 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Low-Latency Incremental Text-to-Speech Synthesis with Distilled Context Prediction Network
Sep 22, 2021
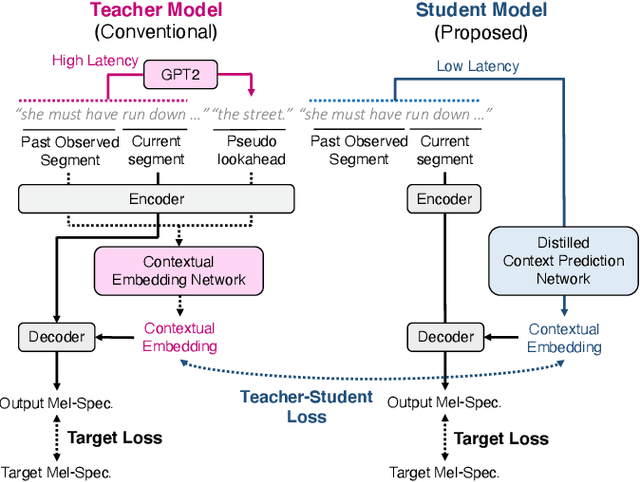
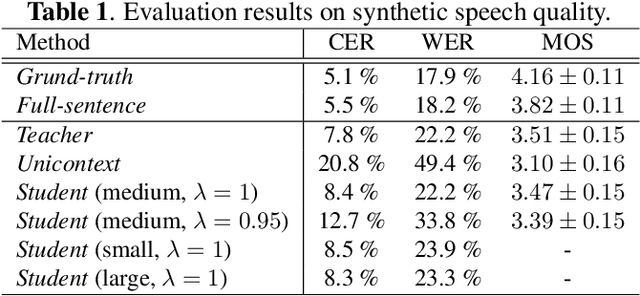

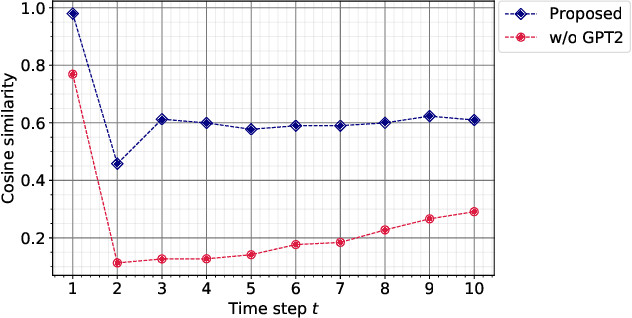
Incremental text-to-speech (TTS) synthesis generates utterances in small linguistic units for the sake of real-time and low-latency applications. We previously proposed an incremental TTS method that leverages a large pre-trained language model to take unobserved future context into account without waiting for the subsequent segment. Although this method achieves comparable speech quality to that of a method that waits for the future context, it entails a huge amount of processing for sampling from the language model at each time step. In this paper, we propose an incremental TTS method that directly predicts the unobserved future context with a lightweight model, instead of sampling words from the large-scale language model. We perform knowledge distillation from a GPT2-based context prediction network into a simple recurrent model by minimizing a teacher-student loss defined between the context embedding vectors of those models. Experimental results show that the proposed method requires about ten times less inference time to achieve comparable synthetic speech quality to that of our previous method, and it can perform incremental synthesis much faster than the average speaking speed of human English speakers, demonstrating the availability of our method to real-time applications.
