 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
HM-Conformer: A Conformer-based audio deepfake detection system with hierarchical pooling and multi-level classification token aggregation methods
Sep 15, 2023
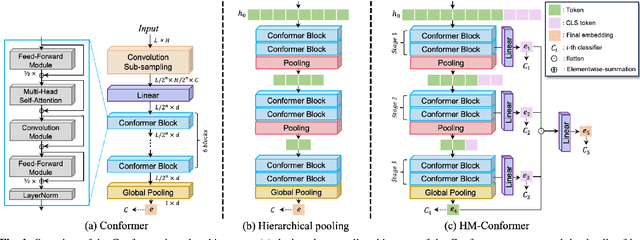

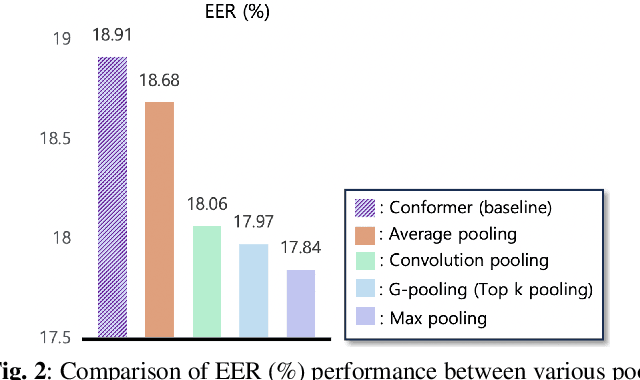

Audio deepfake detection (ADD) is the task of detecting spoofing attacks generated by text-to-speech or voice conversion systems. Spoofing evidence, which helps to distinguish between spoofed and bona-fide utterances, might exist either locally or globally in the input features. To capture these, the Conformer, which consists of Transformers and CNN, possesses a suitable structure. However, since the Conformer was designed for sequence-to-sequence tasks, its direct application to ADD tasks may be sub-optimal. To tackle this limitation, we propose HM-Conformer by adopting two components: (1) Hierarchical pooling method progressively reducing the sequence length to eliminate duplicated information (2) Multi-level classification token aggregation method utilizing classification tokens to gather information from different blocks. Owing to these components, HM-Conformer can efficiently detect spoofing evidence by processing various sequence lengths and aggregating them. In experimental results on the ASVspoof 2021 Deepfake dataset, HM-Conformer achieved a 15.71% EER, showing competitive performance compared to recent systems.
Considerations for Ethical Speech Recognition Datasets
May 03, 2023Speech AI Technologies are largely trained on publicly available datasets or by the massive web-crawling of speech. In both cases, data acquisition focuses on minimizing collection effort, without necessarily taking the data subjects' protection or user needs into consideration. This results to models that are not robust when used on users who deviate from the dominant demographics in the training set, discriminating individuals having different dialects, accents, speaking styles, and disfluencies. In this talk, we use automatic speech recognition as a case study and examine the properties that ethical speech datasets should possess towards responsible AI applications. We showcase diversity issues, inclusion practices, and necessary considerations that can improve trained models, while facilitating model explainability and protecting users and data subjects. We argue for the legal & privacy protection of data subjects, targeted data sampling corresponding to user demographics & needs, appropriate meta data that ensure explainability & accountability in cases of model failure, and the sociotechnical \& situated model design. We hope this talk can inspire researchers \& practitioners to design and use more human-centric datasets in speech technologies and other domains, in ways that empower and respect users, while improving machine learning models' robustness and utility.
Investigating the Utility of Surprisal from Large Language Models for Speech Synthesis Prosody
Jun 16, 2023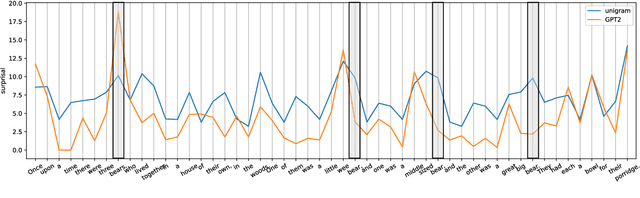
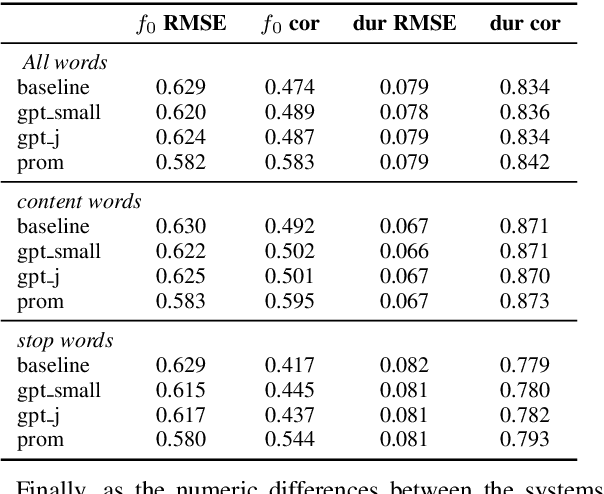
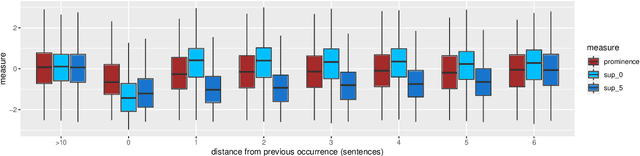
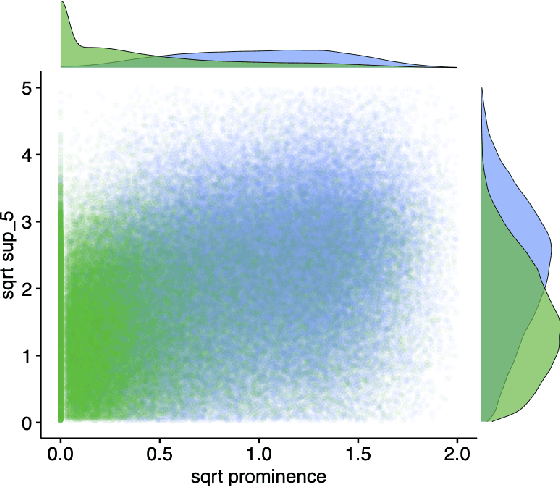
This paper investigates the use of word surprisal, a measure of the predictability of a word in a given context, as a feature to aid speech synthesis prosody. We explore how word surprisal extracted from large language models (LLMs) correlates with word prominence, a signal-based measure of the salience of a word in a given discourse. We also examine how context length and LLM size affect the results, and how a speech synthesizer conditioned with surprisal values compares with a baseline system. To evaluate these factors, we conducted experiments using a large corpus of English text and LLMs of varying sizes. Our results show that word surprisal and word prominence are moderately correlated, suggesting that they capture related but distinct aspects of language use. We find that length of context and size of the LLM impact the correlations, but not in the direction anticipated, with longer contexts and larger LLMs generally underpredicting prominent words in a nearly linear manner. We demonstrate that, in line with these findings, a speech synthesizer conditioned with surprisal values provides a minimal improvement over the baseline with the results suggesting a limited effect of using surprisal values for eliciting appropriate prominence patterns.
Better speech synthesis through scaling
May 12, 2023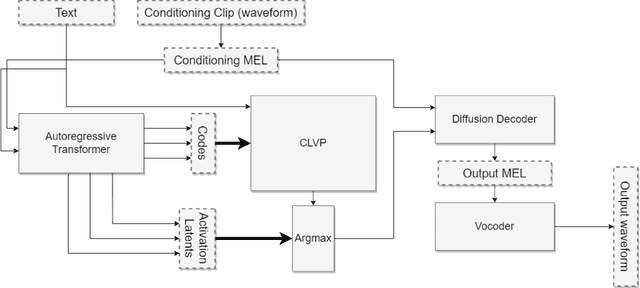

