 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMCodec: A Low Bitrate Speech Codec With Causal Transformer Models
Mar 23, 2023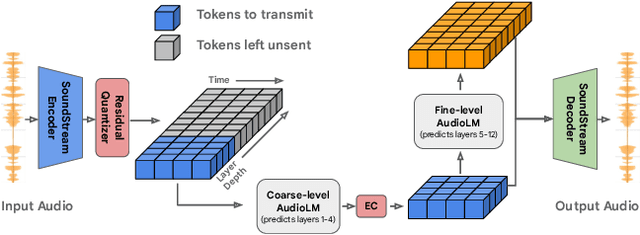
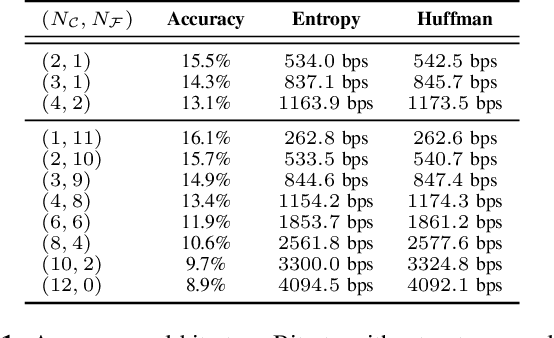
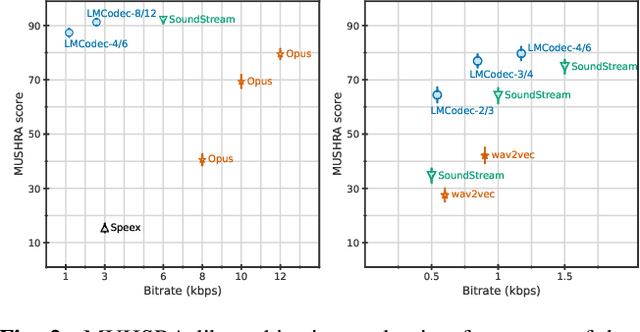
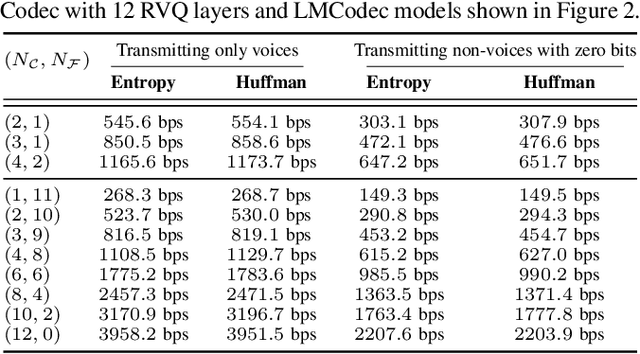
We introduce LMCodec, a causal neural speech codec that provides high quality audio at very low bitrates. The backbone of the system is a causal convolutional codec that encodes audio into a hierarchy of coarse-to-fine tokens using residual vector quantization. LMCodec trains a Transformer language model to predict the fine tokens from the coarse ones in a generative fashion, allowing for the transmission of fewer codes. A second Transformer predicts the uncertainty of the next codes given the past transmitted codes, and is used to perform conditional entropy coding. A MUSHRA subjective test was conducted and shows that the quality is comparable to reference codecs at higher bitrates. Example audio is available at https://mjenrungrot.github.io/chrome-media-audio-papers/publications/lmcodec.
