 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQRA 2026: Interspeech Challenge on Automatic Assessment Pronunciation for Modern Standard Arabic (MSA)
Mar 31, 2026We present the findings of the second edition of the IQRA Interspeech Challenge, a challenge on automatic Mispronunciation Detection and Diagnosis (MDD) for Modern Standard Arabic (MSA). Building on the previous edition, this iteration introduces \textbf{Iqra\_Extra\_IS26}, a new dataset of authentic human mispronounced speech, complementing the existing training and evaluation resources. Submitted systems employed a diverse range of approaches, spanning CTC-based self-supervised learning models, two-stage fine-tuning strategies, and using large audio-language models. Compared to the first edition, we observe a substantial jump of \textbf{0.28 in F1-score}, attributable both to novel architectures and modeling strategies proposed by participants and to the additional authentic mispronunciation data made available. These results demonstrate the growing maturity of Arabic MDD research and establish a stronger foundation for future work in Arabic pronunciation assessment.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025



We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
Auto-Landmark: Acoustic Landmark Dataset and Open-Source Toolkit for Landmark Extraction
Sep 12, 2024



In the speech signal, acoustic landmarks identify times when the acoustic manifestations of the linguistically motivated distinctive features are most salient. Acoustic landmarks have been widely applied in various domains, including speech recognition, speech depression detection, clinical analysis of speech abnormalities, and the detection of disordered speech. However, there is currently no dataset available that provides precise timing information for landmarks, which has been proven to be crucial for downstream applications involving landmarks. In this paper, we selected the most useful acoustic landmarks based on previous research and annotated the TIMIT dataset with them, based on a combination of phoneme boundary information and manual inspection. Moreover, previous landmark extraction tools were not open source or benchmarked, so to address this, we developed an open source Python-based landmark extraction tool and established a series of landmark detection baselines. The first of their kinds, the dataset with landmark precise timing information, landmark extraction tool and baselines are designed to support a wide variety of future research.
Rethinking Mamba in Speech Processing by Self-Supervised Models
Sep 11, 2024



The Mamba-based model has demonstrated outstanding performance across tasks in computer vision, natural language processing, and speech processing. However, in the realm of speech processing, the Mamba-based model's performance varies across different tasks. For instance, in tasks such as speech enhancement and spectrum reconstruction, the Mamba model performs well when used independently. However, for tasks like speech recognition, additional modules are required to surpass the performance of attention-based models. We propose the hypothesis that the Mamba-based model excels in "reconstruction" tasks within speech processing. However, for "classification tasks" such as Speech Recognition, additional modules are necessary to accomplish the "reconstruction" step. To validate our hypothesis, we analyze the previous Mamba-based Speech Models from an information theory perspective. Furthermore, we leveraged the properties of HuBERT in our study. We trained a Mamba-based HuBERT model, and the mutual information patterns, along with the model's performance metrics, confirmed our assumptions.
Phonological Level wav2vec2-based Mispronunciation Detection and Diagnosis Method
Nov 13, 2023



