 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Approach for Building Production-Grade Conversational Agents with Workflow Graphs
May 29, 2025The advancement of Large Language Models (LLMs) has led to significant improvements in various service domains, including search, recommendation, and chatbot applications. However, applying state-of-the-art (SOTA) research to industrial settings presents challenges, as it requires maintaining flexible conversational abilities while also strictly complying with service-specific constraints. This can be seen as two conflicting requirements due to the probabilistic nature of LLMs. In this paper, we propose our approach to addressing this challenge and detail the strategies we employed to overcome their inherent limitations in real-world applications. We conduct a practical case study of a conversational agent designed for the e-commerce domain, detailing our implementation workflow and optimizations. Our findings provide insights into bridging the gap between academic research and real-world application, introducing a framework for developing scalable, controllable, and reliable AI-driven agents.
APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
Feb 25, 2022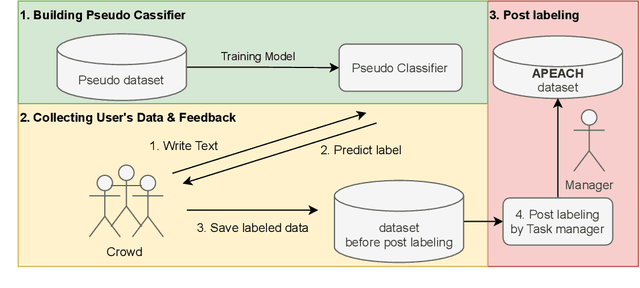
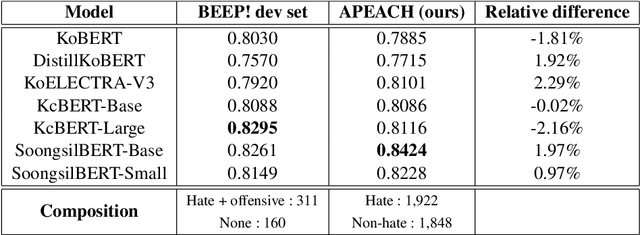
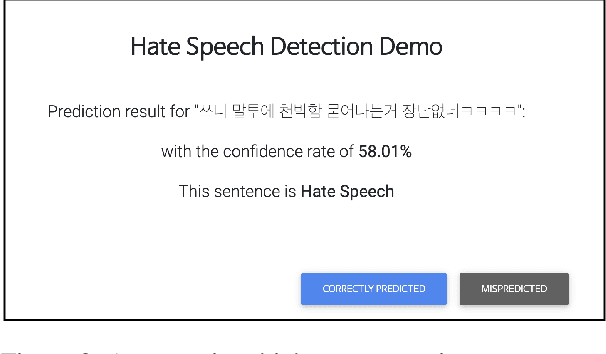
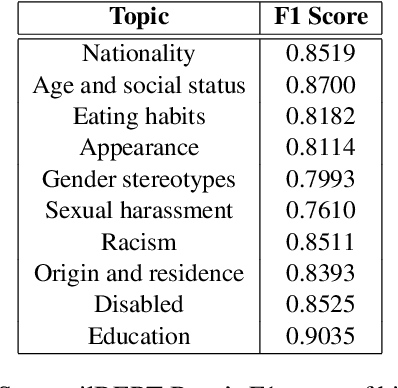
Detecting toxic or pejorative expressions in online communities has become one of the main concerns for preventing the users' mental harm. This led to the development of large-scale hate speech detection datasets of various domains, which are mainly built upon web-crawled texts with labels by crowd workers. However, for languages other than English, researchers might have to rely on only a small-sized corpus due to the lack of data-driven research of hate speech detection. This sometimes misleads the evaluation of prevalently used pretrained language models (PLMs) such as BERT, given that PLMs often share the domain of pretraining corpus with the evaluation set, resulting in over-representation of the detection performance. Also, the scope of pejorative expressions might be restricted if the dataset is built on a single domain text. To alleviate the above problems in Korean hate speech detection, we propose APEACH,a method that allows the collection of hate speech generated by unspecified users. By controlling the crowd-generation of hate speech and adding only a minimum post-labeling, we create a corpus that enables the generalizable and fair evaluation of hate speech detection regarding text domain and topic. We Compare our outcome with prior work on an annotation-based toxic news comment dataset using publicly available PLMs. We check that our dataset is less sensitive to the lexical overlap between the evaluation set and pretraining corpus of PLMs, showing that it helps mitigate the unexpected under/over-representation of model performance. We distribute our dataset publicly online to further facilitate the general-domain hate speech detection in Korean.