 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Large Raw Emotional Dataset with Aggregation Mechanism
Dec 23, 2022
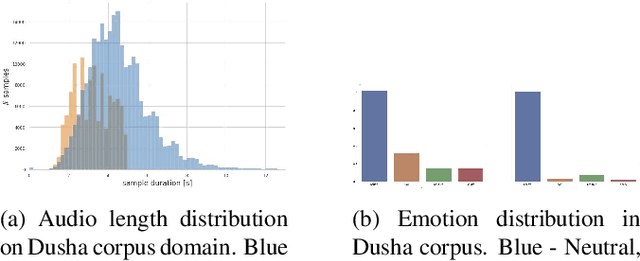


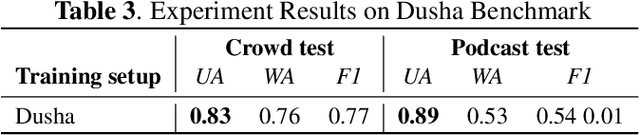
We present a new data set for speech emotion recognition (SER) tasks called Dusha. The corpus contains approximately 350 hours of data, more than 300 000 audio recordings with Russian speech and their transcripts. Therefore it is the biggest open bi-modal data collection for SER task nowadays. It is annotated using a crowd-sourcing platform and includes two subsets: acted and real-life. Acted subset has a more balanced class distribution than the unbalanced real-life part consisting of audio podcasts. So the first one is suitable for model pre-training, and the second is elaborated for fine-tuning purposes, model approbation, and validation. This paper describes pre-processing routine, annotation, and experiment with a baseline model to demonstrate some actual metrics which could be obtained with the Dusha data set.
Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022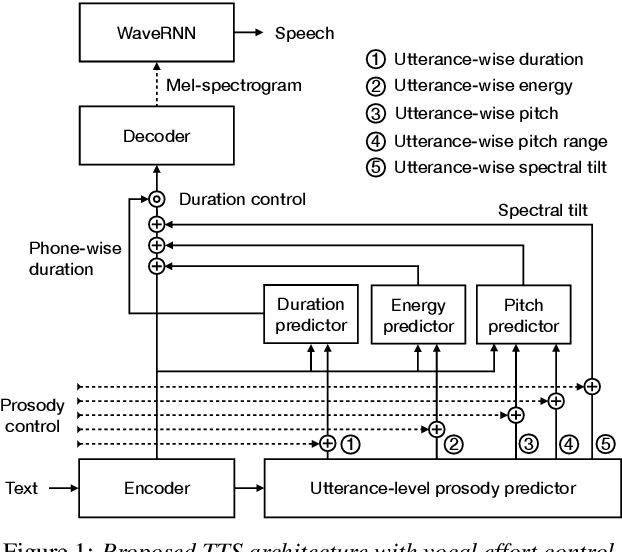
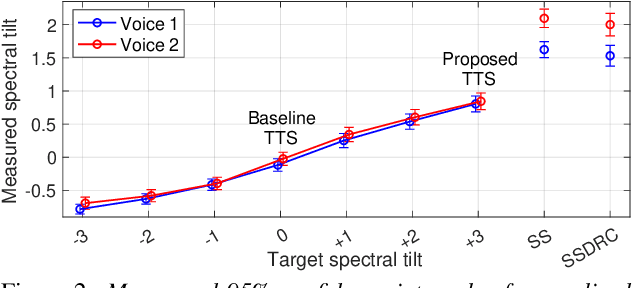
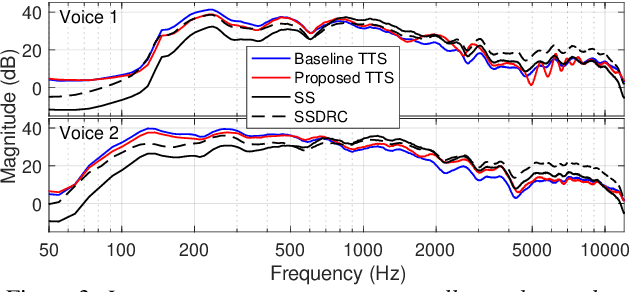
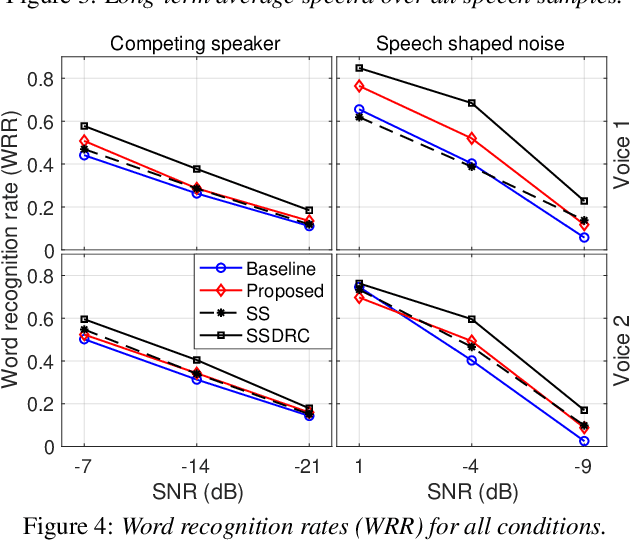