The automatic identification and analysis of pronunciation errors, known as Mispronunciation Detection and Diagnosis (MDD) plays a crucial role in Computer Aided Pronunciation Learning (CAPL) tools such as Second-Language (L2) learning or speech therapy applications. Existing MDD methods relying on analysing phonemes can only detect categorical errors of phonemes that have an adequate amount of training data to be modelled. With the unpredictable nature of the pronunciation errors of non-native or disordered speakers and the scarcity of training datasets, it is unfeasible to model all types of mispronunciations. Moreover, phoneme-level MDD approaches have a limited ability to provide detailed diagnostic information about the error made. In this paper, we propose a low-level MDD approach based on the detection of speech attribute features. Speech attribute features break down phoneme production into elementary components that are directly related to the articulatory system leading to more formative feedback to the learner. We further propose a multi-label variant of the Connectionist Temporal Classification (CTC) approach to jointly model the non-mutually exclusive speech attributes using a single model. The pre-trained wav2vec2 model was employed as a core model for the speech attribute detector. The proposed method was applied to L2 speech corpora collected from English learners from different native languages. The proposed speech attribute MDD method was further compared to the traditional phoneme-level MDD and achieved a significantly lower False Acceptance Rate (FAR), False Rejection Rate (FRR), and Diagnostic Error Rate (DER) over all speech attributes compared to the phoneme-level equivalent.
Improving Children's Speech Recognition by Fine-tuning Self-supervised Adult Speech Representations
Nov 14, 2022Children's speech recognition is a vital, yet largely overlooked domain when building inclusive speech technologies. The major challenge impeding progress in this domain is the lack of adequate child speech corpora; however, recent advances in self-supervised learning have created a new opportunity for overcoming this problem of data scarcity. In this paper, we leverage self-supervised adult speech representations and use three well-known child speech corpora to build models for children's speech recognition. We assess the performance of fine-tuning on both native and non-native children's speech, examine the effect of cross-domain child corpora, and investigate the minimum amount of child speech required to fine-tune a model which outperforms a state-of-the-art adult model. We also analyze speech recognition performance across children's ages. Our results demonstrate that fine-tuning with cross-domain child corpora leads to relative improvements of up to 46.08% and 45.53% for native and non-native child speech respectively, and absolute improvements of 14.70% and 31.10%. We also show that with as little as 5 hours of transcribed children's speech, it is possible to fine-tune a children's speech recognition system that outperforms a state-of-the-art adult model fine-tuned on 960 hours of adult speech.
Speaker- and Age-Invariant Training for Child Acoustic Modeling Using Adversarial Multi-Task Learning
Oct 19, 2022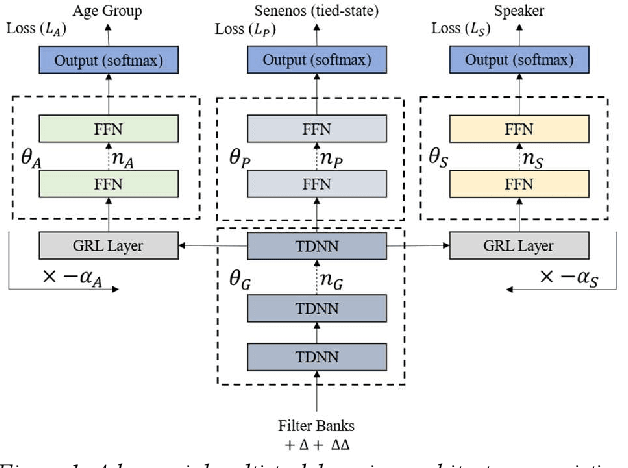
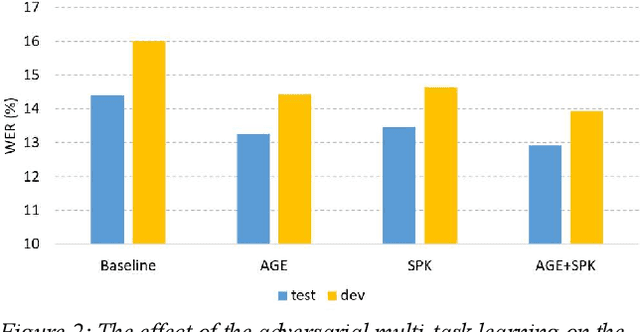
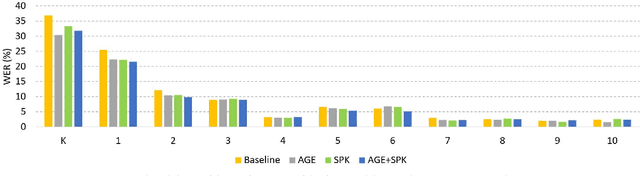
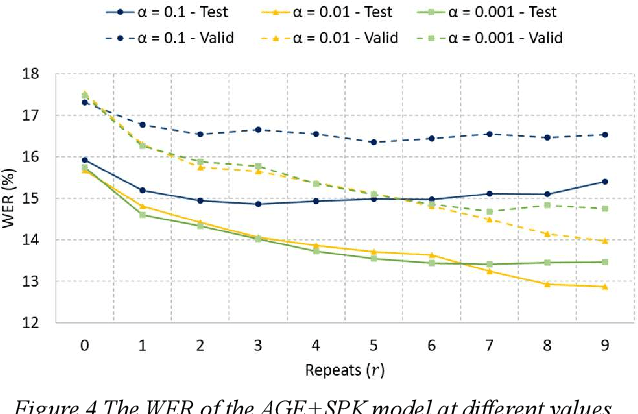
One of the major challenges in acoustic modelling of child speech is the rapid changes that occur in the children's articulators as they grow up, their differing growth rates and the subsequent high variability in the same age group. These high acoustic variations along with the scarcity of child speech corpora have impeded the development of a reliable speech recognition system for children. In this paper, a speaker- and age-invariant training approach based on adversarial multi-task learning is proposed. The system consists of one generator shared network that learns to generate speaker- and age-invariant features connected to three discrimination networks, for phoneme, age, and speaker. The generator network is trained to minimize the phoneme-discrimination loss and maximize the speaker- and age-discrimination losses in an adversarial multi-task learning fashion. The generator network is a Time Delay Neural Network (TDNN) architecture while the three discriminators are feed-forward networks. The system was applied to the OGI speech corpora and achieved a 13% reduction in the WER of the ASR.
Deep Recurrent Electricity Theft Detection in AMI Networks with Random Tuning of Hyper-parameters
Sep 06, 2018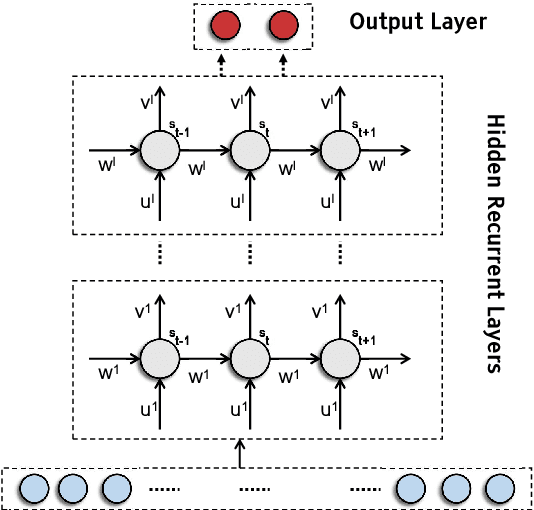

