 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
End-to-End Label Uncertainty Modeling in Speech Emotion Recognition using Bayesian Neural Networks and Label Distribution Learning
Sep 30, 2022
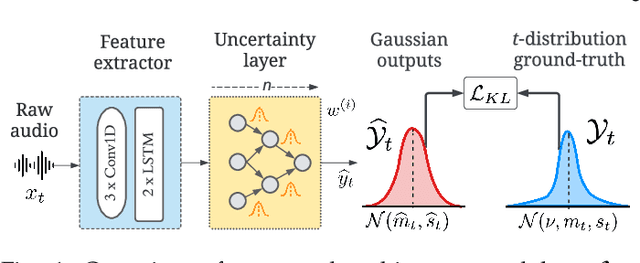
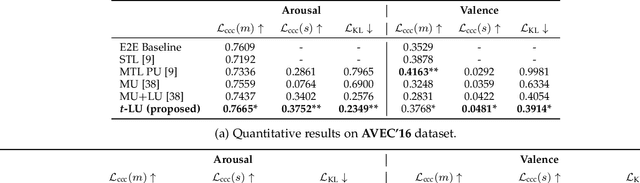
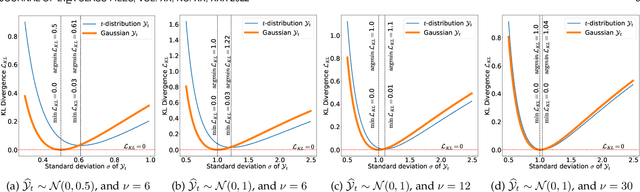
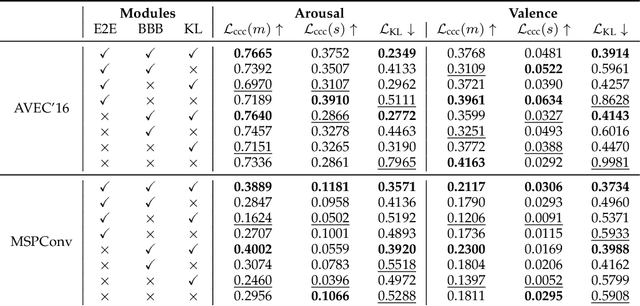
To train machine learning algorithms to predict emotional expressions in terms of arousal and valence, annotated datasets are needed. However, as different people perceive others' emotional expressions differently, their annotations are per se subjective. For this, annotations are typically collected from multiple annotators and averaged to obtain ground-truth labels. However, when exclusively trained on this averaged ground-truth, the trained network is agnostic to the inherent subjectivity in emotional expressions. In this work, we therefore propose an end-to-end Bayesian neural network capable of being trained on a distribution of labels to also capture the subjectivity-based label uncertainty. Instead of a Gaussian, we model the label distribution using Student's t-distribution, which also accounts for the number of annotations. We derive the corresponding Kullback-Leibler divergence loss and use it to train an estimator for the distribution of labels, from which the mean and uncertainty can be inferred. We validate the proposed method using two in-the-wild datasets. We show that the proposed t-distribution based approach achieves state-of-the-art uncertainty modeling results in speech emotion recognition, and also consistent results in cross-corpora evaluations. Furthermore, analyses reveal that the advantage of a t-distribution over a Gaussian grows with increasing inter-annotator correlation and a decreasing number of annotators.
