 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022
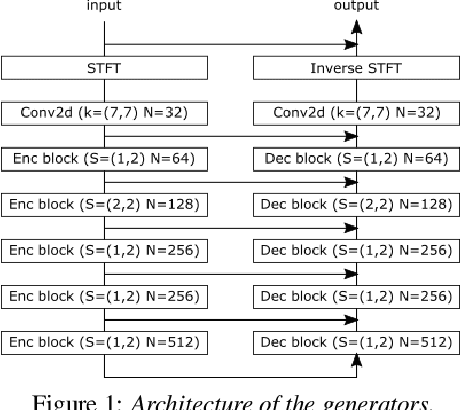

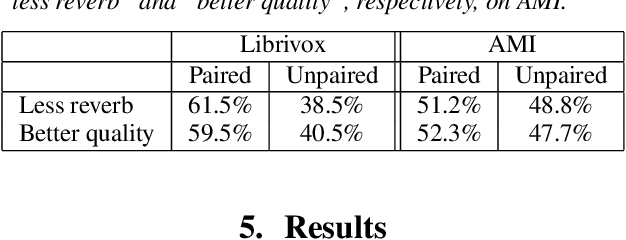
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Listen, denoise, action! Audio-driven motion synthesis with diffusion models
Nov 17, 2022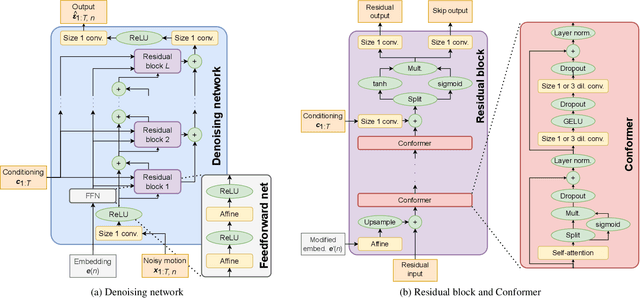
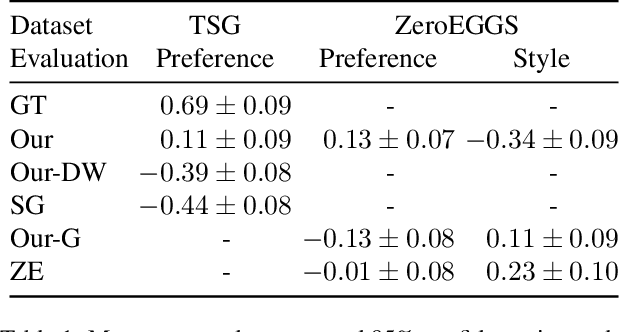

Diffusion models have experienced a surge of interest as highly expressive yet efficiently trainable probabilistic models. We show that these models are an excellent fit for synthesising human motion that co-occurs with audio, for example co-speech gesticulation, since motion is complex and highly ambiguous given audio, calling for a probabilistic description. Specifically, we adapt the DiffWave architecture to model 3D pose sequences, putting Conformers in place of dilated convolutions for improved accuracy. We also demonstrate control over motion style, using classifier-free guidance to adjust the strength of the stylistic expression. Gesture-generation experiments on the Trinity Speech-Gesture and ZeroEGGS datasets confirm that the proposed method achieves top-of-the-line motion quality, with distinctive styles whose expression can be made more or less pronounced. We also synthesise dance motion and path-driven locomotion using the same model architecture. Finally, we extend the guidance procedure to perform style interpolation in a manner that is appealing for synthesis tasks and has connections to product-of-experts models, a contribution we believe is of independent interest. Video examples are available at https://www.speech.kth.se/research/listen-denoise-action/
SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech
Jun 24, 2022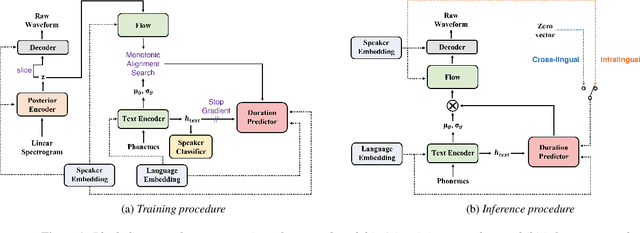
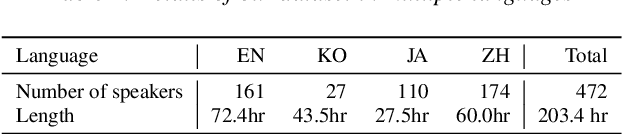
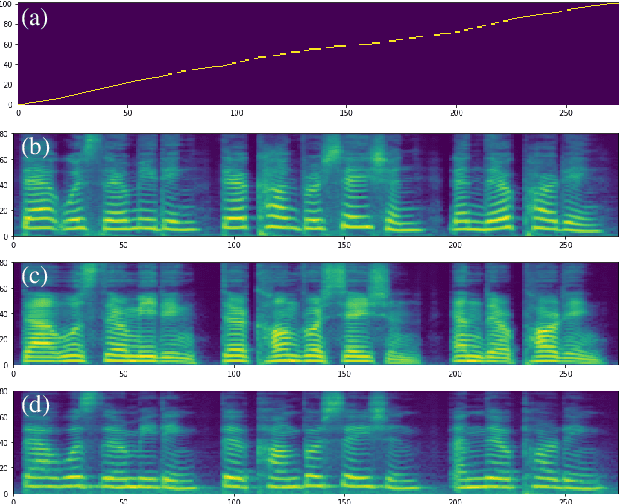

In this paper, we present SANE-TTS, a stable and natural end-to-end multilingual TTS model. By the difficulty of obtaining multilingual corpus for given speaker, training multilingual TTS model with monolingual corpora is unavoidable. We introduce speaker regularization loss that improves speech naturalness during cross-lingual synthesis as well as domain adversarial training, which is applied in other multilingual TTS models. Furthermore, by adding speaker regularization loss, replacing speaker embedding with zero vector in duration predictor stabilizes cross-lingual inference. With this replacement, our model generates speeches with moderate rhythm regardless of source speaker in cross-lingual synthesis. In MOS evaluation, SANE-TTS achieves naturalness score above 3.80 both in cross-lingual and intralingual synthesis, where the ground truth score is 3.99. Also, SANE-TTS maintains speaker similarity close to that of ground truth even in cross-lingual inference. Audio samples are available on our web page.
Improved Meta Learning for Low Resource Speech Recognition
May 11, 2022
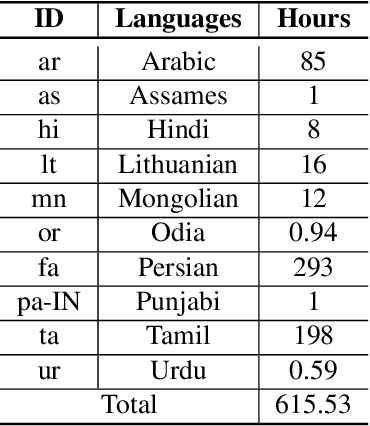
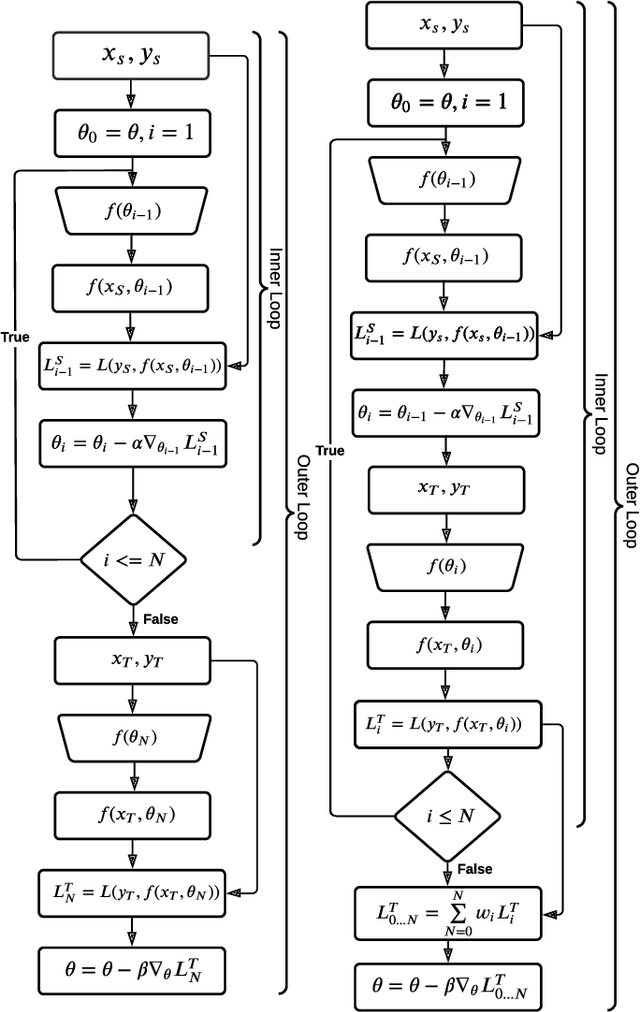

