3 in size from the next most accurate model.
WHALETRANS: E2E WHisper to nAturaL spEech conversion using modified TRANSformer network
Apr 20, 2020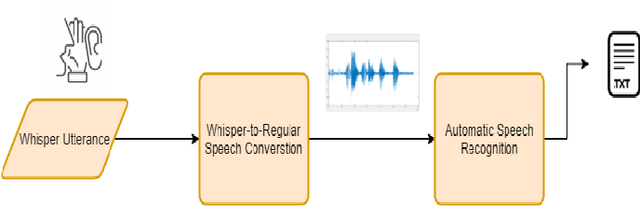
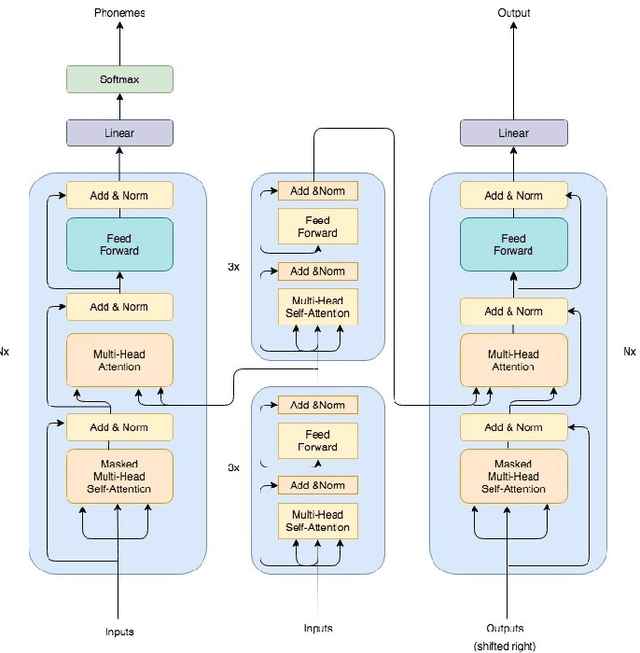
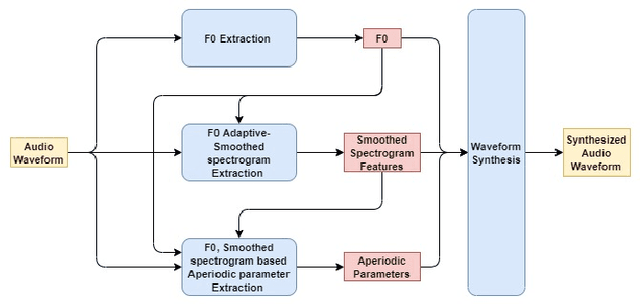
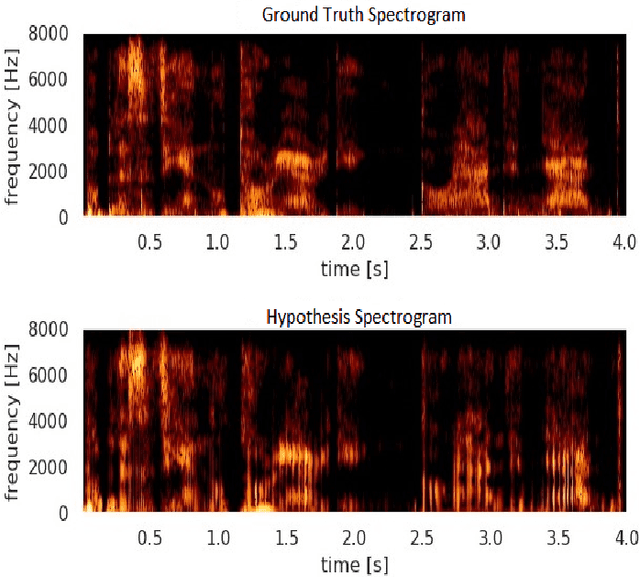
In this article, we investigate whispered-to natural-speech conversion method using sequence to sequence generation approach by proposing modified transformer architecture. We investigate different kinds of features such as mel frequency cepstral coefficients (MFCCs) and smoothed spectral features. The network is trained end-to-end (E2E) using supervised approach. We investigate the effectiveness of embedded auxillary decoder used after N encoder sub-layers, and is trained with the frame level objective function for identifying source phoneme labels. We predict target audio features and generate audio using these for testing. We test on standard wTIMIT dataset and CHAINS dataset. We report results as word-error-rate (WER) generated by using automatic speech recognition (ASR) system and also BLEU scores. %intelligibility and naturalness using mean opinion score and additionally using word error rate using automatic speech recognition system. In addition, we measure spectral shape of an output speech signal by measuring formant distributions w.r.t the reference speech signal, at frame level. In relation to this aspect, we also found that the whispered-to-natural converted speech formants probability distribution is closer to ground truth distribution. To the authors' best knowledge, this is the first time transformer with auxiliary decoder has been applied for whispered-to-natural speech conversion. [This pdf is TASLP submission draft version 1.0, 14th April 2020.]