Vocal Breath Sound Based Gender Classification
Nov 11, 2022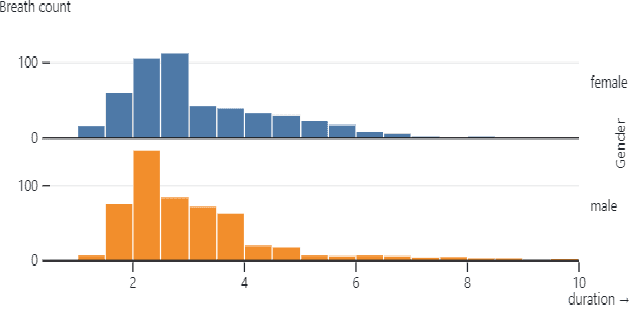
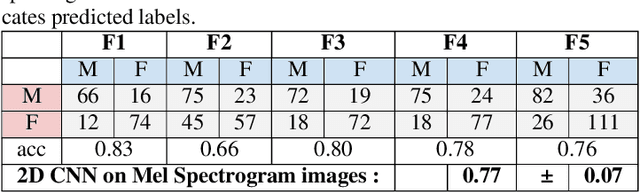
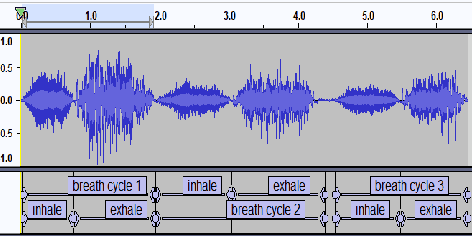
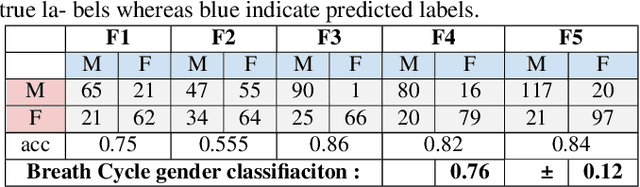
Voiced speech signals such as continuous speech are known to have acoustic features such as pitch(F0), and formant frequencies(F1, F2, F3) which can be used for gender classification. However, gender classification studies using non-speech signals such as vocal breath sounds have not been explored as they lack typical gender-specific acoustic features. In this work, we explore whether vocal breath sounds encode gender information and if so, to what extent it can be used for automatic gender classification. In this study, we explore the use of data-driven and knowledge-based features from vocal breath sounds as well as the classifier complexity for gender classification. We also explore the importance of the location and duration of breath signal segments to be used for automatic classification. Experiments with 54.23 minutes of male and 51.83 minutes of female breath sounds reveal that knowledge-based features, namely MFCC statistics, with low-complexity classifier perform comparably to the data-driven features with classifiers of higher complexity. Breath segments with an average duration of 3 seconds are found to be the best choice irrespective of the location which avoids the need for breath cycle boundary annotation.
Separating Long-Form Speech with Group-Wise Permutation Invariant Training
Nov 17, 2021
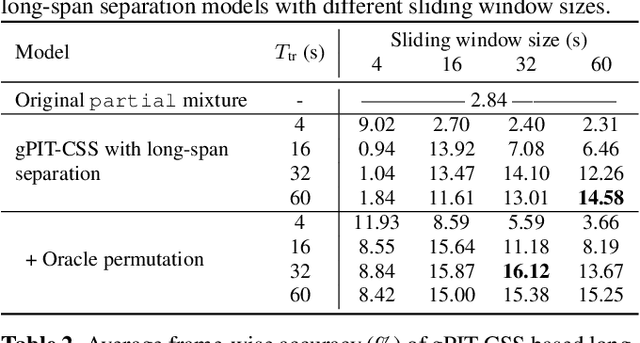
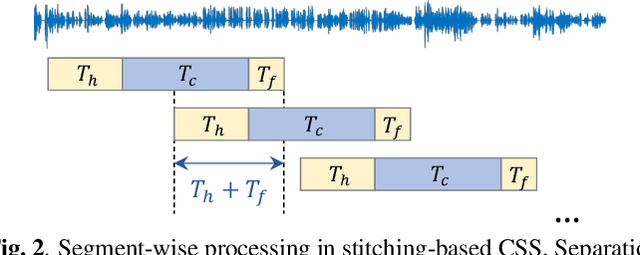
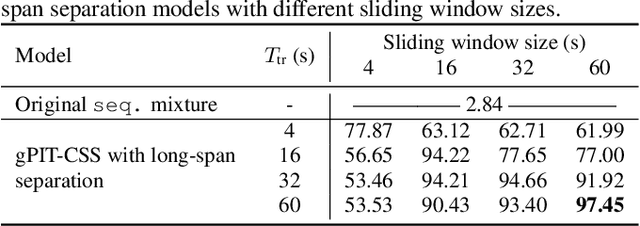
Multi-talker conversational speech processing has drawn many interests for various applications such as meeting transcription. Speech separation is often required to handle overlapped speech that is commonly observed in conversation. Although the original utterancelevel permutation invariant training-based continuous speech separation approach has proven to be effective in various conditions, it