We propose a new meta learning based framework for low resource speech recognition that improves the previous model agnostic meta learning (MAML) approach. The MAML is a simple yet powerful meta learning approach. However, the MAML presents some core deficiencies such as training instabilities and slower convergence speed. To address these issues, we adopt multi-step loss (MSL). The MSL aims to calculate losses at every step of the inner loop of MAML and then combines them with a weighted importance vector. The importance vector ensures that the loss at the last step has more importance than the previous steps. Our empirical evaluation shows that MSL significantly improves the stability of the training procedure and it thus also improves the accuracy of the overall system. Our proposed system outperforms MAML based low resource ASR system on various languages in terms of character error rates and stable training behavior.
* Published in IEEE ICASSP 2022
Content-Dependent Fine-Grained Speaker Embedding for Zero-Shot Speaker Adaptation in Text-to-Speech Synthesis
Apr 03, 2022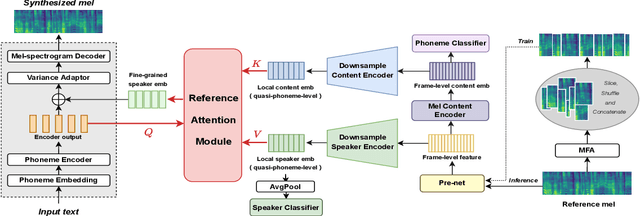
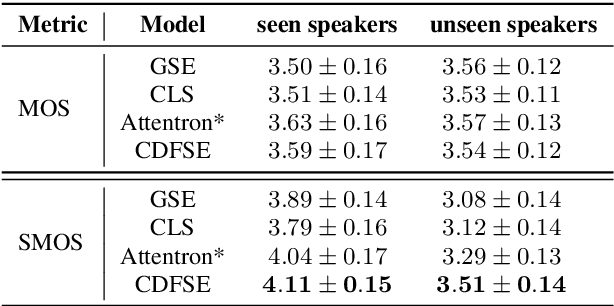
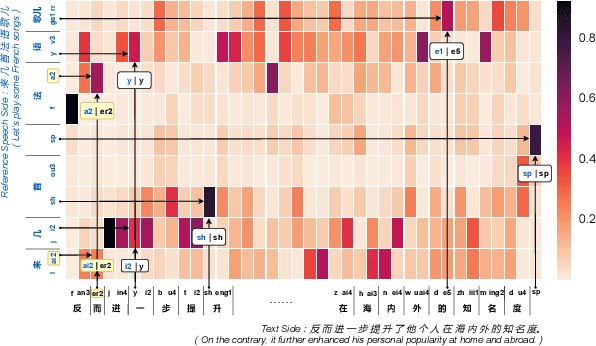
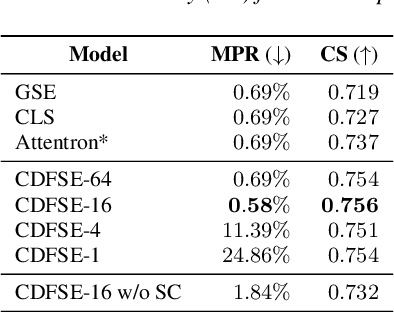
Zero-shot speaker adaptation aims to clone an unseen speaker's voice without any adaptation time and parameters. Previous researches usually use a speaker encoder to extract a global fixed speaker embedding from reference speech, and several attempts have tried variable-length speaker embedding. However, they neglect to transfer the personal pronunciation characteristics related to phoneme content, leading to poor speaker similarity in terms of detailed speaking styles