An Improved Model for Voicing Silent Speech
Jun 21, 2021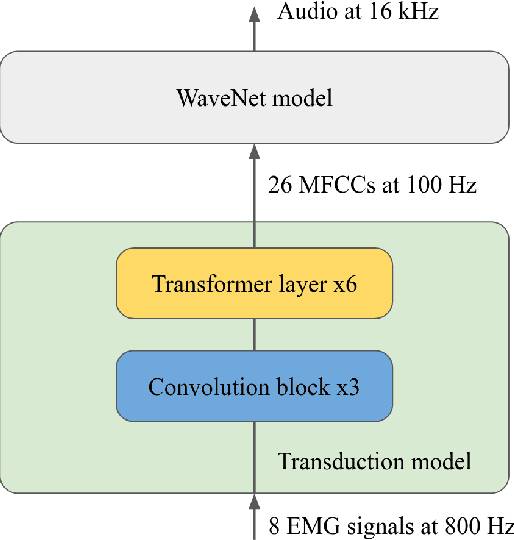

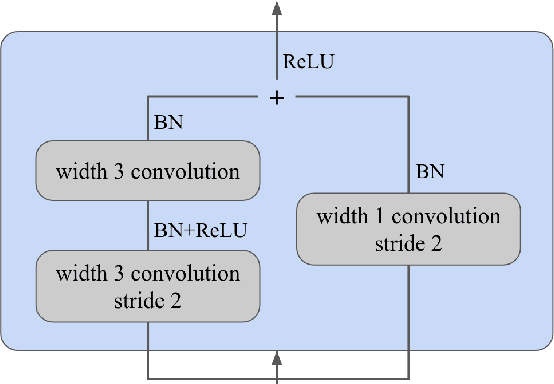
In this paper, we present an improved model for voicing silent speech, where audio is synthesized from facial electromyography (EMG) signals. To give our model greater flexibility to learn its own input features, we directly use EMG signals as input in the place of hand-designed features used by prior work. Our model uses convolutional layers to extract features from the signals and Transformer layers to propagate information across longer distances. To provide better signal for learning, we also introduce an auxiliary task of predicting phoneme labels in addition to predicting speech audio features. On an open vocabulary intelligibility evaluation, our model improves the state of the art for this task by an absolute 25.8%.
Speech Recognition with Augmented Synthesized Speech
Sep 25, 2019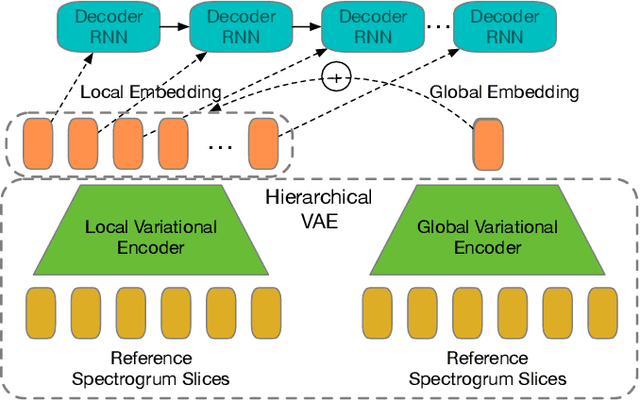
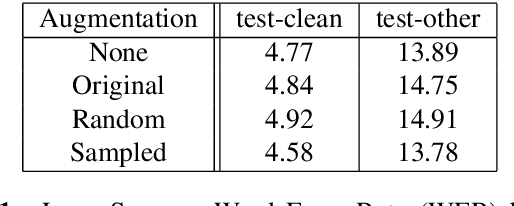
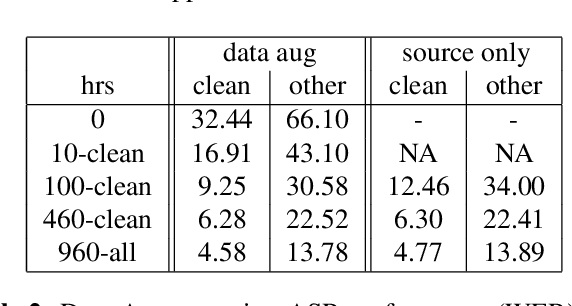
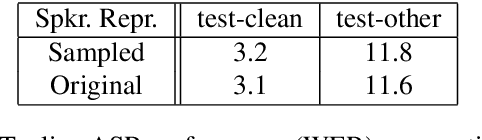
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.
