 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpha Divergence Losses for Biometric Verification
Nov 19, 2025Performance in face and speaker verification is largely driven by margin based softmax losses like CosFace and ArcFace. Recently introduced $α$-divergence loss functions offer a compelling alternative, particularly for their ability to induce sparse solutions (when $α>1$). However, integrating an angular margin-crucial for verification tasks-is not straightforward. We find this integration can be achieved in at least two distinct ways: via the reference measure (prior probabilities) or via the logits (unnormalized log-likelihoods). In this paper, we explore both pathways, deriving two novel margin-based $α$-divergence losses: Q-Margin (margin in the reference measure) and A3M (margin in the logits). We identify and address a critical training instability in A3M-caused by the interplay of penalized logits and sparsity-with a simple yet effective prototype re-initialization strategy. Our methods achieve significant performance gains on the challenging IJB-B and IJB-C face verification benchmarks. We demonstrate similarly strong performance in speaker verification on VoxCeleb. Crucially, our models significantly outperform strong baselines at low false acceptance rates (FAR). This capability is crucial for practical high-security applications, such as banking authentication, when minimizing false authentications is paramount.
Speech-based emotion recognition with self-supervised models using attentive channel-wise correlations and label smoothing
Nov 03, 2022When recognizing emotions from speech, we encounter two common problems: how to optimally capture emotion-relevant information from the speech signal and how to best quantify or categorize the noisy subjective emotion labels. Self-supervised pre-trained representations can robustly capture information from speech enabling