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Multi-Channel Speech Denoising for Machine Ears
Feb 17, 2022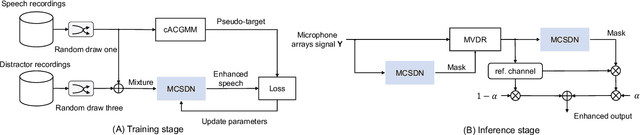
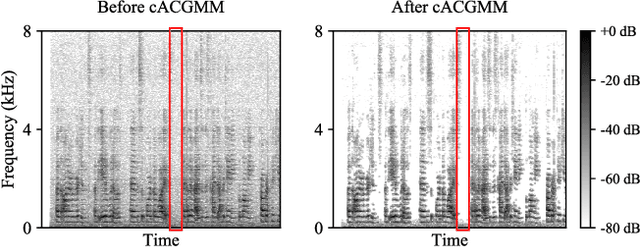
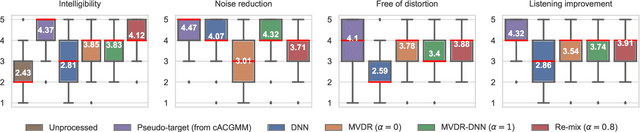
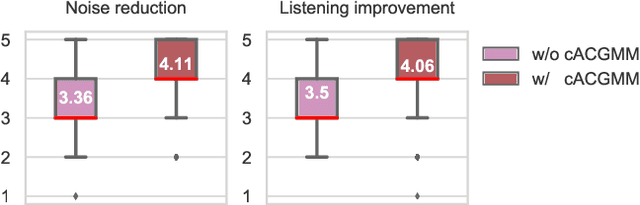
This work describes a speech denoising system for machine ears that aims to improve speech intelligibility and the overall listening experience in noisy environments. We recorded approximately 100 hours of audio data with reverberation and moderate environmental noise using a pair of microphone arrays placed around each of the two ears and then mixed sound recordings to simulate adverse acoustic scenes. Then, we trained a multi-channel speech denoising network (MCSDN) on the mixture of recordings. To improve the training, we employ an unsupervised method, complex angular central Gaussian mixture model (cACGMM), to acquire cleaner speech from noisy recordings to serve as the learning target. We propose a MCSDN-Beamforming-MCSDN framework in the inference stage. The results of the subjective evaluation show that the cACGMM improves the training data, resulting in better noise reduction and user preference, and the entire system improves the intelligibility and listening experience in noisy situations.