and pronunciation habits. To improve the ability of the speaker encoder to model personal pronunciation characteristics, we propose content-dependent fine-grained speaker embedding for zero-shot speaker adaptation. The corresponding local content embeddings and speaker embeddings are extracted from a reference speech, respectively. Instead of modeling the temporal relations, a reference attention module is introduced to model the content relevance between the reference speech and the input text, and to generate the fine-grained speaker embedding for each phoneme encoder output. The experimental results show that our proposed method can improve speaker similarity of synthesized speeches, especially for unseen speakers.
Using Deep Learning Techniques and Inferential Speech Statistics for AI Synthesised Speech Recognition
Jul 23, 2021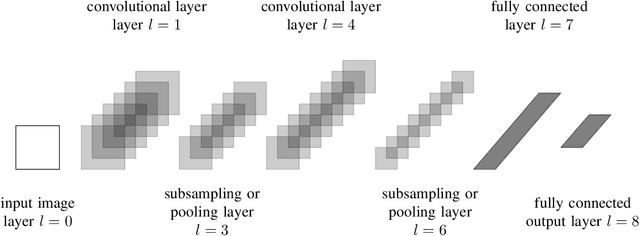
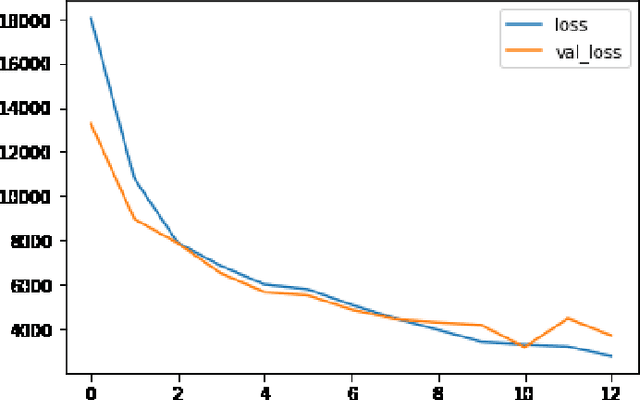
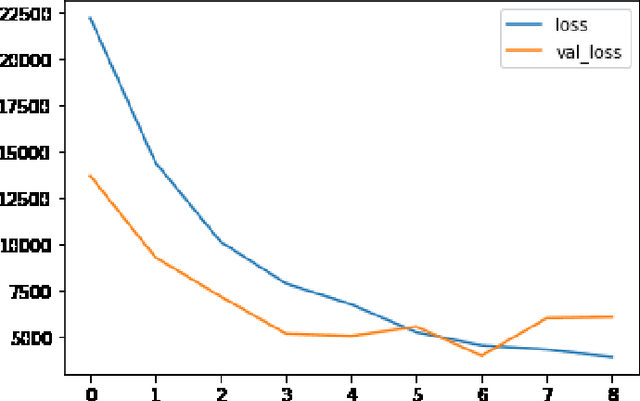
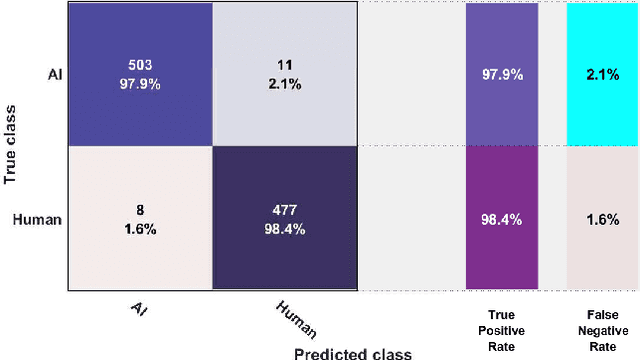
The recent developments in technology have re-warded us with amazing audio synthesis models like TACOTRON and WAVENETS. On the other side, it poses greater threats such as speech clones and deep fakes, that may go undetected. To tackle these alarming situations, there is an urgent need to propose models that can help discriminate a synthesized speech from an actual human speech and also identify the source of such a synthesis. Here, we propose a model based on Convolutional Neural Network (CNN) and Bidirectional Recurrent Neural Network (BiRNN) that helps to achieve both the