 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoPersona: Collaborative Persona Graphs for Robust LLM Personalization
Jul 01, 2026Real-world LLM personalization is often constrained by sparse and skewed user histories: most users provide only a handful of interactions, while even frequent users' logs capture an incomplete and biased view of their preferences. As a result, weakly observed user attributes are difficult to infer, leading to brittle personalization when test-time requests shift toward under-supported facets. Motivated by this limitation, we present CoPersona, a graph-based collaborative personalization framework that completes sparse user profiles by borrowing signals from behaviorally similar peers. However, directly transferring signals is difficult because uneven facet coverage introduces bias into interaction histories, obscuring user similarity in the unstructured global space. To address this issue, CoPersona decomposes interaction histories into multiple facet-level representations and explicitly models peer-to-peer, facet-level alignment through a multiplex persona graph. To effectively leverage peer information at inference time, we employ a dual-branch architecture that combines non-parametric peer retrieval with parametric graph reasoning. Experiments across multiple domains and model scales demonstrate consistent improvements over strong baselines, validating CoPersona as an effective approach for robust LLM personalization.
HypRAG: Hyperbolic Dense Retrieval for Retrieval Augmented Generation
Feb 08, 2026Embedding geometry plays a fundamental role in retrieval quality, yet dense retrievers for retrieval-augmented generation (RAG) remain largely confined to Euclidean space. However, natural language exhibits hierarchical structure from broad topics to specific entities that Euclidean embeddings fail to preserve, causing semantically distant documents to appear spuriously similar and increasing hallucination risk. To address these limitations, we introduce hyperbolic dense retrieval, developing two model variants in the Lorentz model of hyperbolic space: HyTE-FH, a fully hyperbolic transformer, and HyTE-H, a hybrid architecture projecting pre-trained Euclidean embeddings into hyperbolic space. To prevent representational collapse during sequence aggregation, we introduce the Outward Einstein Midpoint, a geometry-aware pooling operator that provably preserves hierarchical structure. On MTEB, HyTE-FH outperforms equivalent Euclidean baselines, while on RAGBench, HyTE-H achieves up to 29% gains over Euclidean baselines in context relevance and answer relevance using substantially smaller models than current state-of-the-art retrievers. Our analysis also reveals that hyperbolic representations encode document specificity through norm-based separation, with over 20% radial increase from general to specific concepts, a property absent in Euclidean embeddings, underscoring the critical role of geometric inductive bias in faithful RAG systems.
Embedding Alignment in Code Generation for Audio
Aug 07, 2025LLM-powered code generation has the potential to revolutionize creative coding endeavors, such as live-coding, by enabling users to focus on structural motifs over syntactic details. In such domains, when prompting an LLM, users may benefit from considering multiple varied code candidates to better realize their musical intentions. Code generation models, however, struggle to present unique and diverse code candidates, with no direct insight into the code's audio output. To better establish a relationship between code candidates and produced audio, we investigate the topology of the mapping between code and audio embedding spaces. We find that code and audio embeddings do not exhibit a simple linear relationship, but supplement this with a constructed predictive model that shows an embedding alignment map could be learned. Supplementing the aim for musically diverse output, we present a model that given code predicts output audio embedding, constructing a code-audio embedding alignment map.
Hyperbolic Deep Learning for Foundation Models: A Survey
Jul 23, 2025Foundation models pre-trained on massive datasets, including large language models (LLMs), vision-language models (VLMs), and large multimodal models, have demonstrated remarkable success in diverse downstream tasks. However, recent studies have shown fundamental limitations of these models: (1) limited representational capacity, (2) lower adaptability, and (3) diminishing scalability. These shortcomings raise a critical question: is Euclidean geometry truly the optimal inductive bias for all foundation models, or could incorporating alternative geometric spaces enable models to better align with the intrinsic structure of real-world data and improve reasoning processes? Hyperbolic spaces, a class of non-Euclidean manifolds characterized by exponential volume growth with respect to distance, offer a mathematically grounded solution. These spaces enable low-distortion embeddings of hierarchical structures (e.g., trees, taxonomies) and power-law distributions with substantially fewer dimensions compared to Euclidean counterparts. Recent advances have leveraged these properties to enhance foundation models, including improving LLMs' complex reasoning ability, VLMs' zero-shot generalization, and cross-modal semantic alignment, while maintaining parameter efficiency. This paper provides a comprehensive review of hyperbolic neural networks and their recent development for foundation models. We further outline key challenges and research directions to advance the field.