Using Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Sep 14, 2022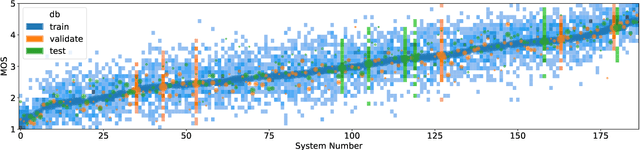
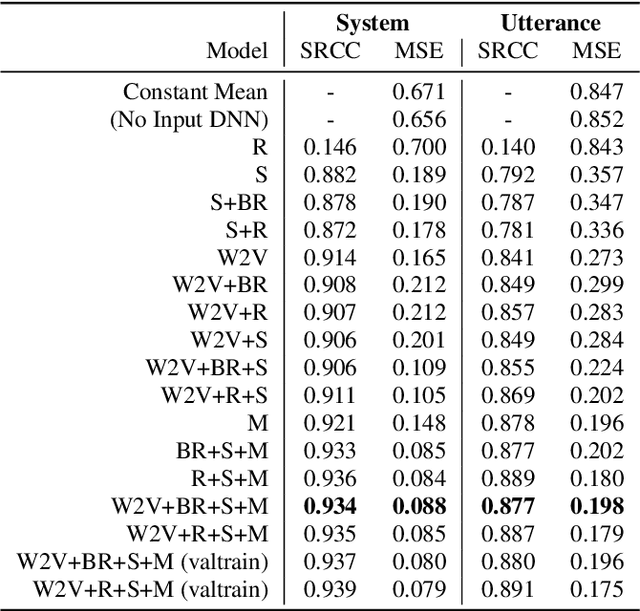
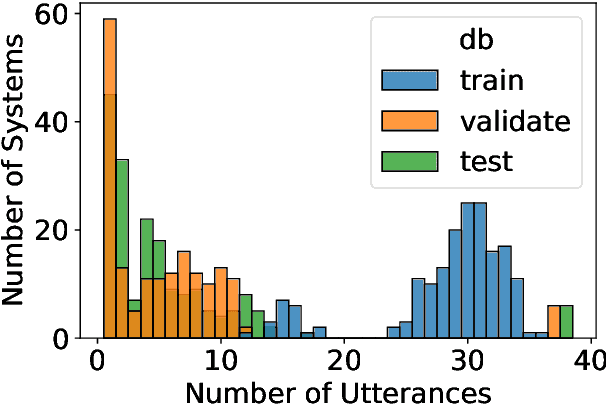
Non-reference speech quality models are important for a growing number of applications. The VoiceMOS 2022 challenge provided a dataset of synthetic voice conversion and text-to-speech samples with subjective labels. This study looks at the amount of variance that can be explained in subjective ratings of speech quality from metadata and the distribution imbalances of the dataset. Speech quality models were constructed using wav2vec 2.0 with additional metadata features that included rater groups and system identifiers and obtained competitive metrics including a Spearman rank correlation coefficient (SRCC) of 0.934 and MSE of 0.088 at the system-level, and 0.877 and 0.198 at the utterance-level. Using data and metadata that the test restricted or blinded further improved the metrics. A metadata analysis showed that the system-level metrics do not represent the model's system-level prediction as a result of the wide variation in the number of utterances used for each system on the validation and test datasets. We conclude that, in general, conditions should have enough utterances in the test set to bound the sample mean error, and be relatively balanced in utterance count between systems, otherwise the utterance-level metrics may be more reliable and interpretable.
Ultra-Low-Bitrate Speech Coding with Pretrained Transformers
Jul 05, 2022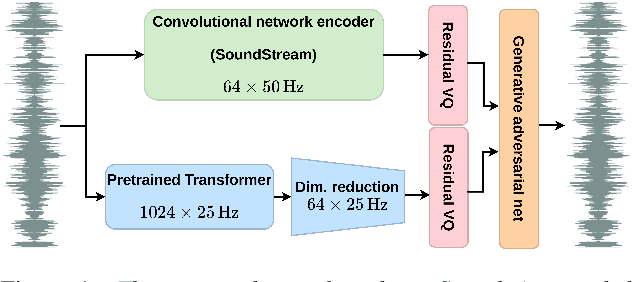
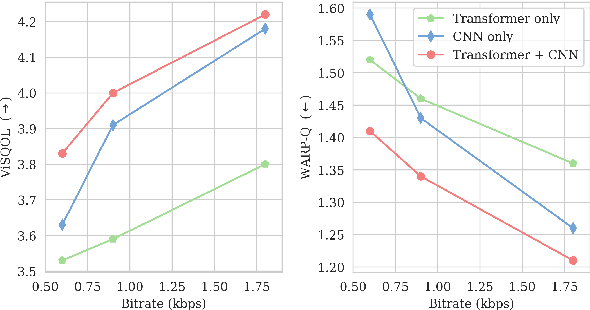
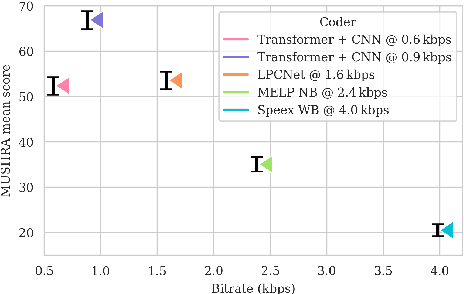
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.
