 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022
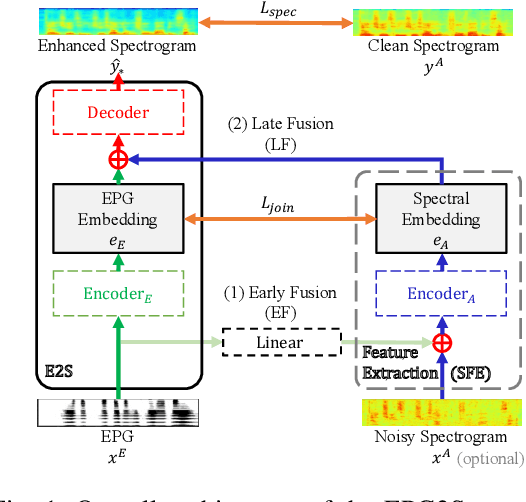
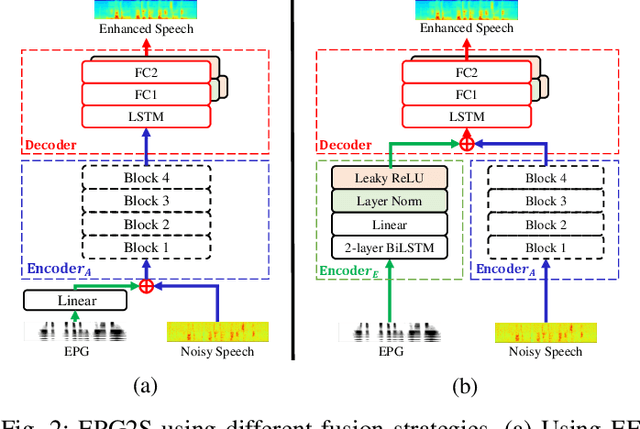
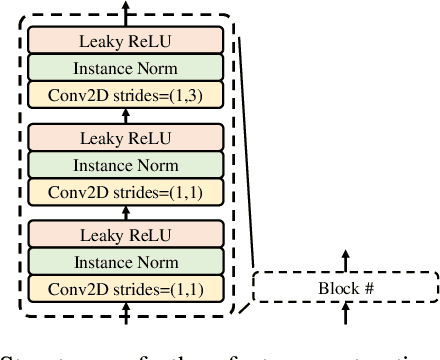
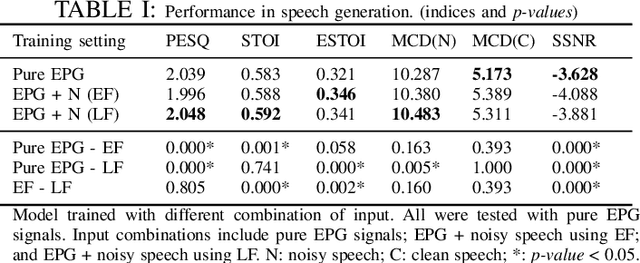
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.
Cross-modal Audio-visual Co-learning for Text-independent Speaker Verification
Feb 22, 2023
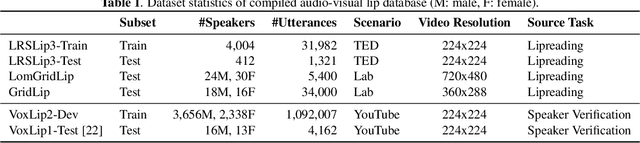
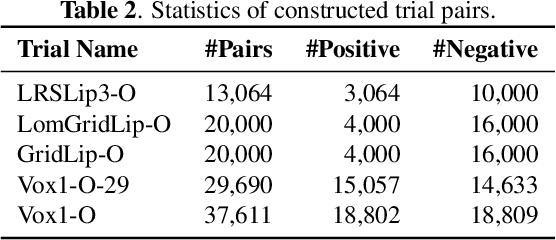
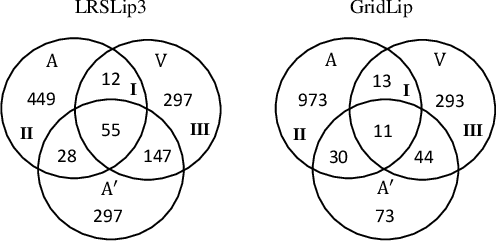
Visual speech (i.e., lip motion) is highly related to auditory speech due to the co-occurrence and synchronization in speech production. This paper investigates this correlation and proposes a cross-modal speech co-learning paradigm. The primary motivation of our cross-modal co-learning method is modeling one modality aided by exploiting knowledge from another modality. Specifically, two cross-modal boosters are introduced based on an audio-visual pseudo-siamese structure to learn the modality-transformed correlation. Inside each booster, a max-feature-map embedded Transformer variant is proposed for modality alignment and enhanced feature generation. The network is co-learned both from scratch and with pretrained