HEIST: A Graph Foundation Model for Spatial Transcriptomics and Proteomics Data
Jun 11, 2025Single-cell transcriptomics has become a great source for data-driven insights into biology, enabling the use of advanced deep learning methods to understand cellular heterogeneity and transcriptional regulation at the single-cell level. With the advent of spatial transcriptomics data we have the promise of learning about cells within a tissue context as it provides both spatial coordinates and transcriptomic readouts. However, existing models either ignore spatial resolution or the gene regulatory information. Gene regulation in cells can change depending on microenvironmental cues from neighboring cells, but existing models neglect gene regulatory patterns with hierarchical dependencies across levels of abstraction. In order to create contextualized representations of cells and genes from spatial transcriptomics data, we introduce HEIST, a hierarchical graph transformer-based foundation model for spatial transcriptomics and proteomics data. HEIST models tissue as spatial cellular neighborhood graphs, and each cell is, in turn, modeled as a gene regulatory network graph. The framework includes a hierarchical graph transformer that performs cross-level message passing and message passing within levels. HEIST is pre-trained on 22.3M cells from 124 tissues across 15 organs using spatially-aware contrastive learning and masked auto-encoding objectives. Unsupervised analysis of HEIST representations of cells, shows that it effectively encodes the microenvironmental influences in cell embeddings, enabling the discovery of spatially-informed subpopulations that prior models fail to differentiate. Further, HEIST achieves state-of-the-art results on four downstream task such as clinical outcome prediction, cell type annotation, gene imputation, and spatially-informed cell clustering across multiple technologies, highlighting the importance of hierarchical modeling and GRN-based representations.
HELM: Hyperbolic Large Language Models via Mixture-of-Curvature Experts
May 30, 2025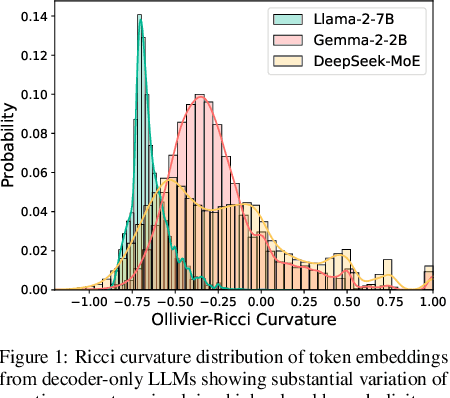
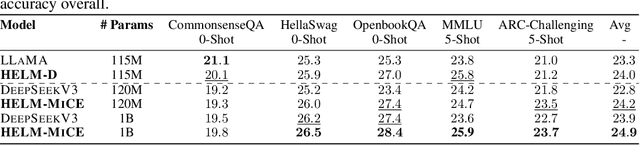
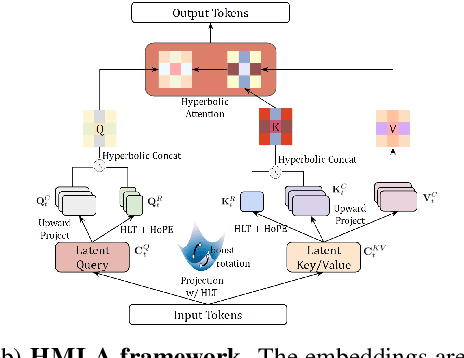

Large language models (LLMs) have shown great success in text modeling tasks across domains. However, natural language exhibits inherent semantic hierarchies and nuanced geometric structure, which current LLMs do not capture completely owing to their reliance on Euclidean operations. Recent studies have also shown that not respecting the geometry of token embeddings leads to training instabilities and degradation of generative capabilities. These findings suggest that shifting to non-Euclidean geometries can better align language models with the underlying geometry of text. We thus propose to operate fully in Hyperbolic space, known for its expansive, scale-free, and low-distortion properties. We thus introduce HELM, a family of HypErbolic Large Language Models, offering a geometric rethinking of the Transformer-based LLM that addresses the representational inflexibility, missing set of necessary operations, and poor scalability of existing hyperbolic LMs. We additionally introduce a Mixture-of-Curvature Experts model, HELM-MICE, where each expert operates in a distinct curvature space to encode more fine-grained geometric structure from text, as well as a dense model, HELM-D. For HELM-MICE, we further develop hyperbolic Multi-Head Latent Attention (HMLA) for efficient, reduced-KV-cache training and inference. For both models, we develop essential hyperbolic equivalents of rotary positional encodings and RMS normalization. We are the first to train fully hyperbolic LLMs at billion-parameter scale, and evaluate them on well-known benchmarks such as MMLU and ARC, spanning STEM problem-solving, general knowledge, and commonsense reasoning. Our results show consistent gains from our HELM architectures -- up to 4% -- over popular Euclidean architectures used in LLaMA and DeepSeek, highlighting the efficacy and enhanced reasoning afforded by hyperbolic geometry in large-scale LM pretraining.