lacks the ability to leverage the long-span relationship of utterances and is computationally inefficient due to the highly overlapped sliding windows. To overcome these drawbacks, we propose a novel training scheme named Group-PIT, which allows direct training of the speech separation models on the long-form speech with a low computational cost for label assignment. Two different speech separation approaches with Group-PIT are explored, including direct long-span speech separation and short-span speech separation with long-span tracking. The experiments on the simulated meeting-style data demonstrate the effectiveness of our proposed approaches, especially in dealing with a very long speech input.
Learning Contextually Fused Audio-visual Representations for Audio-visual Speech Recognition
Feb 15, 2022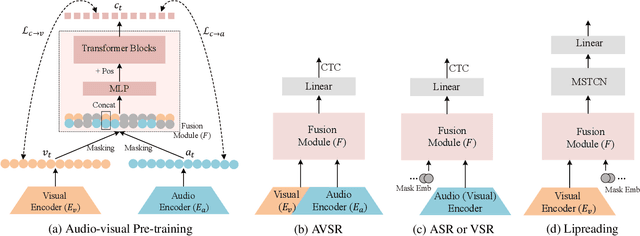
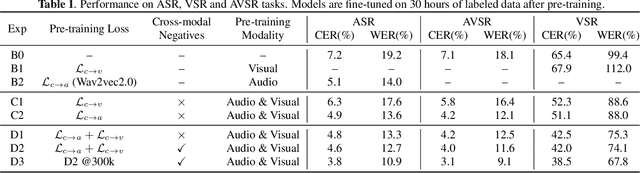
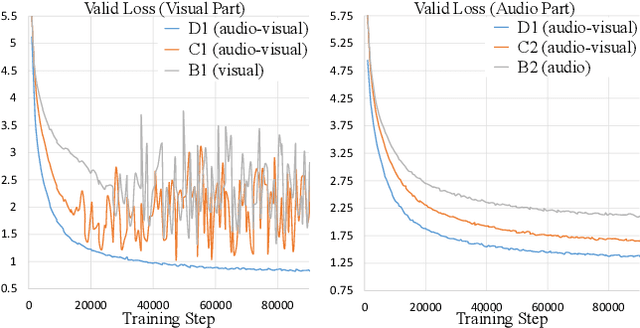
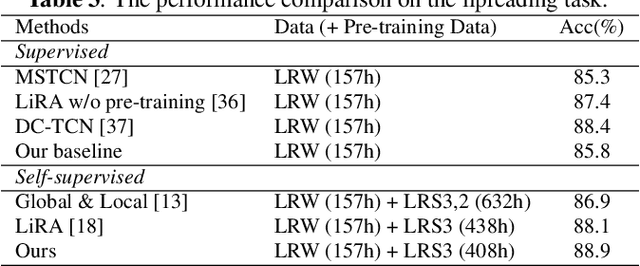
With the advance in self-supervised learning for audio and visual modalities, it has become possible to learn a robust audio-visual speech representation. This would be beneficial for improving the audio-visual speech recognition (AVSR) performance, as the multi-modal inputs contain more fruitful information in principle. In this paper, based on existing self-supervised representation learning methods for audio modality, we therefore propose an audio-visual representation learning approach. The proposed approach explores both the complementarity of audio-visual modalities and long-term context dependency using a transformer-based fusion module and a flexible masking strategy. After pre-training, the model is able to extract fused representations required by AVSR. Without loss of generality, it can be applied to single-modal tasks, e.g. audio/visual speech recognition by simply masking out one modality in the fusion module. The proposed pre-trained model is evaluated on speech recognition and lipreading tasks using one or two modalities, where the superiority is revealed.