aforementioned objectives. The temporal dependencies present in AI synthesized speech are exploited using Bidirectional RNN and CNN. The model outperforms the state-of-the-art approaches by classifying the AI synthesized audio from real human speech with an error rate of 1.9% and detecting the underlying architecture with an accuracy of 97%.
Selecting and combining complementary feature representations and classifiers for hate speech detection
Jan 18, 2022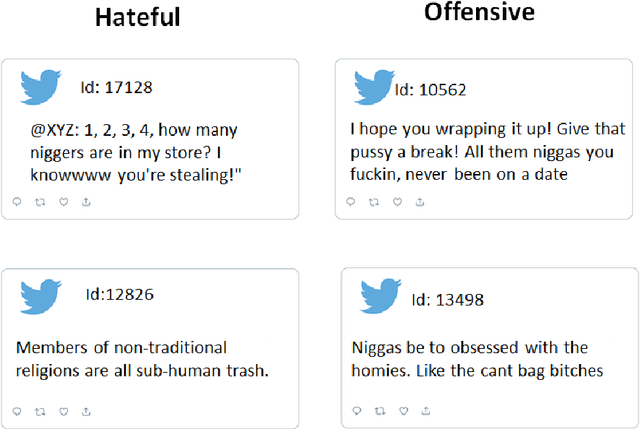
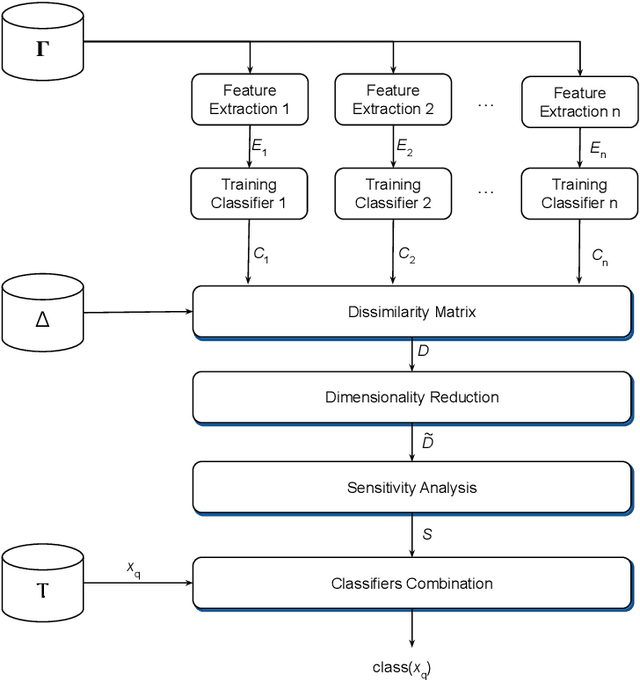
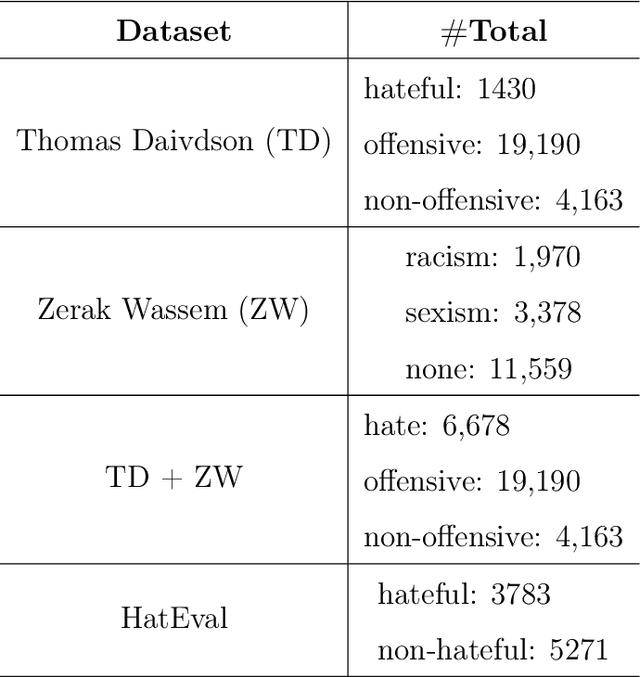

Hate speech is a major issue in social networks due to the high volume of data generated daily. Recent works demonstrate the usefulness of machine learning (ML) in dealing with the nuances required to distinguish between hateful posts from just sarcasm or offensive language. Many ML solutions for hate speech detection have been proposed by either changing how features are extracted from the text or the classification algorithm employed. However, most works consider only one type of feature extraction and classification algorithm. This work argues that a combination of multiple feature extraction techniques and different classification models is needed. We propose a framework to analyze the relationship between multiple feature extraction and classification techniques to understand how they complement each other. The framework is used to select a subset of complementary techniques to compose a robust multiple classifiers system (MCS) for hate speech detection. The experimental study