Analyzing Hate Speech Data along Racial, Gender and Intersectional Axes
May 18, 2022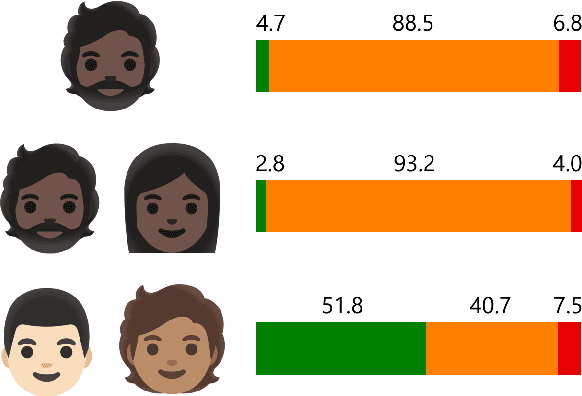


To tackle the rising phenomenon of hate speech, efforts have been made towards data curation and analysis. When it comes to analysis of bias, previous work has focused predominantly on race. In our work, we further investigate bias in hate speech datasets along racial, gender and intersectional axes. We identify strong bias against African American English (AAE), masculine and AAE+Masculine tweets, which are annotated as disproportionately more hateful and offensive than from other demographics. We provide evidence that BERT-based models propagate this bias and show that balancing the training data for these protected attributes can lead to fairer models with regards to gender, but not race.
Can Self-Supervised Learning solve the problem of child speech recognition?
Apr 06, 2022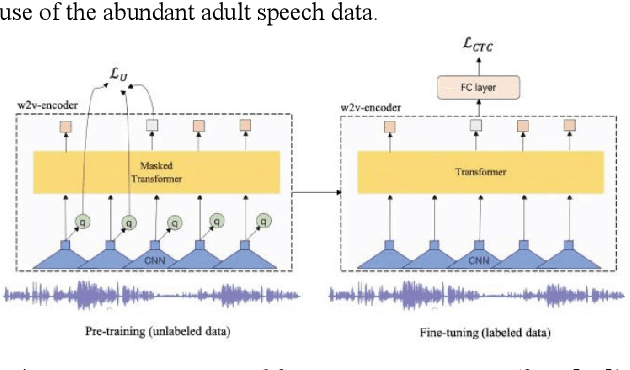
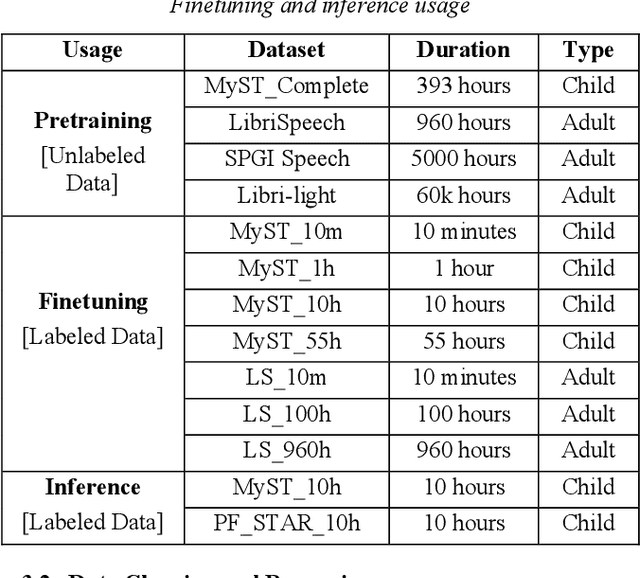
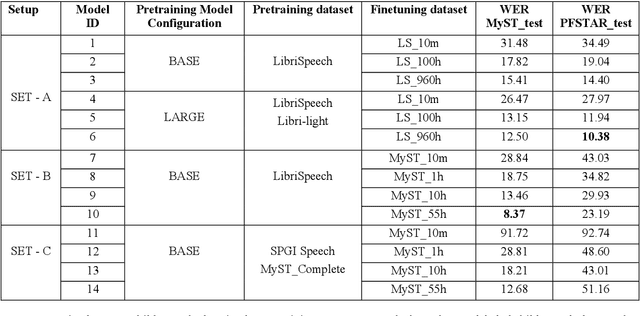
Despite recent advancements in deep learning technologies, Child Speech Recognition remains a challenging task. Current Automatic Speech Recognition (ASR) models required substantial amounts of annotated data for training, which is scarce. In this work, we explore using the ASR model, wav2vec2, with different pretraining and finetuning configurations for self supervised learning (SSL) towards improving automatic child speech recognition. The pretrained wav2vec2 models were finetuned using different amounts of child speech training data to discover the optimum amount of data required to finetune the model for the task of child ASR. Our trained model receives the best word error rate (WER) of 8.37 on the in domain MyST dataset and WER of 10.38 on the out of domain PFSTAR dataset. We do not use any Language Models (LM) in our experiments.