An Overview of Indian Spoken Language Recognition from Machine Learning Perspective
Nov 30, 2022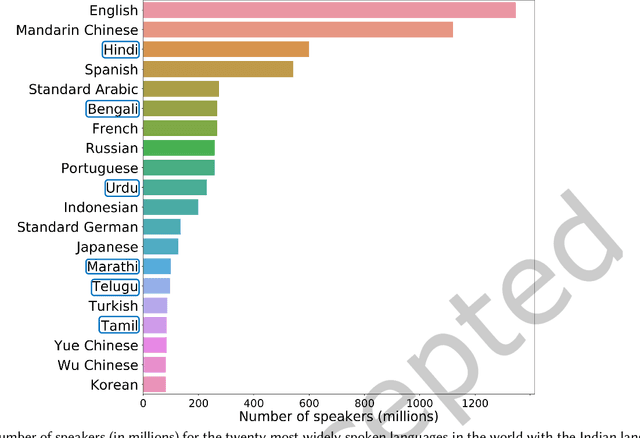

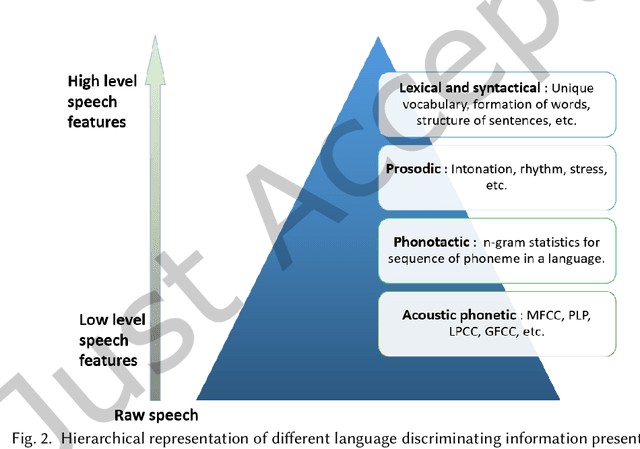

Automatic spoken language identification (LID) is a very important research field in the era of multilingual voice-command-based human-computer interaction (HCI). A front-end LID module helps to improve the performance of many speech-based applications in the multilingual scenario. India is a populous country with diverse cultures and languages. The majority of the Indian population needs to use their respective native languages for verbal interaction with machines. Therefore, the development of efficient Indian spoken language recognition systems is useful for adapting smart technologies in every section of Indian society. The field of Indian LID has started gaining momentum in the last two decades, mainly due to the development of several standard multilingual speech corpora for the Indian languages. Even though significant research progress has already been made in this field, to the best of our knowledge, there are not many attempts to analytically review them collectively. In this work, we have conducted one of the very first attempts to present a comprehensive review of the Indian spoken language recognition research field. In-depth analysis has been presented to emphasize the unique challenges of low-resource and mutual influences for developing LID systems in the Indian contexts. Several essential aspects of the Indian LID research, such as the detailed description of the available speech corpora, the major research contributions, including the earlier attempts based on statistical modeling to the recent approaches based on different neural network architectures, and the future research trends are discussed. This review work will help assess the state of the present Indian LID research by any active researcher or any research enthusiasts from related fields.