considering four hate speech classification datasets demonstrates that the proposed framework is a promising methodology for analyzing and designing high-performing MCS for this task. MCS system obtained using the proposed framework significantly outperforms the combination of all models and the homogeneous and heterogeneous selection heuristics, demonstrating the importance of having a proper selection scheme. Source code, figures, and dataset splits can be found in the GitHub repository: https://github.com/Menelau/Hate-Speech-MCS.
InQSS: a speech intelligibility assessment model using a multi-task learning network
Nov 04, 2021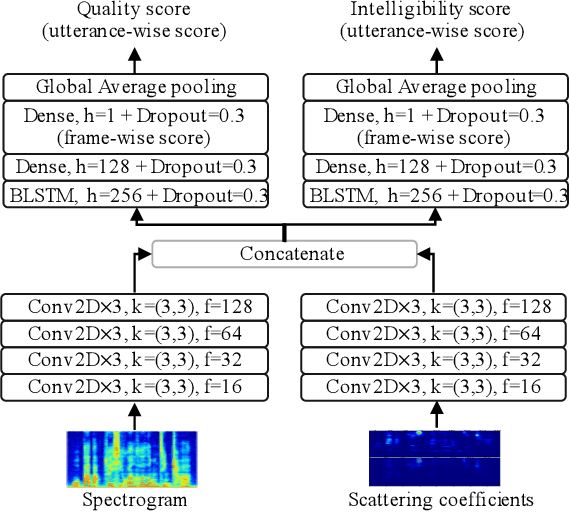
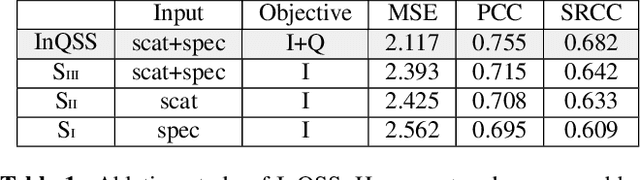
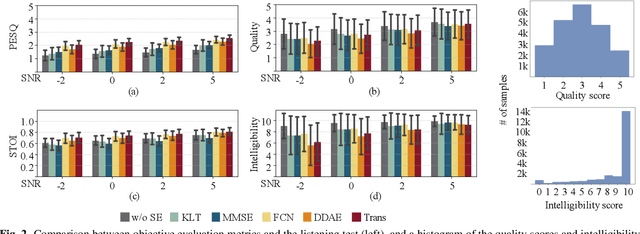
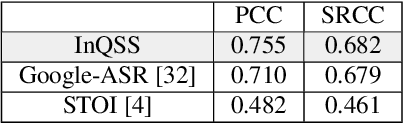
Speech intelligibility assessment models are essential tools for researchers to evaluate and improve speech processing models. In this study, we propose InQSS, a speech intelligibility assessment model that uses both spectrogram and scattering coefficients as input features. In addition, InQSS uses a multi-task learning network in which quality scores can guide the training of the speech intelligibility assessment. The resulting model can predict not only the intelligibility scores but also the quality scores of a speech. The experimental results confirm that the scattering coefficients and quality scores are informative for intelligibility. Moreover, we released TMHINT-QI, which is a Chinese speech dataset that records the quality and intelligibility scores of clean, noisy, and enhanced speech.