A Comparison of Deep Learning MOS Predictors for Speech Synthesis Quality
Apr 05, 2022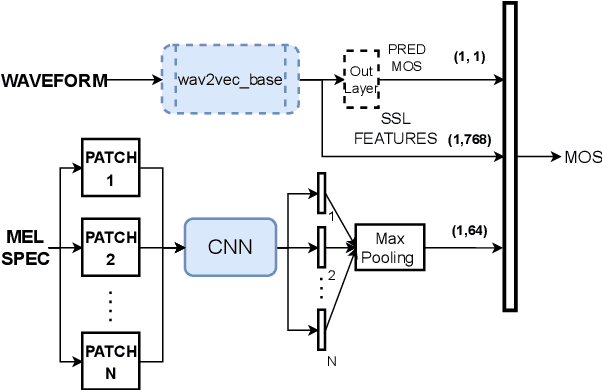
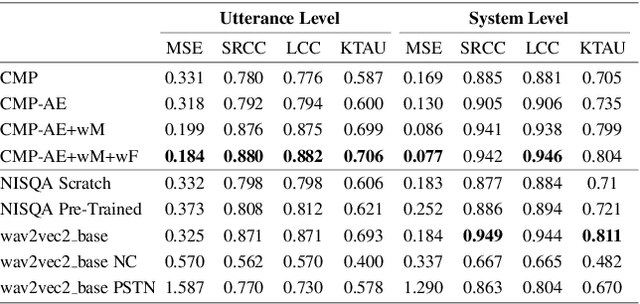
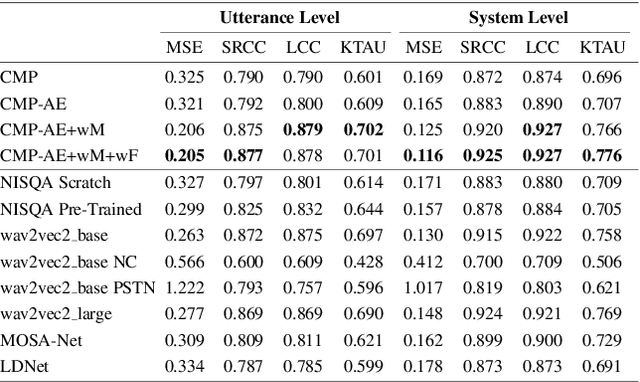
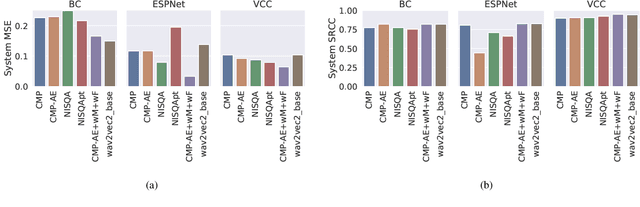
This paper introduces a comparison of deep learning-based techniques for the MOS prediction task of synthesised speech in the Interspeech VoiceMOS challenge. Using the data from the main track of the VoiceMOS challenge we explore both existing predictors and propose new ones. We evaluate two groups of models: NISQA-based models and techniques based on fine-tuning the self-supervised learning (SSL) model wav2vec2_base. Our findings show that a simplified version of NISQA with 40% fewer parameters achieves results close to the original NISQA architecture on both utterance-level and system-level performances. Pre-training NISQA with the NISQA corpus improves utterance-level performance but shows no benefit on the system-level performance. Also, the NISQA-based models perform close to LDNet and MOSANet, 2 out of 3 baselines of the challenge. Fine-tuning wav2vec2_base shows superior performance than the NISQA-based models. We explore the mismatch between natural and synthetic speech and discovered that the performance of the SSL model drops consistently when fine-tuned on natural speech samples. We show that adding CNN features with the SSL model does not improve the baseline performance. Finally, we show that the system type has an impact on the predictions of the non-SSL models.