Listening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
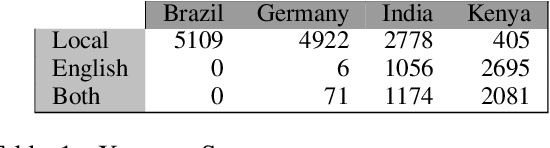

Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.
Improving the Robustness of DistilHuBERT to Unseen Noisy Conditions via Data Augmentation, Curriculum Learning, and Multi-Task Enhancement
Nov 12, 2022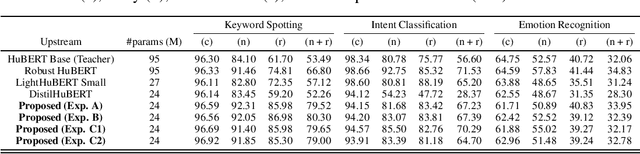
Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.
Distinguishable Speaker Anonymization based on Formant and Fundamental Frequency Scaling
Nov 06, 2022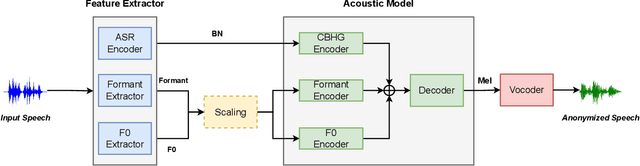

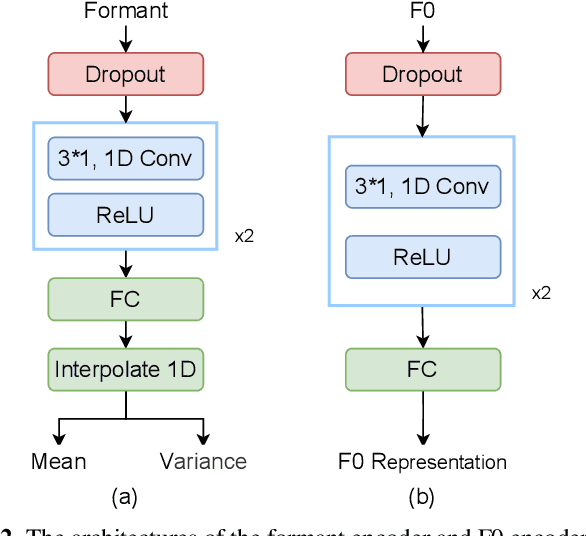

Speech data on the Internet are proliferating exponentially because of the emergence of social media, and the sharing of such personal data raises obvious security and privacy concerns. One solution to mitigate these concerns involves concealing speaker identities before sharing speech data, also referred to as speaker anonymization. In our previous work, we have developed an automatic speaker verification (ASV)-model-free anonymization framework to protect speaker privacy while preserving speech intelligibility. Although the framework ranked first place in VoicePrivacy 2022 challenge, the anonymization was imperfect, since the speaker distinguishability of the anonymized speech was deteriorated. To address this issue, in this paper, we directly model the formant distribution and fundamental frequency (F0) to represent speaker identity and anonymize the source speech by the uniformly scaling formant and F0. By directly scaling the formant and F0, the speaker distinguishability degradation of the anonymized speech caused by the introduction of other speakers is prevented. The experimental results demonstrate that our proposed framework can improve the speaker distinguishability and significantly outperforms our previous framework in voice distinctiveness. Furthermore, our proposed method also can trade off the privacy-utility by using different scaling factors.
Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
May 30, 2022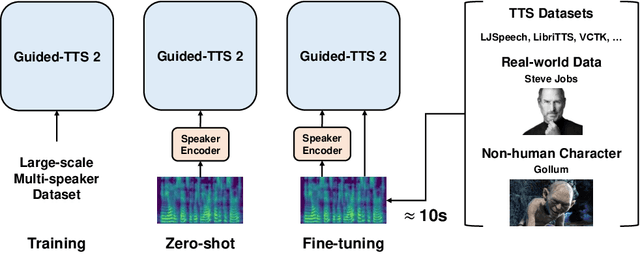
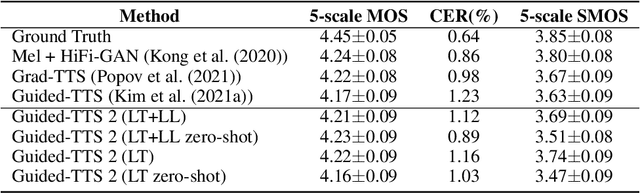
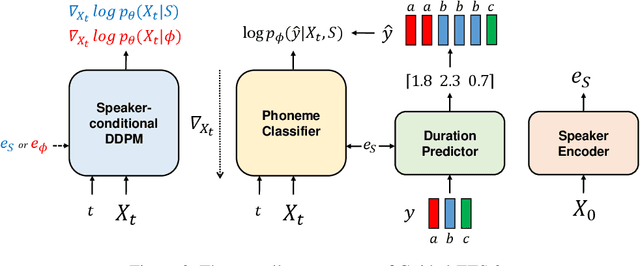
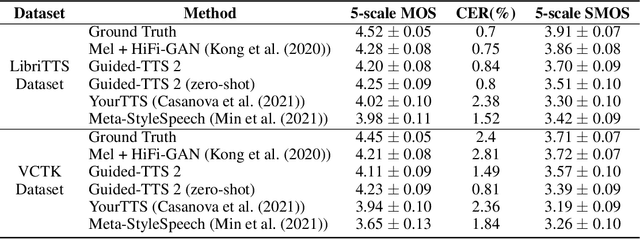
We propose Guided-TTS 2, a diffusion-based generative model for high-quality adaptive TTS using untranscribed data. Guided-TTS 2 combines a speaker-conditional diffusion model with a speaker-dependent phoneme classifier for adaptive text-to-speech. We train the speaker-conditional diffusion model on large-scale untranscribed datasets for a classifier-free guidance method and further fine-tune the diffusion model on the reference speech of the target speaker for adaptation, which only takes 40 seconds. We demonstrate that Guided-TTS 2 shows comparable performance to high-quality single-speaker TTS baselines in terms of speech quality and speaker similarity with only a ten-second untranscribed data. We further show that Guided-TTS 2 outperforms adaptive TTS baselines on multi-speaker datasets even with a zero-shot adaptation setting. Guided-TTS 2 can adapt to a wide range of voices only using untranscribed speech, which enables adaptive TTS with the voice of non-human characters such as Gollum in \textit{"The Lord of the Rings"}.