Injecting Text in Self-Supervised Speech Pretraining
Aug 27, 2021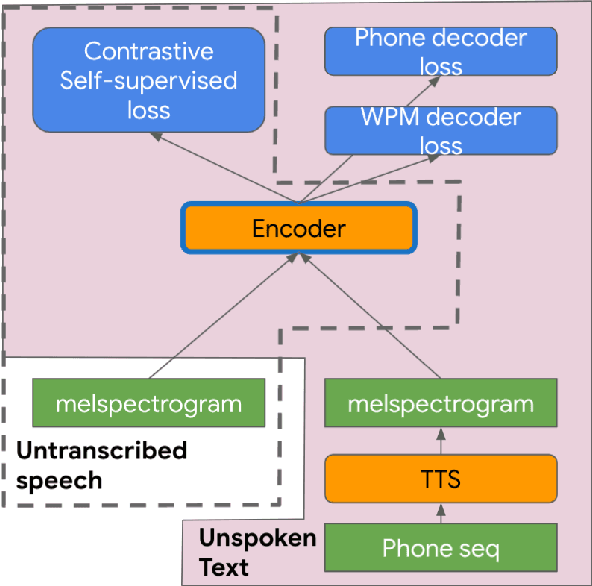

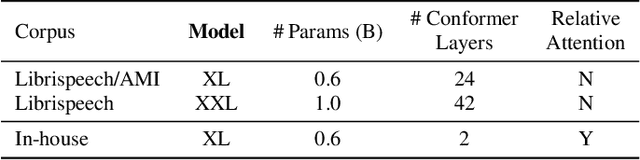
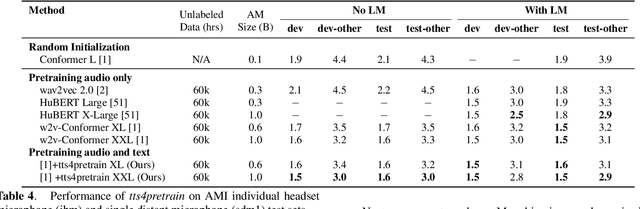
Self-supervised pretraining for Automated Speech Recognition (ASR) has shown varied degrees of success. In this paper, we propose to jointly learn representations during pretraining from two different modalities: speech and text. The proposed method, tts4pretrain complements the power of contrastive learning in self-supervision with linguistic/lexical representations derived from synthesized speech, effectively learning from untranscribed speech and unspoken text. Lexical learning in the speech encoder is enforced through an additional sequence loss term that is coupled with contrastive loss during pretraining. We demonstrate that this novel pretraining method yields Word Error Rate (WER) reductions of 10% relative on the well-benchmarked, Librispeech task over a state-of-the-art baseline pretrained with wav2vec2.0 only. The proposed method also serves as an effective strategy to compensate for the lack of transcribed speech, effectively matching the performance of 5000 hours of transcribed speech with just 100 hours of transcribed speech on the AMI meeting transcription task. Finally, we demonstrate WER reductions of up to 15% on an in-house Voice Search task over traditional pretraining. Incorporating text into encoder pretraining is complimentary to rescoring with a larger or in-domain language model, resulting in additional 6% relative reduction in WER.