WARP-Q: Quality Prediction For Generative Neural Speech Codecs
Feb 20, 2021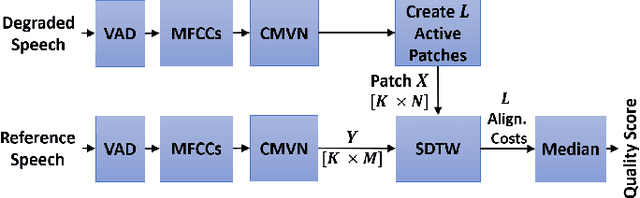

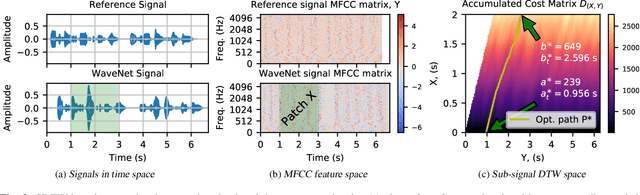
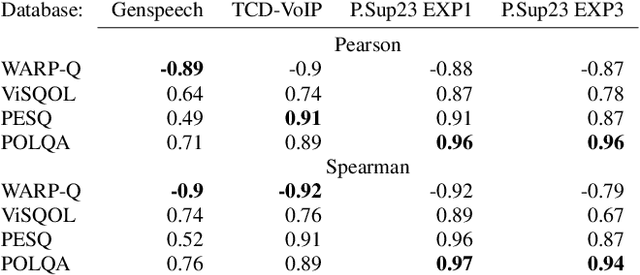
Good speech quality has been achieved using waveform matching and parametric reconstruction coders. Recently developed very low bit rate generative codecs can reconstruct high quality wideband speech with bit streams less than 3 kb/s. These codecs use a DNN with parametric input to synthesise high quality speech outputs. Existing objective speech quality models (e.g., POLQA, ViSQOL) do not accurately predict the quality of coded speech from these generative models underestimating quality due to signal differences not highlighted in subjective listening tests. We present WARP-Q, a full-reference objective speech quality metric that uses dynamic time warping cost for MFCC speech representations. It is robust to small perceptual signal changes. Evaluation using waveform matching, parametric and generative neural vocoder based codecs as well as channel and environmental noise shows that WARP-Q has better correlation and codec quality ranking for novel codecs compared to traditional metrics in addition to versatility for general quality assessment scenarios.
Detection of Consonant Errors in Disordered Speech Based on Consonant-vowel Segment Embedding
Jun 16, 2021
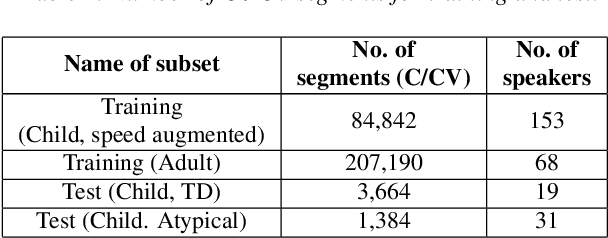

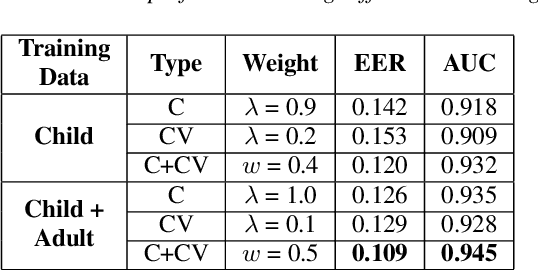
Speech sound disorder (SSD) refers to a type of developmental disorder in young children who encounter persistent difficulties in producing certain speech sounds at the expected age. Consonant errors are the major indicator of SSD in clinical assessment. Previous studies on automatic assessment of SSD revealed that detection of speech errors concerning short and transitory consonants is less satisfactory. This paper investigates a neural network based approach to detecting consonant errors in disordered speech using consonant-vowel (CV) diphone segment in comparison to using consonant monophone segment. The underlying assumption is that the vowel part of a CV segment carries important information of co-articulation from the consonant. Speech embeddings are extracted from CV segments by a recurrent neural network model. The similarity scores between the embeddings of the test segment and the reference segments are computed to determine if the test segment is the expected consonant or not. Experimental results show that using CV segments achieves improved performance on detecting speech errors concerning those "difficult" consonants reported in the previous studies.