models. Experimental results on the LRSLip3, GridLip, LomGridLip, and VoxLip datasets demonstrate that our proposed method achieves 60% and 20% average relative performance improvement over independently trained audio-only/visual-only and baseline fusion systems, respectively.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 24, 2023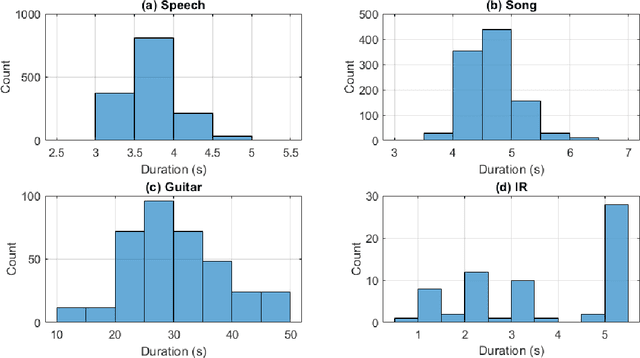
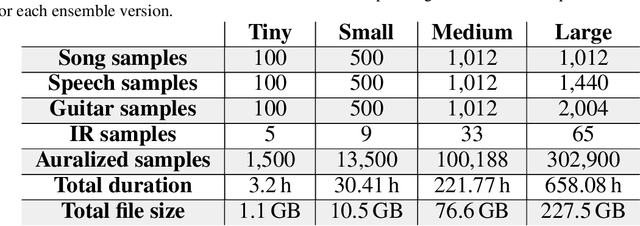
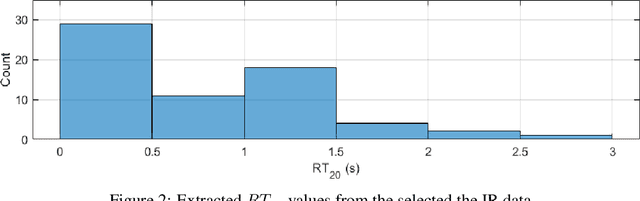
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Evaluating gesture-generation in a large-scale open challenge: The GENEA Challenge 2022
Mar 15, 2023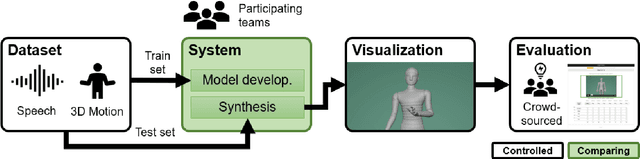
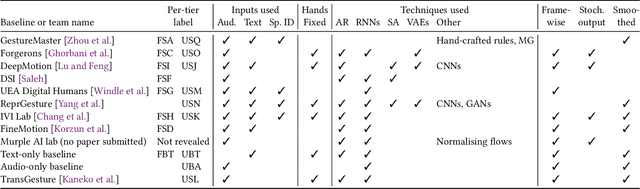
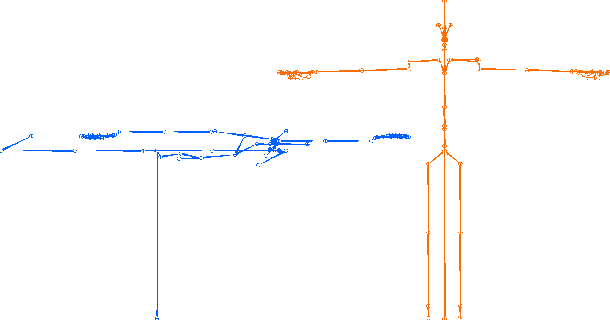
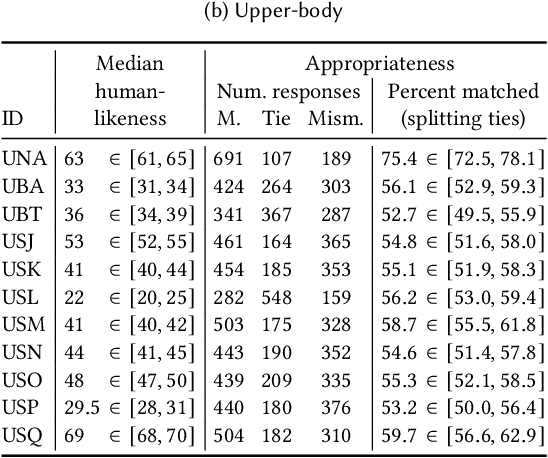
This paper reports on the second GENEA Challenge to benchmark data-driven automatic co-speech gesture generation. Participating teams used the same speech and motion dataset to build gesture-generation systems. Motion generated by all these systems was rendered to video using a standardised visualisation pipeline and evaluated in several large, crowdsourced user studies. Unlike when comparing different research papers, differences in results are