state-of-the-art results in many downstream tasks including emotion recognition. However, better ways of aggregating the information across time need to be considered as the relevant emotion information is likely to appear piecewise and not uniformly across the signal. For the labels, we need to take into account that there is a substantial degree of noise that comes from the subjective human annotations. In this paper, we propose a novel approach to attentive pooling based on correlations between the representations' coefficients combined with label smoothing, a method aiming to reduce the confidence of the classifier on the training labels. We evaluate our proposed approach on the benchmark dataset IEMOCAP, and demonstrate high performance surpassing that in the literature. The code to reproduce the results is available at github.com/skakouros/s3prl_attentive_correlation.
Extracting speaker and emotion information from self-supervised speech models via channel-wise correlations
Oct 15, 2022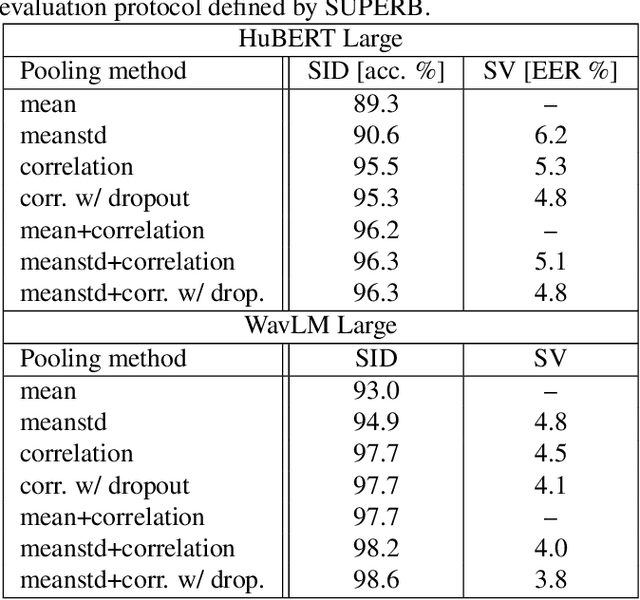
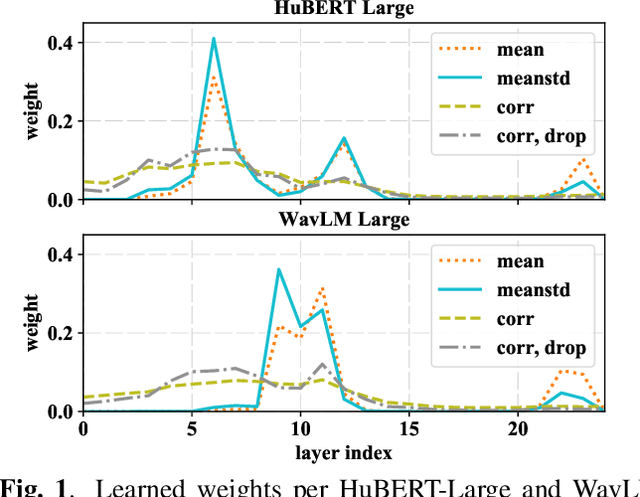
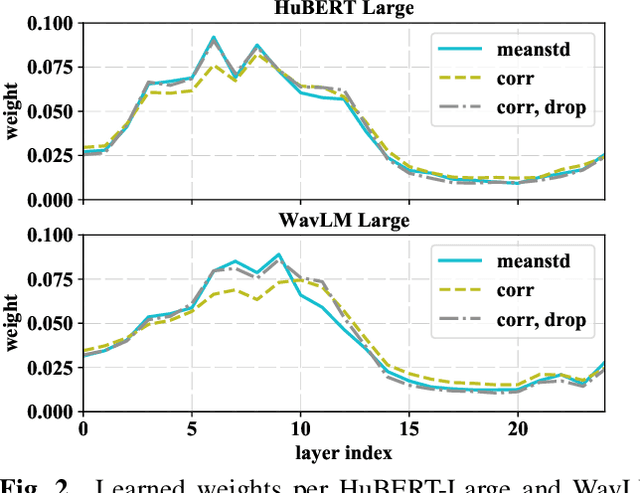
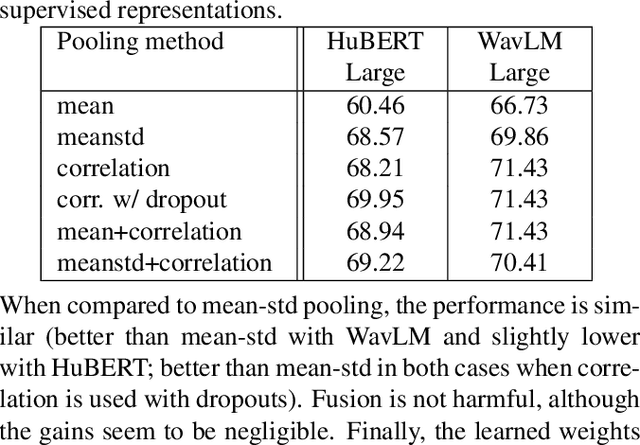
Self-supervised learning of speech representations from large amounts of unlabeled data has enabled state-of-the-art results in several speech processing tasks. Aggregating these speech representations across time is typically approached by using descriptive statistics, and in particular, using the first- and second-order statistics of representation coefficients. In this paper, we examine an alternative way of extracting speaker and emotion information from self-supervised trained models, based on the correlations between the coefficients of the representations - correlation pooling. We show improvements over mean pooling and further gains when the pooling methods are combined via fusion. The code is available at github.com/Lamomal/s3prl_correlation.