HiPoNet: A Topology-Preserving Multi-View Neural Network For High Dimensional Point Cloud and Single-Cell Data
Feb 11, 2025



In this paper, we propose HiPoNet, an end-to-end differentiable neural network for regression, classification, and representation learning on high-dimensional point clouds. Single-cell data can have high dimensionality exceeding the capabilities of existing methods point cloud tailored for 3D data. Moreover, modern single-cell and spatial experiments now yield entire cohorts of datasets (i.e. one on every patient), necessitating models that can process large, high-dimensional point clouds at scale. Most current approaches build a single nearest-neighbor graph, discarding important geometric information. In contrast, HiPoNet forms higher-order simplicial complexes through learnable feature reweighting, generating multiple data views that disentangle distinct biological processes. It then employs simplicial wavelet transforms to extract multi-scale features - capturing both local and global topology. We empirically show that these components preserve topological information in the learned representations, and that HiPoNet significantly outperforms state-of-the-art point-cloud and graph-based models on single cell. We also show an application of HiPoNet on spatial transcriptomics datasets using spatial co-ordinates as one of the views. Overall, HiPoNet offers a robust and scalable solution for high-dimensional data analysis.
Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
Dec 17, 2021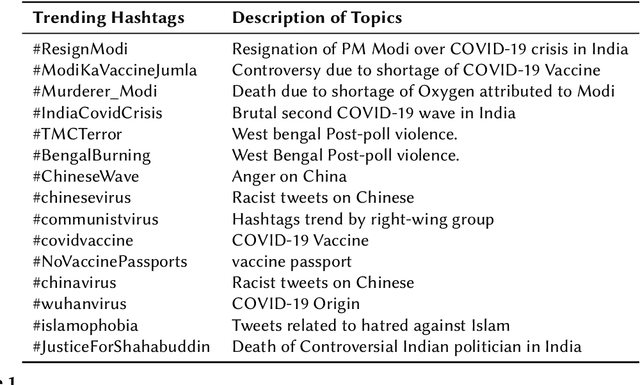
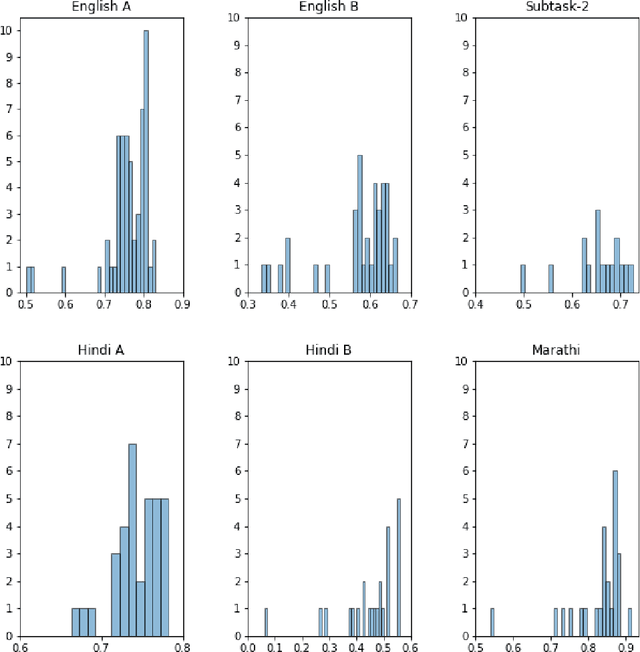
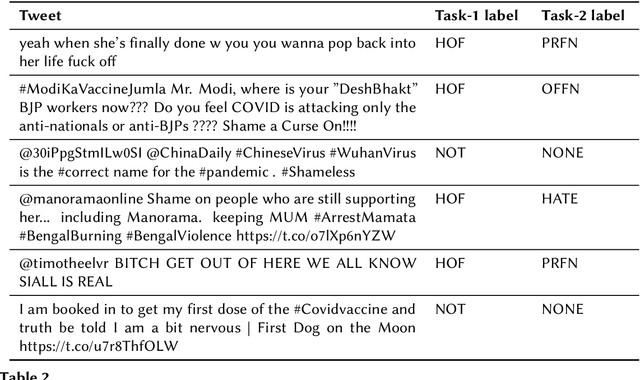

The widespread of offensive content online such as hate speech poses a growing societal problem. AI tools are necessary for supporting the moderation process at online platforms. For the evaluation of these identification tools, continuous experimentation with data sets in different languages are necessary. The HASOC track (Hate Speech and Offensive Content Identification) is dedicated to develop benchmark data for this purpose. This paper presents the HASOC subtrack for English, Hindi, and Marathi. The data set was assembled from Twitter. This subtrack has two sub-tasks. Task A is a binary classification problem (Hate and Not Offensive) offered for all three languages. Task B is a fine-grained classification problem for three classes (HATE) Hate speech, OFFENSIVE and PROFANITY offered for English and Hindi. Overall, 652 runs were submitted by 65 teams. The performance of the best classification algorithms for task A are F1 measures 0.91, 0.78 and 0.83 for Marathi, Hindi and English, respectively. This overview presents the tasks and the data development as well as the detailed results. The systems submitted to the competition applied a variety of technologies. The best performing algorithms were mainly variants of transformer architectures.