WARP-Q: Quality Prediction For Generative Neural Speech Codecs
Feb 20, 2021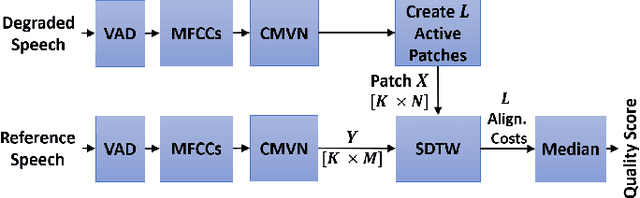

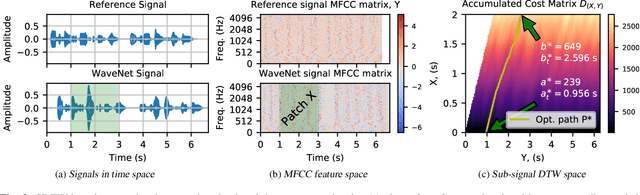
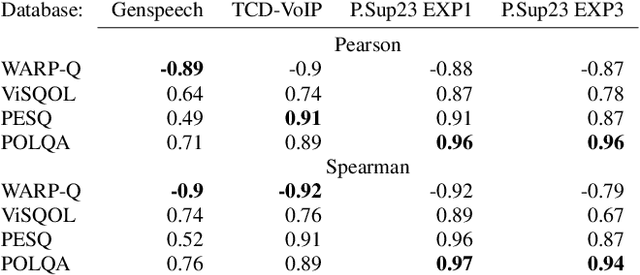
Good speech quality has been achieved using waveform matching and parametric reconstruction coders. Recently developed very low bit rate generative codecs can reconstruct high quality wideband speech with bit streams less than 3 kb/s. These codecs use a DNN with parametric input to synthesise high quality speech outputs. Existing objective speech quality models (e.g., POLQA, ViSQOL) do not accurately predict the quality of coded speech from these generative models underestimating quality due to signal differences not highlighted in subjective listening tests. We present WARP-Q, a full-reference objective speech quality metric that uses dynamic time warping cost for MFCC speech representations. It is robust to small perceptual signal changes. Evaluation using waveform matching, parametric and generative neural vocoder based codecs as well as channel and environmental noise shows that WARP-Q has better correlation and codec quality ranking for novel codecs compared to traditional metrics in addition to versatility for general quality assessment scenarios.
Generative Speech Coding with Predictive Variance Regularization
Feb 18, 2021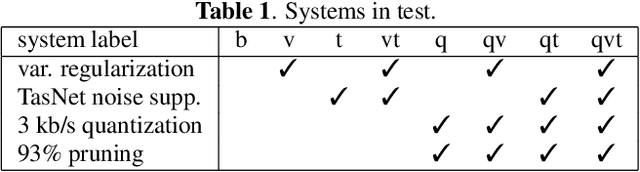
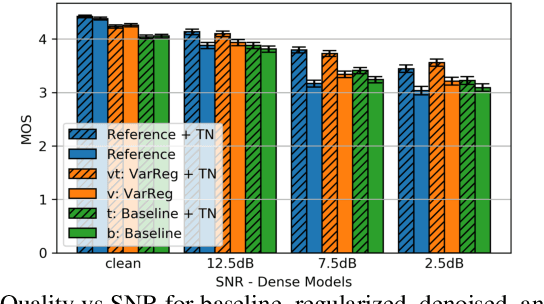
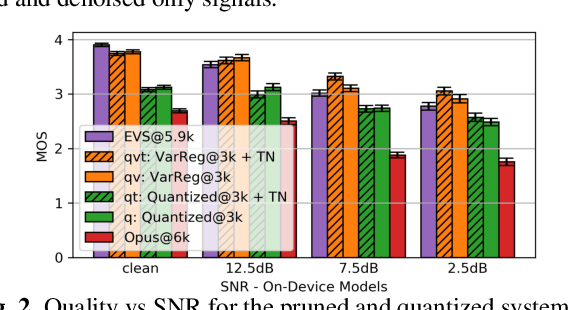
The recent emergence of machine-learning based generative models for speech suggests a significant reduction in bit rate for speech codecs is possible. However, the performance of generative models deteriorates significantly with the distortions present in real-world input signals. We argue that this deterioration is due to the sensitivity of the maximum likelihood criterion to outliers and the ineffectiveness of modeling a sum of independent signals with a single autoregressive model. We introduce predictive-variance regularization to reduce the sensitivity to outliers, resulting in a significant increase in performance. We show that noise reduction to remove unwanted signals can significantly increase performance. We provide extensive subjective performance evaluations that show that our system based on generative modeling provides state-of-the-art coding performance at 3 kb/s for real-world speech signals at reasonable computational complexity.