An attention-based backend allowing efficient fine-tuning of transformer models for speaker verification
Oct 03, 2022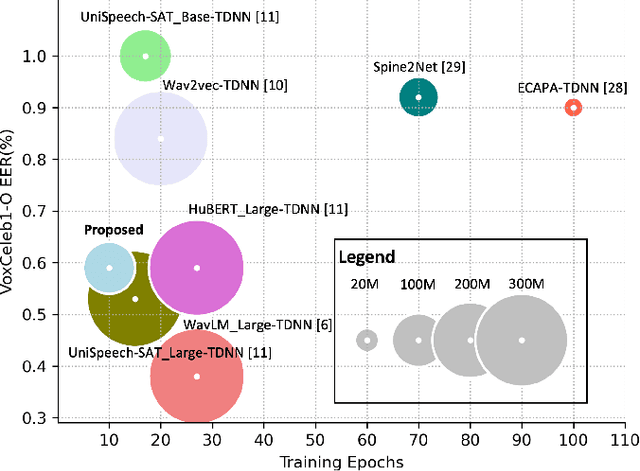

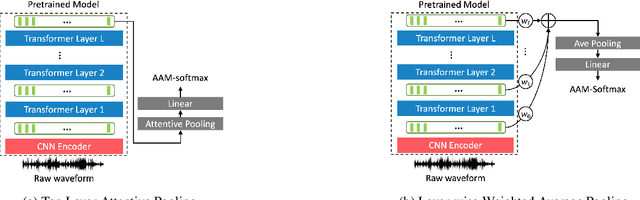

In recent years, self-supervised learning paradigm has received extensive attention due to its great success in various down-stream tasks. However, the fine-tuning strategies for adapting those pre-trained models to speaker verification task have yet to be fully explored. In this paper, we analyze several feature extraction approaches built on top of a pre-trained model, as well as regularization and learning rate schedule to stabilize the fine-tuning process and further boost performance: multi-head factorized attentive pooling is proposed to factorize the comparison of speaker representations into multiple phonetic clusters. We regularize towards the parameters of the pre-trained model and we set different learning rates for each layer of the pre-trained model during fine-tuning. The experimental results show our method can significantly shorten the training time to 4 hours and achieve SOTA performance: 0.59%, 0.79% and 1.77% EER on Vox1-O, Vox1-E and Vox1-H, respectively.
Analyzing speaker verification embedding extractors and back-ends under language and channel mismatch
Mar 19, 2022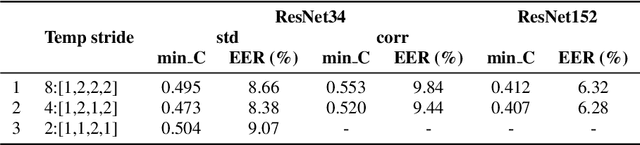
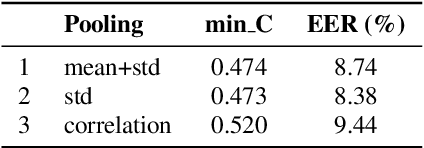
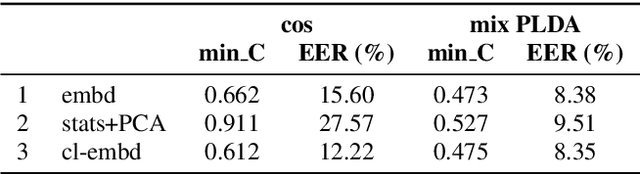
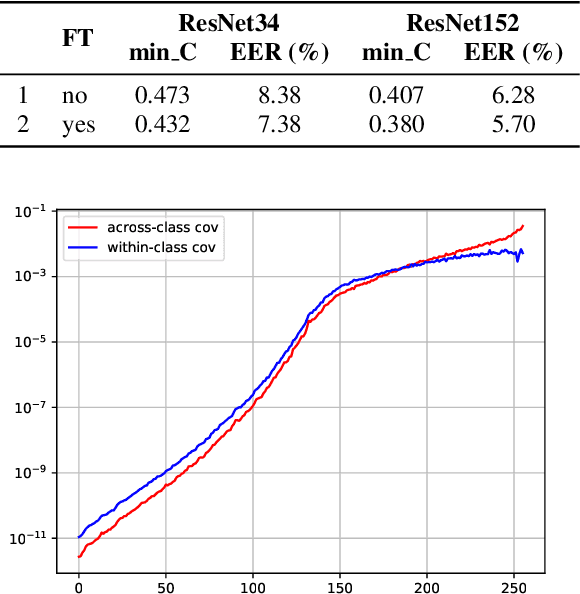
In this paper, we analyze the behavior and performance of speaker embeddings and the back-end scoring model under domain and language mismatch. We present our findings regarding ResNet-based speaker embedding architectures and show that reduced temporal stride yields improved performance. We then consider a PLDA back-end and show how a combination of small speaker subspace, language-dependent PLDA mixture, and nuisance-attribute projection can have a drastic impact on the performance of the system. Besides, we present an efficient way of scoring and fusing class posterior logit vectors recently shown to perform well for speaker verification task. The experiments are performed using the NIST SRE 2021 setup.