 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJenGAN: Stacked Shifted Filters in GAN-Based Speech Synthesis
Jun 10, 2024Non-autoregressive GAN-based neural vocoders are widely used due to their fast inference speed and high perceptual quality. However, they often suffer from audible artifacts such as tonal artifacts in their generated results. Therefore, we propose JenGAN, a new training strategy that involves stacking shifted low-pass filters to ensure the shift-equivariant property. This method helps prevent aliasing and reduce artifacts while preserving the model structure used during inference. In our experimental evaluation, JenGAN consistently enhances the performance of vocoder models, yielding significantly superior scores across the majority of evaluation metrics.
PITS: Variational Pitch Inference without Fundamental Frequency for End-to-End Pitch-controllable TTS
Mar 02, 2023



Previous pitch-controllable text-to-speech (TTS) models rely on directly modeling fundamental frequency, leading to low variance in synthesized speech. To address this issue, we propose PITS, an end-to-end pitch-controllable TTS model that utilizes variational inference to model pitch. Based on VITS, PITS incorporates the Yingram encoder, the Yingram decoder, and adversarial training of pitch-shifted synthesis to achieve pitch-controllability. Experiments demonstrate that PITS generates high-quality speech that is indistinguishable from ground truth speech and has high pitch-controllability without quality degradation. Code and audio samples will be available at https://github.com/anonymous-pits/pits.
PhaseAug: A Differentiable Augmentation for Speech Synthesis to Simulate One-to-Many Mapping
Nov 08, 2022



Previous generative adversarial network (GAN)-based neural vocoders are trained to reconstruct the exact ground truth waveform from the paired mel-spectrogram and do not consider the one-to-many relationship of speech synthesis. This conventional training causes overfitting for both the discriminators and the generator, leading to the periodicity artifacts in the generated audio signal. In this work, we present PhaseAug, the first differentiable augmentation for speech synthesis that rotates the phase of each frequency bin to simulate one-to-many mapping. With our proposed method, we outperform baselines without any architecture modification. Code and audio samples will be available at https://github.com/mindslab-ai/phaseaug.
SANE-TTS: Stable And Natural End-to-End Multilingual Text-to-Speech
Jun 24, 2022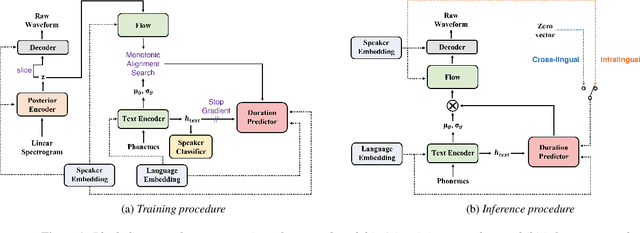
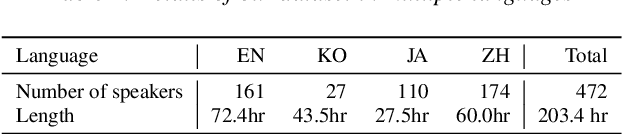

In this paper, we present SANE-TTS, a stable and natural end-to-end multilingual TTS model. By the difficulty of obtaining multilingual corpus for given speaker, training multilingual TTS model with monolingual corpora is unavoidable. We introduce speaker regularization loss that improves speech naturalness during cross-lingual synthesis as well as domain adversarial training, which is applied in other multilingual TTS models. Furthermore, by adding speaker regularization loss, replacing speaker embedding with zero vector in duration predictor stabilizes cross-lingual inference. With this replacement, our model generates speeches with moderate rhythm regardless of source speaker in cross-lingual synthesis. In MOS evaluation, SANE-TTS achieves naturalness score above 3.80 both in cross-lingual and intralingual synthesis, where the ground truth score is 3.99. Also, SANE-TTS maintains speaker similarity close to that of ground truth even in cross-lingual inference. Audio samples are available on our web page.