Fight Fire with Fire: Fine-tuning Hate Detectors using Large Samples of Generated Hate Speech
Sep 01, 2021
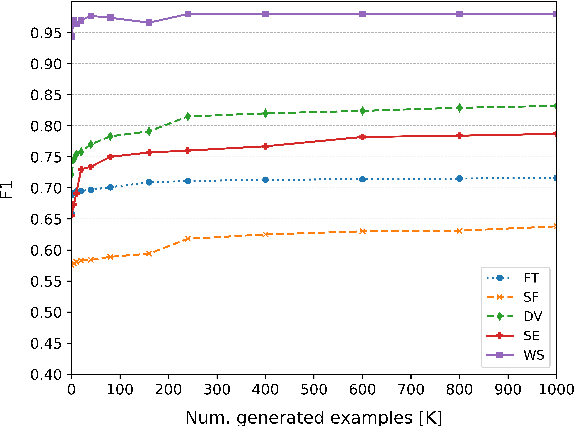
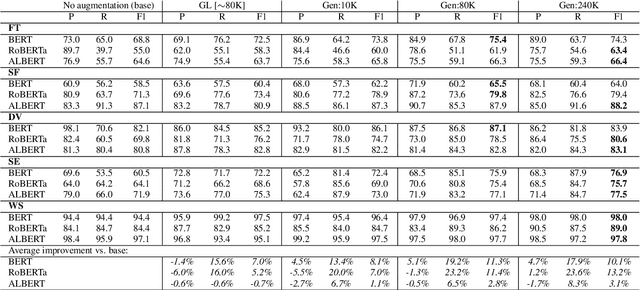
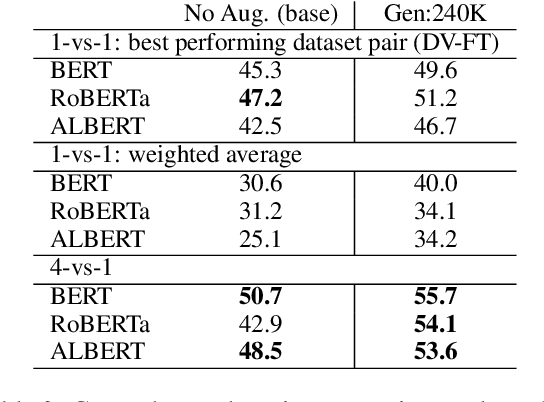
Automatic hate speech detection is hampered by the scarcity of labeled datasetd, leading to poor generalization. We employ pretrained language models (LMs) to alleviate this data bottleneck. We utilize the GPT LM for generating large amounts of synthetic hate speech sequences from available labeled examples, and leverage the generated data in fine-tuning large pretrained LMs on hate detection. An empirical study using the models of BERT, RoBERTa and ALBERT, shows that this approach improves generalization significantly and consistently within and across data distributions. In fact, we find that generating relevant labeled hate speech sequences is preferable to using out-of-domain, and sometimes also within-domain, human-labeled examples.