* Accepted for publication in ACM Transactions on Asian and Low-Resource Language Information Processing
Representing `how you say' with `what you say': English corpus of focused speech and text reflecting corresponding implications
Mar 29, 2022
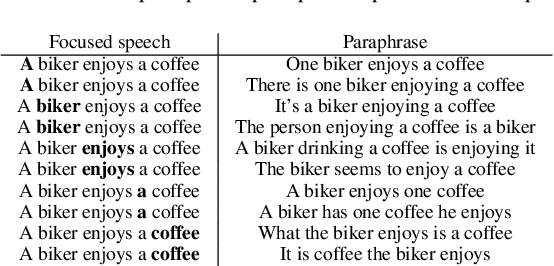
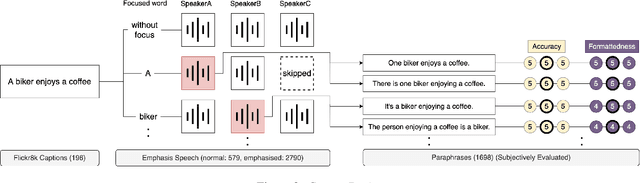
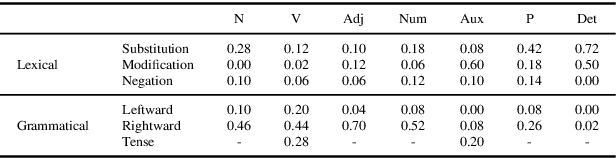
In speech communication, how something is said (paralinguistic information) is as crucial as what is said (linguistic information). As a type of paralinguistic information, English speech uses sentence stress, the heaviest prominence within a sentence, to convey emphasis. While different placements of sentence stress communicate different emphatic implications, current speech translation systems return the same translations if the utterances are linguistically identical, losing paralinguistic information. Concentrating on focus, a type of emphasis, we propose mapping paralinguistic information into the linguistic domain within the source language using lexical and grammatical devices. This method enables us to translate the paraphrased text representations instead of the transcription of the original speech and obtain translations that preserve paralinguistic information. As a first step, we present the collection of an English corpus containing speech that differed in the placement of focus along with the corresponding text, which was designed to reflect the implied meaning of the speech. Also, analyses of our corpus demonstrated that mapping of focus from the paralinguistic domain into the linguistic domain involved various lexical and grammatical methods. The data and insights from our analysis will further advance research into paralinguistic translation. The corpus will be published via LDC.