Decoding High-level Imagined Speech using Attention-based Deep Neural Networks
Dec 13, 2021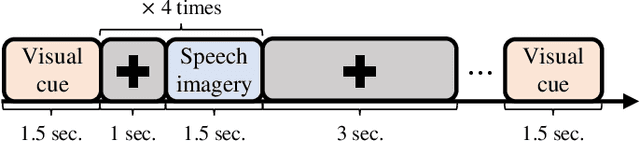
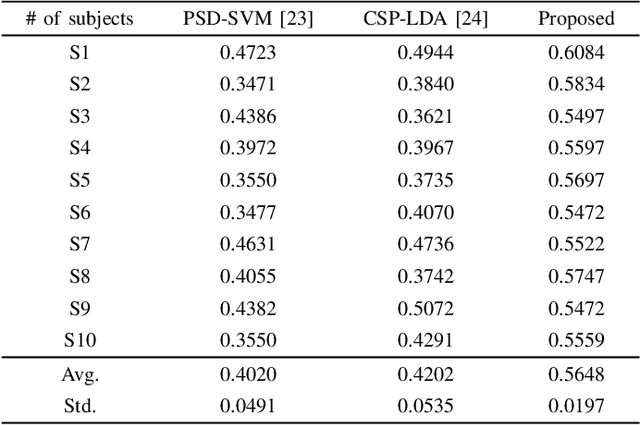
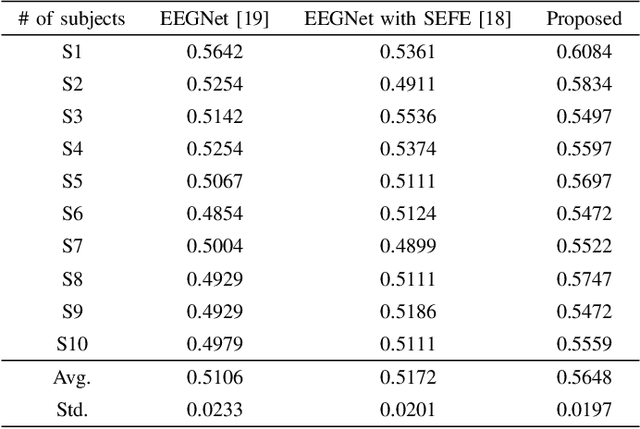
Brain-computer interface (BCI) is the technology that enables the communication between humans and devices by reflecting status and intentions of humans. When conducting imagined speech, the users imagine the pronunciation as if actually speaking. In the case of decoding imagined speech-based EEG signals, complex task can be conducted more intuitively, but decoding performance is lower than that of other BCI paradigms. We modified our previous model for decoding imagined speech-based EEG signals. Ten subjects participated in the experiment. The average accuracy of our proposed method was 0.5648 for classifying four words. In other words, our proposed method has significant strength in learning local features. Hence, we demonstrated the feasibility of decoding imagined speech-based EEG signals with robust performance.