FullPack: Full Vector Utilization for Sub-Byte Quantized Inference on General Purpose CPUs
Nov 20, 2022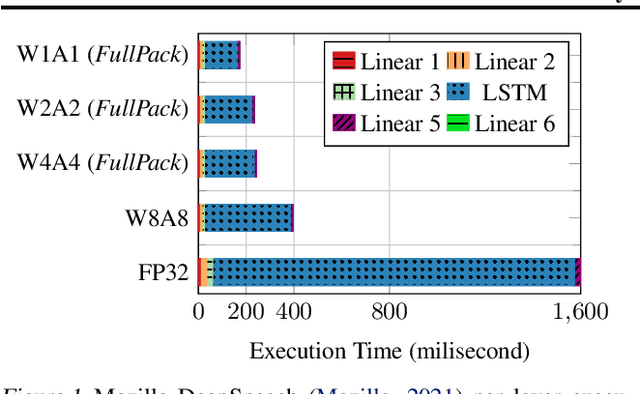
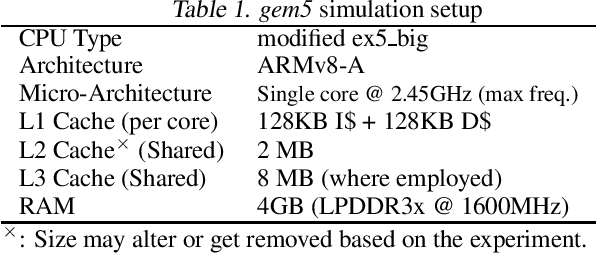
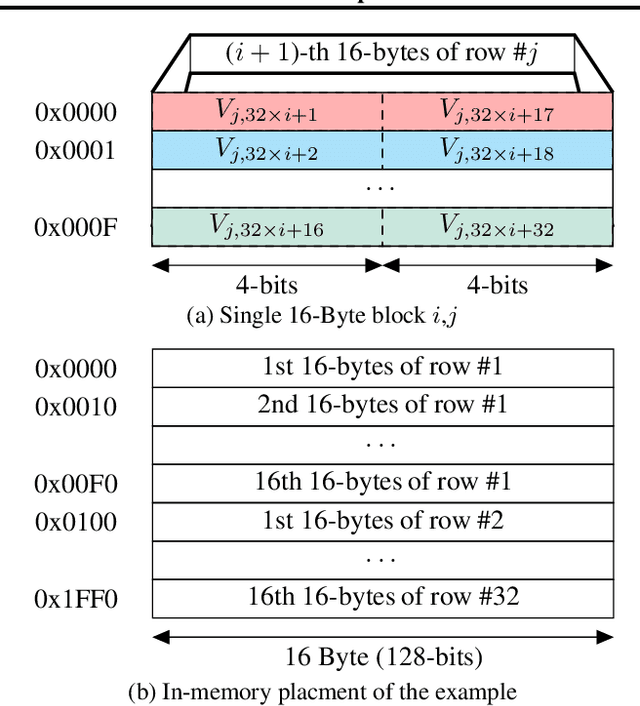

Although prior art has demonstrated negligible accuracy drop in sub-byte quantization -- where weights and/or activations are represented by less than 8 bits -- popular SIMD instructions of CPUs do not natively support these datatypes. While recent methods, such as ULPPACK, are already using sub-byte quantization on general-purpose CPUs with vector units, they leave out several empty bits between the sub-byte values in memory and in vector registers to avoid overflow to the neighbours during the operations. This results in memory footprint and bandwidth-usage inefficiencies and suboptimal performance. In this paper, we present memory layouts for storing, and mechanisms for processing sub-byte (4-, 2-, or 1-bit) models that utilize all the bits in the memory as well as in the vector registers for the actual data. We provide compute kernels for the proposed layout for the GEMV (GEneral Matrix-Vector multiplication) operations between weights and activations of different datatypes (e.g., 8-bit activations and 4-bit weights). For