 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA TRRIP Down Memory Lane: Temperature-Based Re-Reference Interval Prediction For Instruction Caching
Sep 17, 2025Modern mobile CPU software pose challenges for conventional instruction cache replacement policies due to their complex runtime behavior causing high reuse distance between executions of the same instruction. Mobile code commonly suffers from large amounts of stalls in the CPU frontend and thus starvation of the rest of the CPU resources. Complexity of these applications and their code footprint are projected to grow at a rate faster than available on-chip memory due to power and area constraints, making conventional hardware-centric methods for managing instruction caches to be inadequate. We present a novel software-hardware co-design approach called TRRIP (Temperature-based Re-Reference Interval Prediction) that enables the compiler to analyze, classify, and transform code based on "temperature" (hot/cold), and to provide the hardware with a summary of code temperature information through a well-defined OS interface based on using code page attributes. TRRIP's lightweight hardware extension employs code temperature attributes to optimize the instruction cache replacement policy resulting in the eviction rate reduction of hot code. TRRIP is designed to be practical and adoptable in real mobile systems that have strict feature requirements on both the software and hardware components. TRRIP can reduce the L2 MPKI for instructions by 26.5% resulting in geomean speedup of 3.9%, on top of RRIP cache replacement running mobile code already optimized using PGO.
An Ensemble Mobile-Cloud Computing Method for Affordable and Accurate Glucometer Readout
Jan 04, 2023Despite essential efforts towards advanced wireless medical devices for regular monitoring of blood properties, many such devices are not available or not affordable for everyone in many countries. Alternatively using ordinary devices, patients ought to log data into a mobile health-monitoring manually. It causes several issues: (1) clients reportedly tend to enter unrealistic data; (2) typing values several times a day is bothersome and causes clients to leave the mobile app. Thus, there is a strong need to use now-ubiquitous smartphones, reducing error by capturing images from the screen of medical devices and extracting useful information automatically. Nevertheless, there are a few challenges in its development: (1) data scarcity has led to impractical methods with very low accuracy: to our knowledge, only small datasets are available in this case; (2) accuracy-availability tradeoff: one can execute a less accurate algorithm on a mobile phone to maintain higher availability, or alternatively deploy a more accurate and more compute-intensive algorithm on the cloud, however, at the cost of lower availability in poor/no connectivity situations. We present an ensemble learning algorithm, a mobile-cloud computing service architecture, and a simple compression technique to achieve higher availability and faster response time while providing higher accuracy by integrating cloud- and mobile-side predictions. Additionally, we propose an algorithm to generate synthetic training data which facilitates utilizing deep learning models to improve accuracy. Our proposed method achieves three main objectives: (1) 92.1% and 97.7% accuracy on two different datasets, improving previous methods by 40%, (2) reducing required bandwidth by 45x with 1% drop in accuracy, (3) and providing better availability compared to mobile-only, cloud-only, split computing, and early exit service models.
FullPack: Full Vector Utilization for Sub-Byte Quantized Inference on General Purpose CPUs
Nov 20, 2022Although prior art has demonstrated negligible accuracy drop in sub-byte quantization -- where weights and/or activations are represented by less than 8 bits -- popular SIMD instructions of CPUs do not natively support these datatypes. While recent methods, such as ULPPACK, are already using sub-byte quantization on general-purpose CPUs with vector units, they leave out several empty bits between the sub-byte values in memory and in vector registers to avoid overflow to the neighbours during the operations. This results in memory footprint and bandwidth-usage inefficiencies and suboptimal performance. In this paper, we present memory layouts for storing, and mechanisms for processing sub-byte (4-, 2-, or 1-bit) models that utilize all the bits in the memory as well as in the vector registers for the actual data. We provide compute kernels for the proposed layout for the GEMV (GEneral Matrix-Vector multiplication) operations between weights and activations of different datatypes (e.g., 8-bit activations and 4-bit weights). For evaluation, we extended the TFLite package and added our methods to it, then ran the models on the cycle-accurate gem5 simulator to compare detailed memory and CPU cycles of each method. We compare against nine other methods that are actively used in production including GEMLOWP, Ruy, XNNPack, and ULPPACK. Furthermore, we explore the effect of different input and output sizes of deep learning layers on the performance of our proposed method. Experimental results show 0.96-2.1x speedup for small sizes and 1.2-6.7x speedup for mid to large sizes. Applying our proposal to a real-world speech recognition model, Mozilla DeepSpeech, we proved that our method achieves 1.56-2.11x end-to-end speedup compared to the state-of-the-art, depending on the bit-width employed.