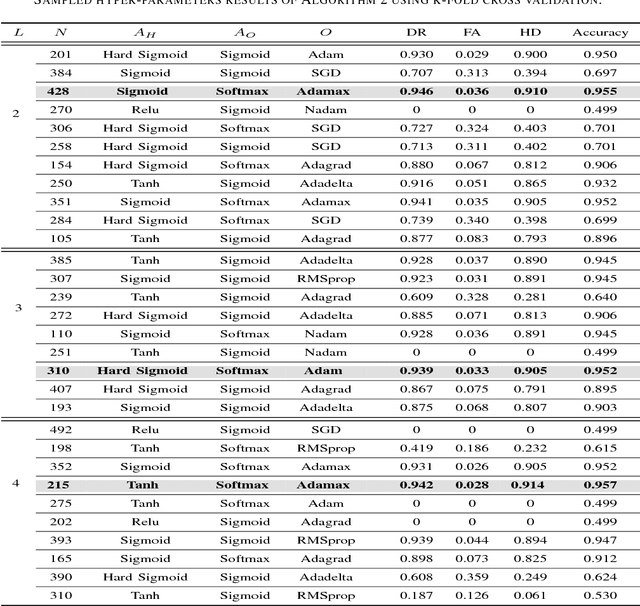
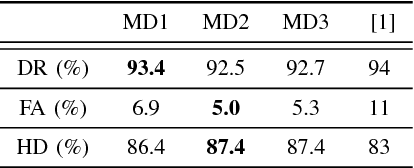
Modern smart grids rely on advanced metering infrastructure (AMI) networks for monitoring and billing purposes. However, such an approach suffers from electricity theft cyberattacks. Different from the existing research that utilizes shallow, static, and customer-specific-based electricity theft detectors, this paper proposes a generalized deep recurrent neural network (RNN)-based electricity theft detector that can effectively thwart these cyberattacks. The proposed model exploits the time series nature of the customers' electricity consumption to implement a gated recurrent unit (GRU)-RNN, hence, improving the detection performance. In addition, the proposed RNN-based detector adopts a random search analysis in its learning stage to appropriately fine-tune its hyper-parameters. Extensive test studies are carried out to investigate the detector's performance using publicly available real data of 107,200 energy consumption days from 200 customers. Simulation results demonstrate the superior performance of the proposed detector compared with state-of-the-art electricity theft detectors.