STUDIES: Corpus of Japanese Empathetic Dialogue Speech Towards Friendly Voice Agent
Mar 28, 2022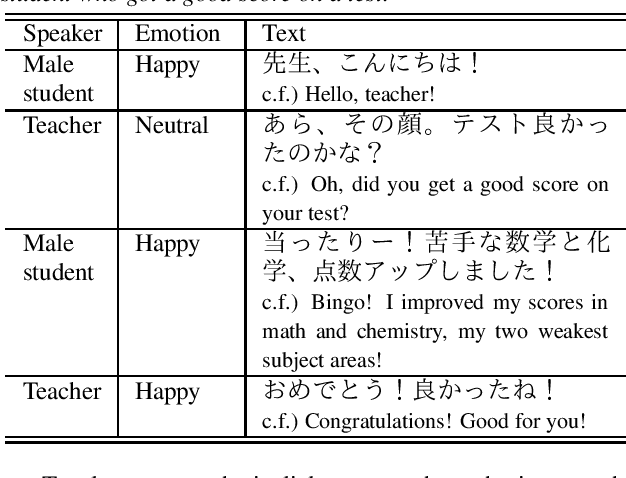
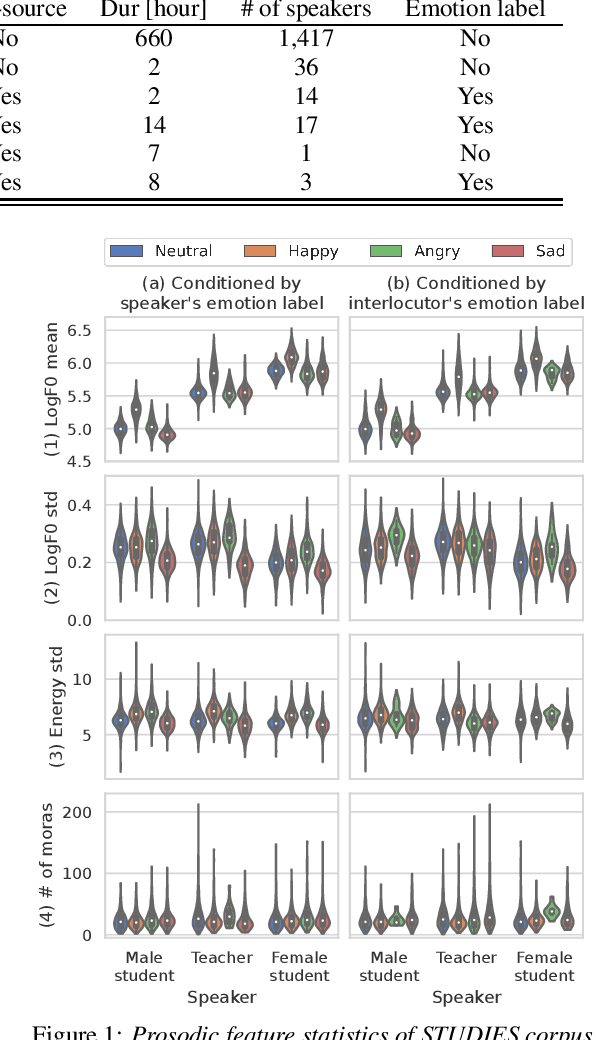
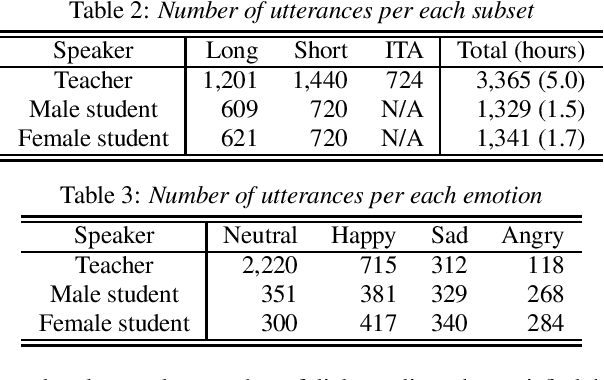
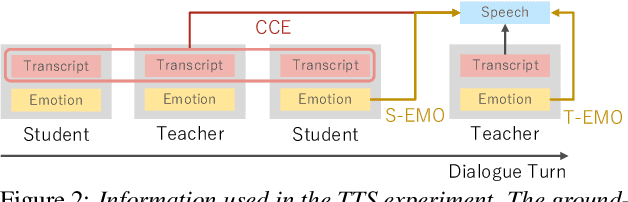
We present STUDIES, a new speech corpus for developing a voice agent that can speak in a friendly manner. Humans naturally control their speech prosody to empathize with each other. By incorporating this "empathetic dialogue" behavior into a spoken dialogue system, we can develop a voice agent that can respond to a user more naturally. We designed the STUDIES corpus to include a speaker who speaks with empathy for the interlocutor's emotion explicitly. We describe our methodology to construct an empathetic dialogue speech corpus and report the analysis results of the STUDIES corpus. We conducted a text-to-speech experiment to initially investigate how we can develop more natural voice agent that can tune its speaking style corresponding to the interlocutor's emotion. The results show that the use of interlocutor's emotion label and conversational context embedding can produce speech with the same degree of naturalness as that synthesized by using the agent's emotion label. Our project page of the STUDIES corpus is http://sython.org/Corpus/STUDIES.