Speaker- and Age-Invariant Training for Child Acoustic Modeling Using Adversarial Multi-Task Learning
Oct 19, 2022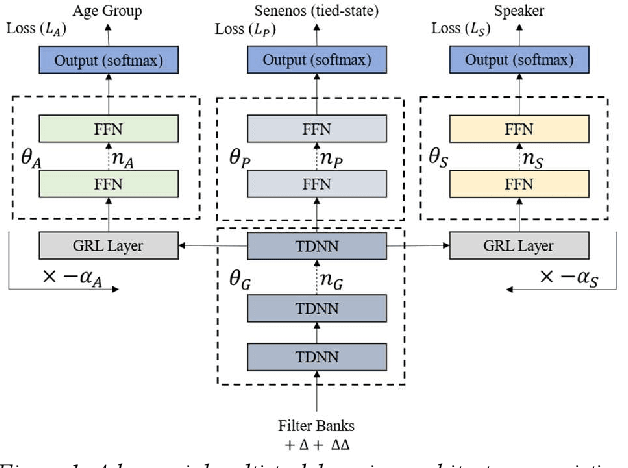
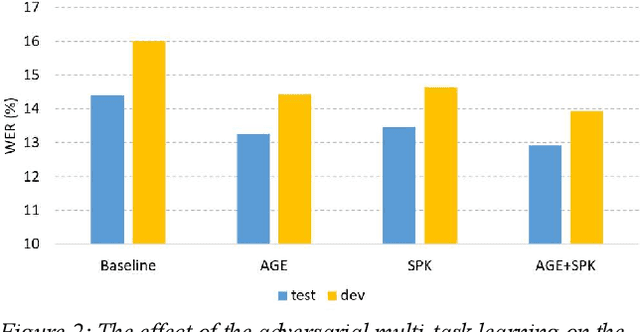
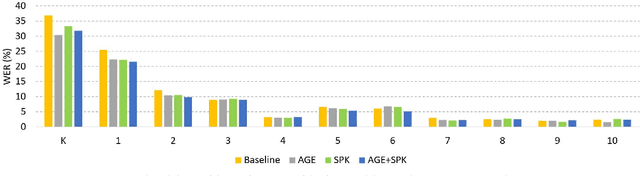
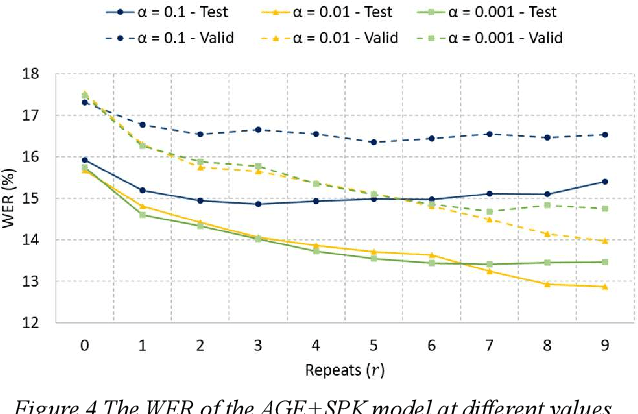
One of the major challenges in acoustic modelling of child speech is the rapid changes that occur in the children's articulators as they grow up, their differing growth rates and the subsequent high variability in the same age group. These high acoustic variations along with the scarcity of child speech corpora have impeded the development of a reliable speech recognition system for children. In this paper, a speaker- and age-invariant training approach based on adversarial multi-task learning is proposed. The system consists of one generator shared network that learns to generate speaker- and age-invariant features connected to three discrimination networks, for phoneme, age, and speaker. The generator network is trained to minimize the phoneme-discrimination loss and maximize the speaker- and age-discrimination losses in an adversarial multi-task learning fashion. The generator network is a Time Delay Neural Network (TDNN) architecture while the three discriminators are feed-forward networks. The system was applied to the OGI speech corpora and achieved a 13% reduction in the WER of the ASR.
Autodecompose: A generative self-supervised model for semantic decomposition
Feb 13, 2023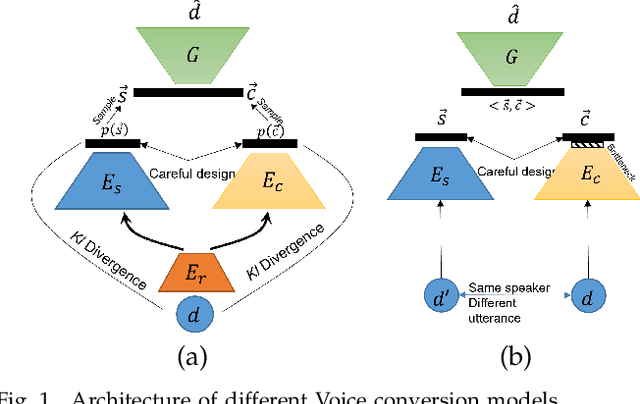

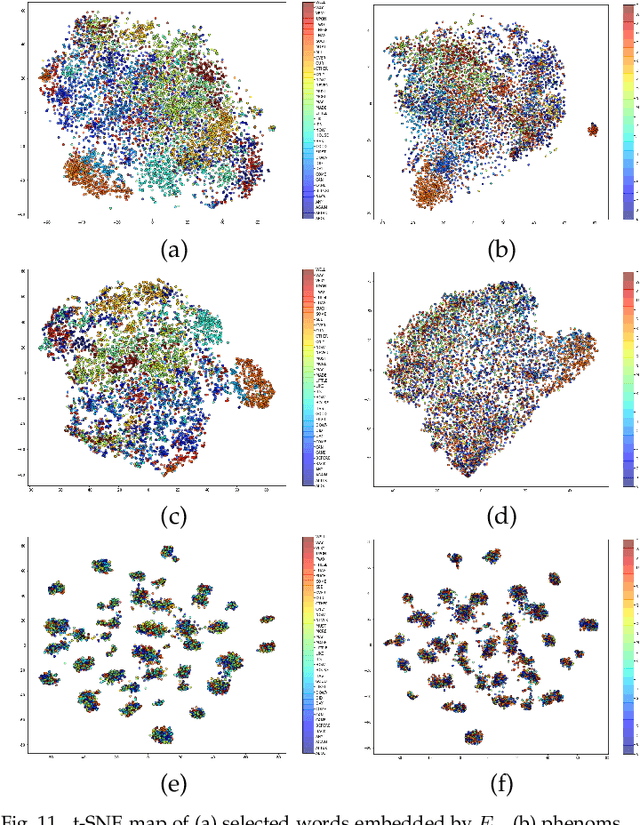
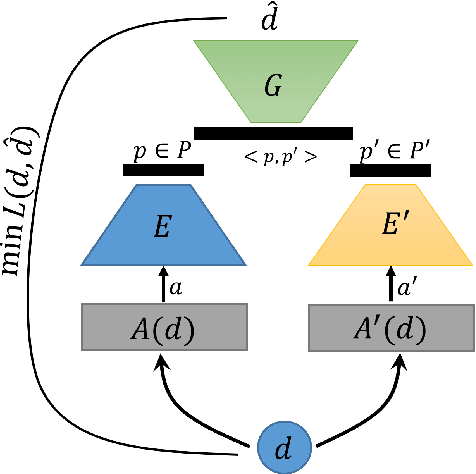
We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
Feb 25, 2022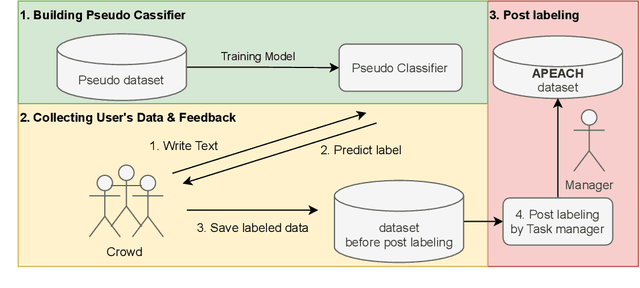