here only due to differences between methods, enabling direct comparison between systems. The dataset was based on 18 hours of full-body motion capture, including fingers, of different persons engaging in a dyadic conversation. Ten teams participated in the challenge across two tiers: full-body and upper-body gesticulation. For each tier, we evaluated both the human-likeness of the gesture motion and its appropriateness for the specific speech signal. Our evaluations decouple human-likeness from gesture appropriateness, which has been a difficult problem in the field. The evaluation results are a revolution, and a revelation. Some synthetic conditions are rated as significantly more human-like than human motion capture. To the best of our knowledge, this has never been shown before on a high-fidelity avatar. On the other hand, all synthetic motion is found to be vastly less appropriate for the speech than the original motion-capture recordings. We also find that conventional objective metrics do not correlate well with subjective human-likeness ratings in this large evaluation. The one exception is the Fr\'echet gesture distance (FGD), which achieves a Kendall's tau rank correlation of around -0.5. Based on the challenge results we formulate numerous recommendations for system building and evaluation.
Cascading and Direct Approaches to Unsupervised Constituency Parsing on Spoken Sentences
Mar 15, 2023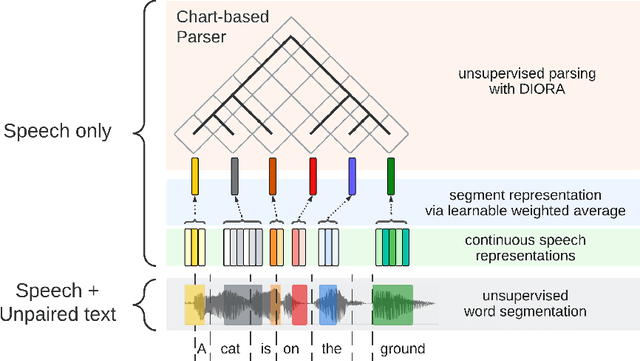
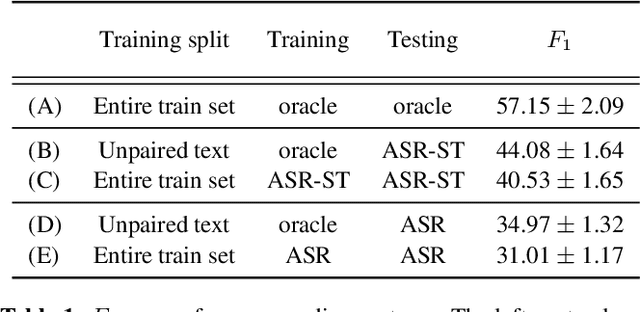
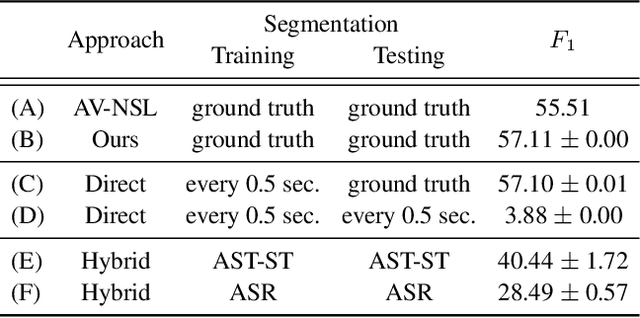
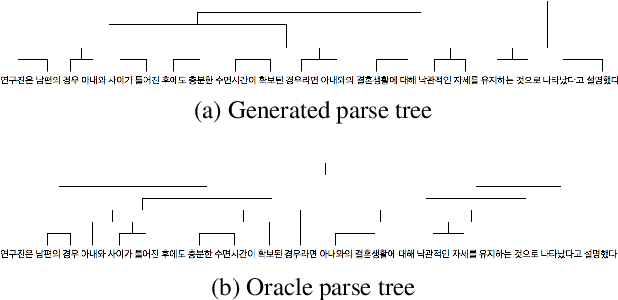
Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
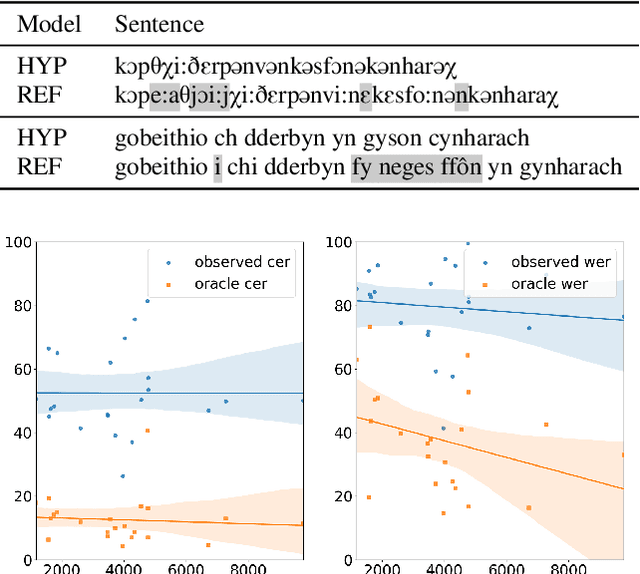
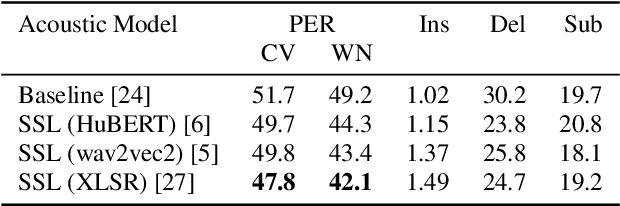
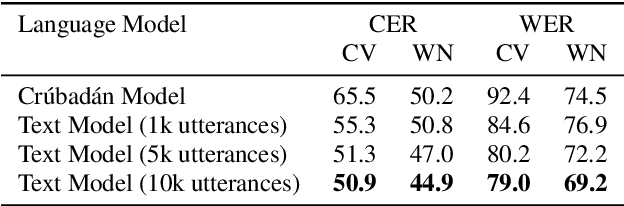
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022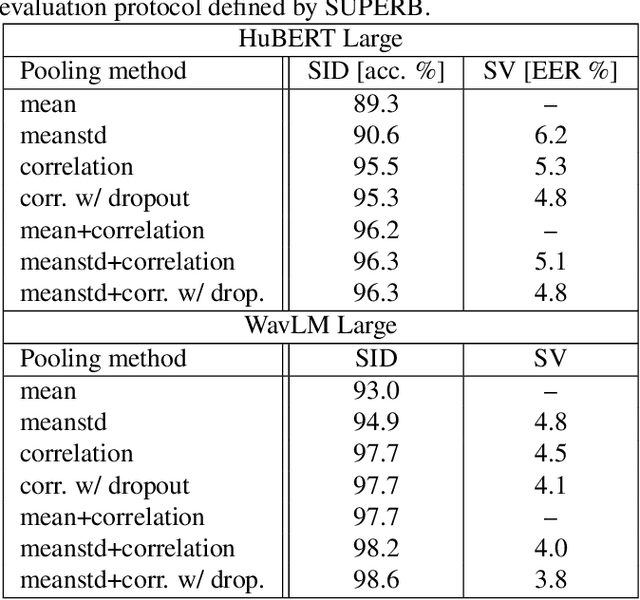
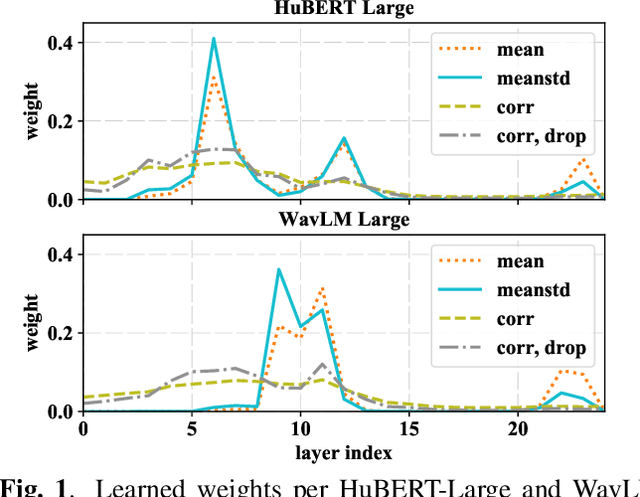
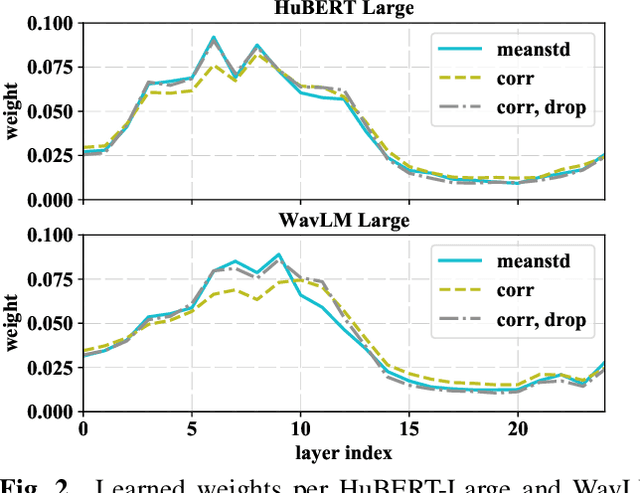
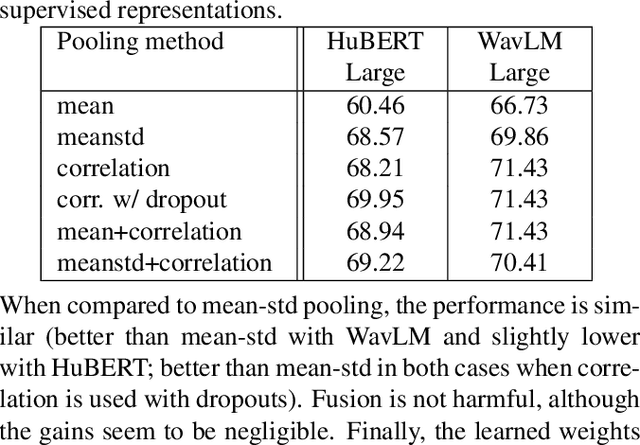
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
DualVoice: Speech Interaction that Discriminates between Normal and Whispered Voice Input
Aug 22, 2022
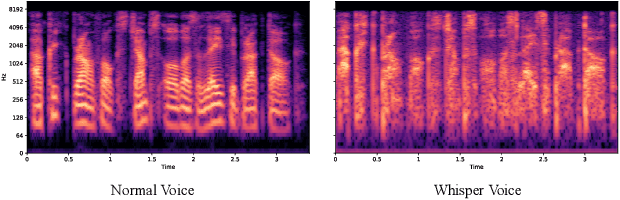
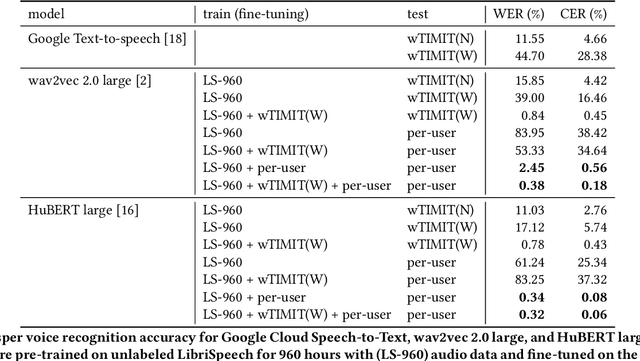
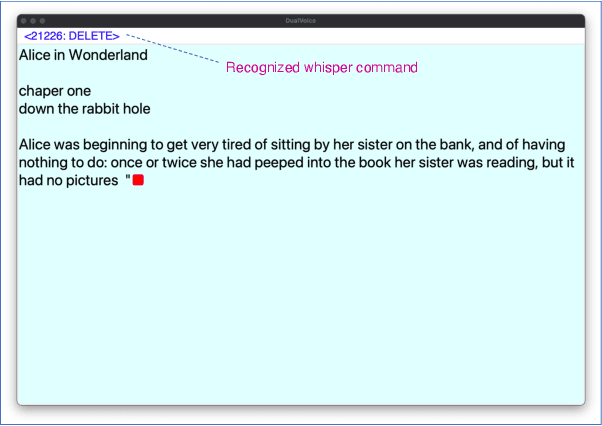