Variant Parallelism: Lightweight Deep Convolutional Models for Distributed Inference on IoT Devices
Oct 15, 2022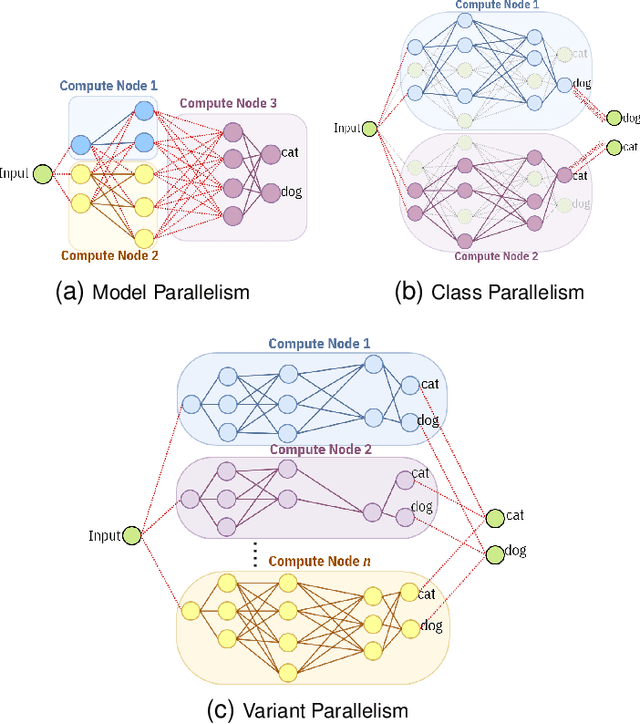
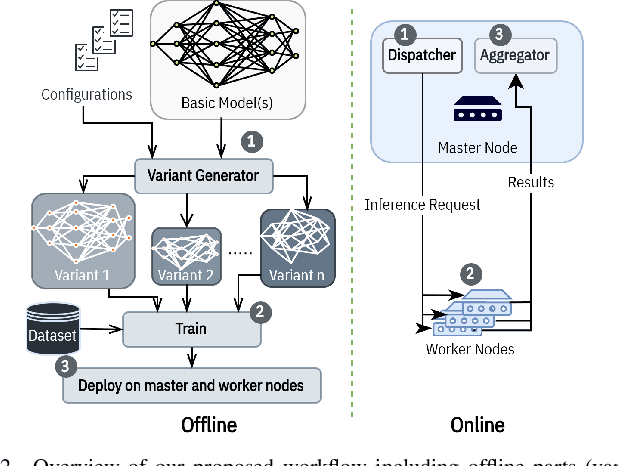
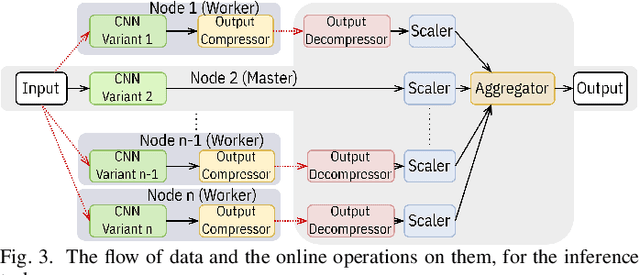

Two major techniques are commonly used to meet real-time inference limitations when distributing models across resource-constrained IoT devices: (1) model parallelism (MP) and (2) class parallelism (CP). In MP, transmitting bulky intermediate data (orders of magnitude larger than input) between devices imposes huge communication overhead. Although CP solves this problem, it has limitations on the number of sub-models. In addition, both solutions are fault intolerant, an issue when deployed on edge devices. We propose variant parallelism (VP), an ensemble-based deep learning distribution method where different variants of a main model are generated and can be deployed on separate machines. We design a family of lighter models around the original model, and train them simultaneously to improve accuracy over single models. Our experimental results on six common mid-sized object recognition datasets demonstrate that our models can have 5.8-7.1x fewer parameters, 4.3-31x fewer multiply-accumulations (MACs), and 2.5-13.2x less response time on atomic inputs compared to MobileNetV2 while achieving comparable or higher accuracy. Our technique easily generates several variants of the base architecture. Each variant returns only 2k outputs 1 <= k <= (#classes/2), representing Top-k classes, instead of tons of floating point values required in MP. Since each variant provides a full-class prediction, our approach maintains higher availability compared with MP and CP in presence of failure.