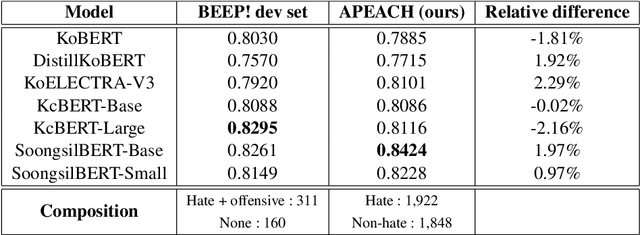
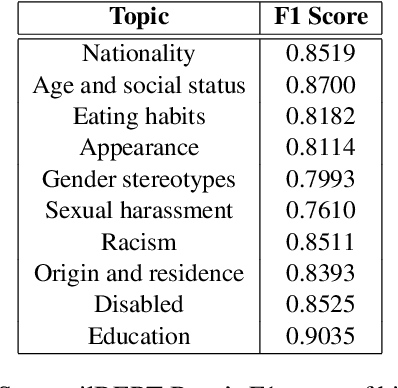
Detecting toxic or pejorative expressions in online communities has become one of the main concerns for preventing the users' mental harm. This led to the development of large-scale hate speech detection datasets of various domains, which are mainly built upon web-crawled texts with labels by crowd workers. However, for languages other than English, researchers might have to rely on only a small-sized corpus due to the lack of data-driven research of hate speech detection. This sometimes misleads the evaluation of prevalently used pretrained language models (PLMs) such as BERT, given that PLMs often share the domain of pretraining corpus with the evaluation set, resulting in over-representation of the detection performance. Also, the scope of pejorative expressions might be restricted if the dataset is built on a single domain text. To alleviate the above problems in Korean hate speech detection, we propose APEACH,a method that allows the collection of hate speech generated by unspecified users. By controlling the crowd-generation of hate speech and adding only a minimum post-labeling, we create a corpus that enables the generalizable and fair evaluation of hate speech detection regarding text domain and topic. We Compare our outcome with prior work on an annotation-based toxic news comment dataset using publicly available PLMs. We check that our dataset is less sensitive to the lexical overlap between the evaluation set and pretraining corpus of PLMs, showing that it helps mitigate the unexpected under/over-representation of model performance. We distribute our dataset publicly online to further facilitate the general-domain hate speech detection in Korean.
Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates
Aug 18, 2021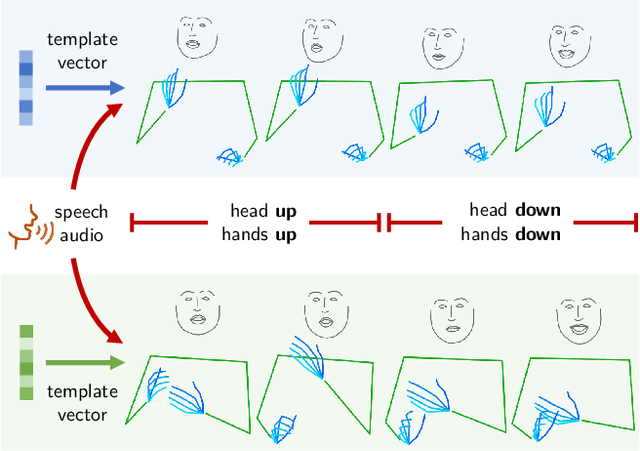
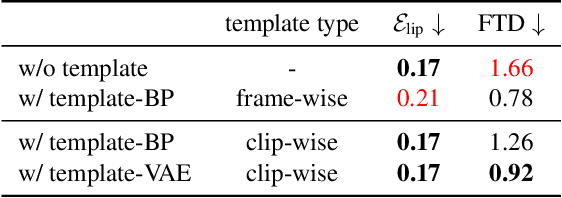
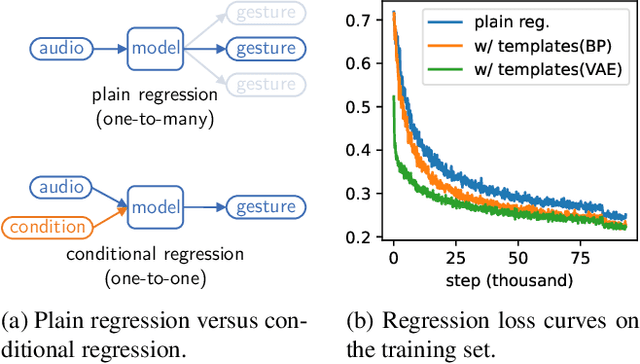

Co-speech gesture generation is to synthesize a gesture sequence that not only looks real but also matches with the input speech audio. Our method generates the movements of a complete upper body, including arms, hands, and the head. Although recent data-driven methods achieve great success, challenges still exist, such as limited variety, poor fidelity, and lack of objective metrics. Motivated by the fact that the speech cannot fully determine the gesture, we design a method that learns a set of gesture template vectors to model the latent conditions, which relieve the ambiguity. For our method, the template vector determines the general appearance of a generated gesture sequence, while the speech audio drives subtle movements of the body, both indispensable for synthesizing a realistic gesture sequence. Due to the intractability of an objective metric for gesture-speech synchronization, we adopt the lip-sync error as a proxy metric to tune and evaluate the synchronization ability of our model. Extensive experiments show the superiority of our method in both objective and subjective evaluations on fidelity and synchronization.