Interactions based on automatic speech recognition (ASR) have become widely used, with speech input being increasingly utilized to create documents. However, as there is no easy way to distinguish between commands being issued and text required to be input in speech, misrecognitions are difficult to identify and correct, meaning that documents need to be manually edited and corrected. The input of symbols and commands is also challenging because these may be misrecognized as text letters. To address these problems, this study proposes a speech interaction method called DualVoice, by which commands can be input in a whispered voice and letters in a normal voice. The proposed method does not require any specialized hardware other than a regular microphone, enabling a complete hands-free interaction. The method can be used in a wide range of situations where speech recognition is already available, ranging from text input to mobile/wearable computing. Two neural networks were designed in this study, one for discriminating normal speech from whispered speech, and the second for recognizing whisper speech. A prototype of a text input system was then developed to show how normal and whispered voice can be used in speech text input. Other potential applications using DualVoice are also discussed.
Memory Augmented Lookup Dictionary based Language Modeling for Automatic Speech Recognition
Dec 30, 2022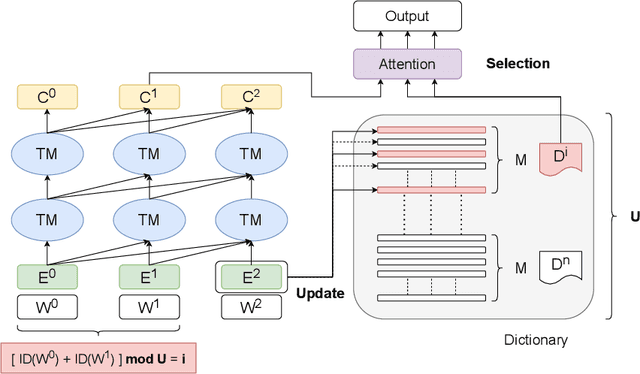
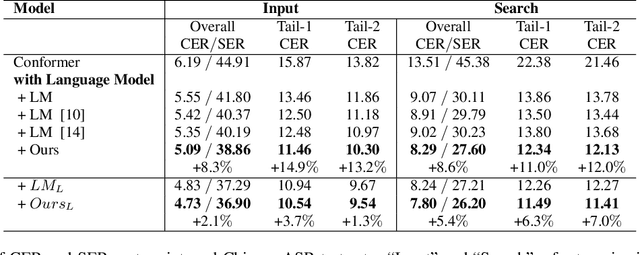
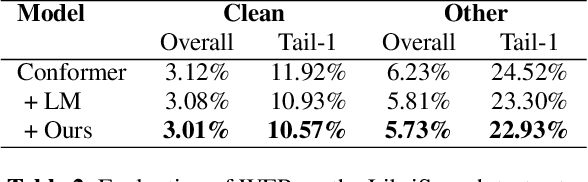
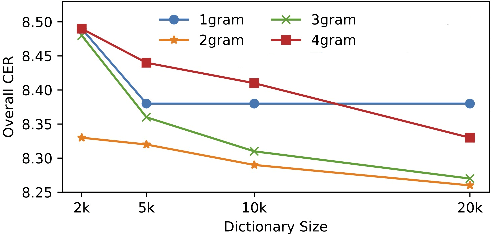
Recent studies have shown that using an external Language Model (LM) benefits the end-to-end Automatic Speech Recognition (ASR). However, predicting tokens that appear less frequently in the training set is still quite challenging. The long-tail prediction problems have been widely studied in many applications, but only been addressed by a few studies for ASR and LMs. In this paper, we propose a new memory augmented lookup dictionary based Transformer architecture for LM. The newly introduced lookup dictionary incorporates rich contextual information in training set, which is vital to correctly predict long-tail tokens. With intensive experiments on Chinese and English data sets, our proposed method is proved to outperform the baseline Transformer LM by a great margin on both word/character error rate and tail tokens error rate. This is achieved without impact on the decoding efficiency. Overall, we demonstrate the effectiveness of our proposed method in boosting the ASR decoding performance, especially for long-tail tokens.