evaluation, we extended the TFLite package and added our methods to it, then ran the models on the cycle-accurate gem5 simulator to compare detailed memory and CPU cycles of each method. We compare against nine other methods that are actively used in production including GEMLOWP, Ruy, XNNPack, and ULPPACK. Furthermore, we explore the effect of different input and output sizes of deep learning layers on the performance of our proposed method. Experimental results show 0.96-2.1x speedup for small sizes and 1.2-6.7x speedup for mid to large sizes. Applying our proposal to a real-world speech recognition model, Mozilla DeepSpeech, we proved that our method achieves 1.56-2.11x end-to-end speedup compared to the state-of-the-art, depending on the bit-width employed.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021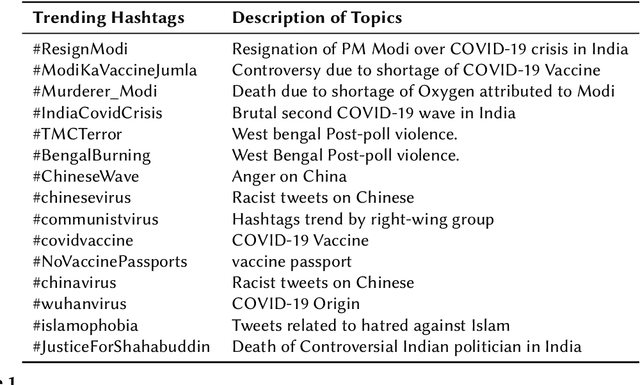
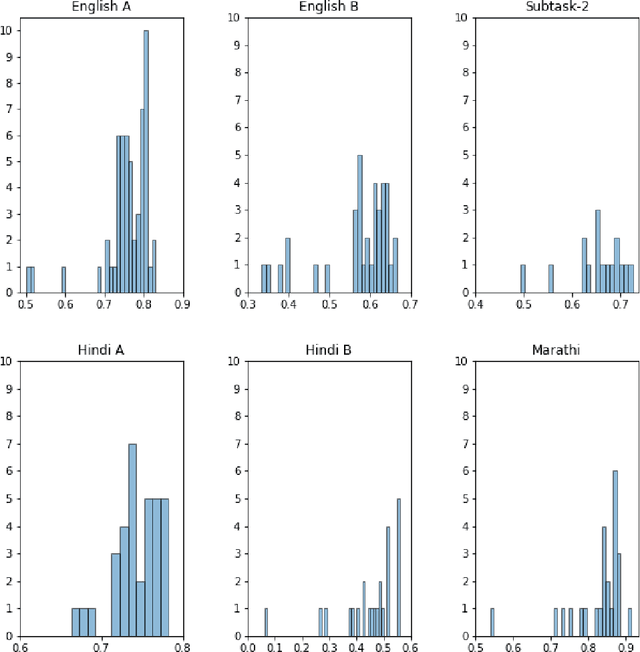
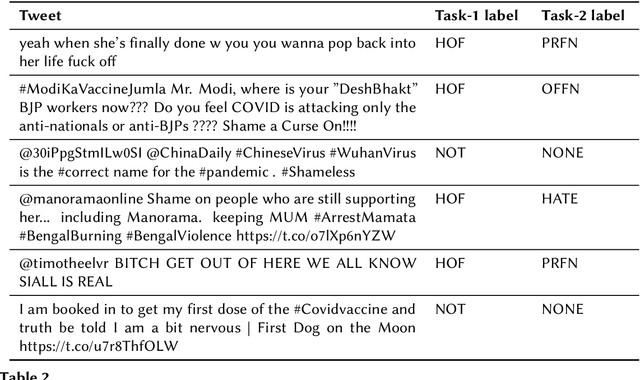

The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021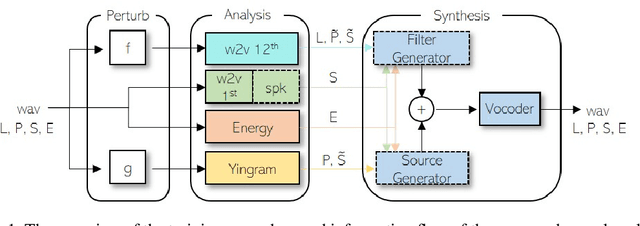

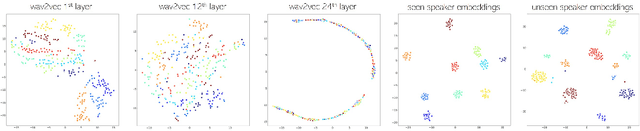
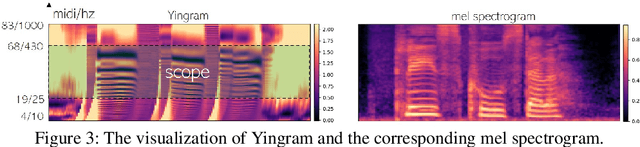
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
A Simple Baseline for Domain Adaptation in End to End ASR Systems Using Synthetic Data