Neural inhibition during speech planning contributes to contrastive hyperarticulation
Sep 25, 2022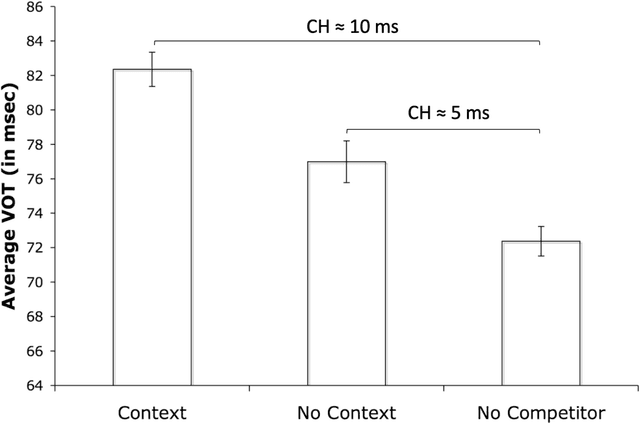
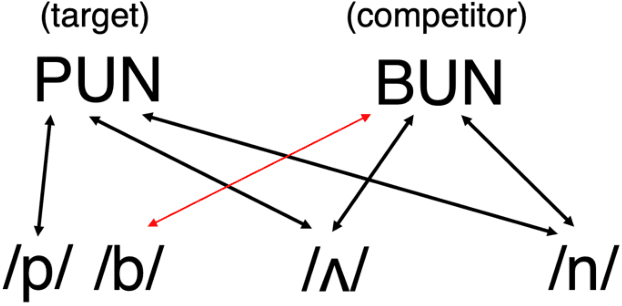
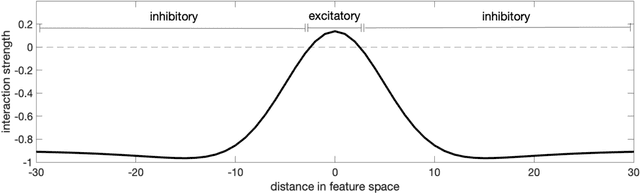
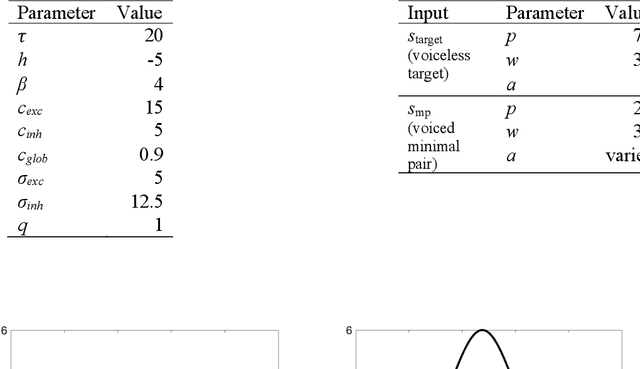
Previous work has demonstrated that words are hyperarticulated on dimensions of speech that differentiate them from a minimal pair competitor. This phenomenon has been termed contrastive hyperarticulation (CH). We present a dynamic neural field (DNF) model of voice onset time (VOT) planning that derives CH from an inhibitory influence of the minimal pair competitor during planning. We test some predictions of the model with a novel experiment investigating CH of voiceless stop consonant VOT in pseudowords. The results demonstrate a CH effect in pseudowords, consistent with a basis for the effect in the real-time planning and production of speech. The scope and magnitude of CH in pseudowords was reduced compared to CH in real words, consistent with a role for interactive activation between lexical and phonological levels of planning. We discuss the potential of our model to unify an apparently disparate set of phenomena, from CH to phonological neighborhood effects to phonetic trace effects in speech errors.