Jun 22, 2022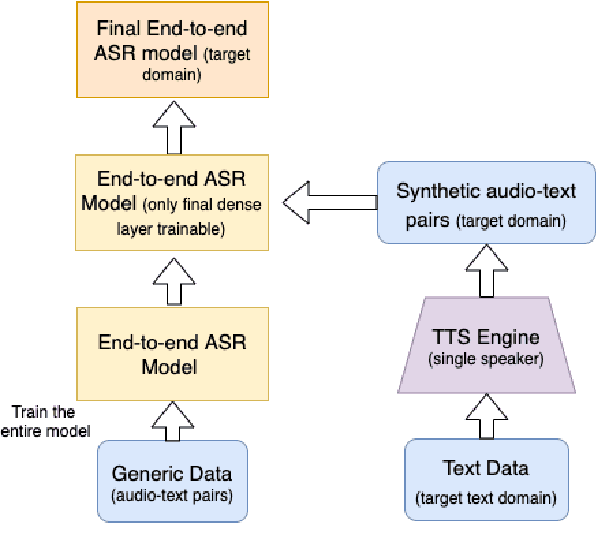
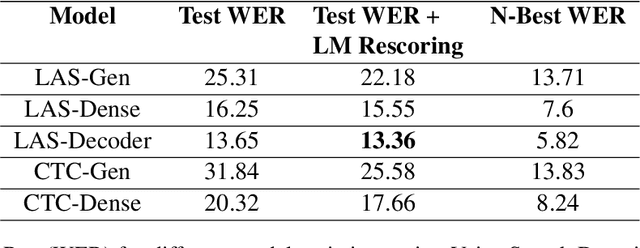
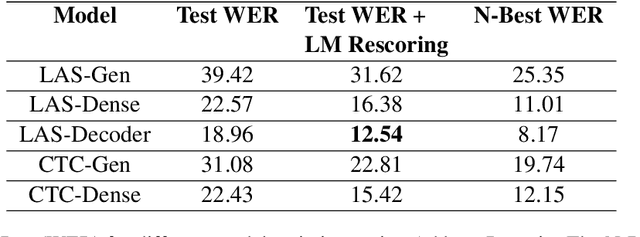
Automatic Speech Recognition(ASR) has been dominated by deep learning-based end-to-end speech recognition models. These approaches require large amounts of labeled data in the form of audio-text pairs. Moreover, these models are more susceptible to domain shift as compared to traditional models. It is common practice to train generic ASR models and then adapt them to target domains using comparatively smaller data sets. We consider a more extreme case of domain adaptation where text-only corpus is available. In this work, we propose a simple baseline technique for domain adaptation in end-to-end speech recognition models. We convert the text-only corpus to audio data using single speaker Text to Speech (TTS) engine. The parallel data in the target domain is then used to fine-tune the final dense layer of generic ASR models. We show that single speaker synthetic TTS data coupled with final dense layer only fine-tuning provides reasonable improvements in word error rates. We use text data from address and e-commerce search domains to show the effectiveness of our low-cost baseline approach on CTC and attention-based models.