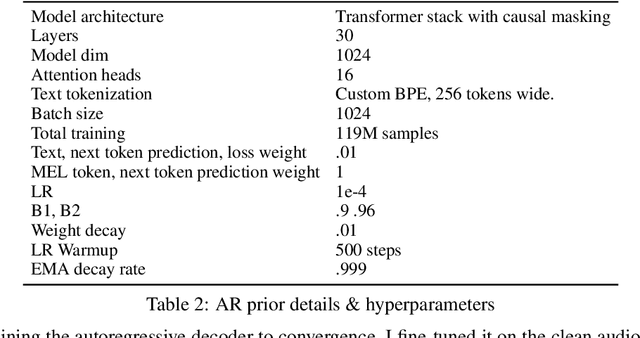
In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise -- an expressive, multi-voice text-to-speech system. All model code and trained weights have been open-sourced at https://github.com/neonbjb/tortoise-tts.
MParrotTTS: Multilingual Multi-speaker Text to Speech Synthesis in Low Resource Setting
May 19, 2023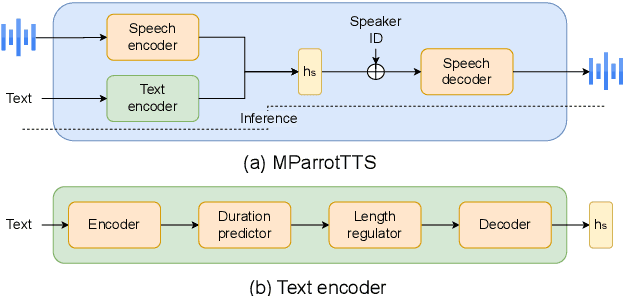
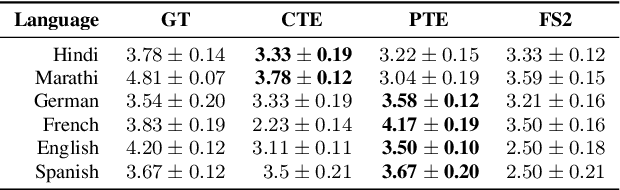
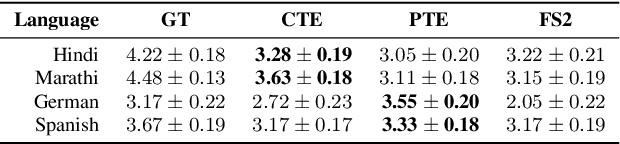

We present MParrotTTS, a unified multilingual, multi-speaker text-to-speech (TTS) synthesis model that can produce high-quality speech. Benefiting from a modularized training paradigm exploiting self-supervised speech representations, MParrotTTS adapts to a new language with minimal supervised data and generalizes to languages not seen while training the self-supervised backbone. Moreover, without training on any bilingual or parallel examples, MParrotTTS can transfer voices across languages while preserving the speaker-specific characteristics, e.g., synthesizing fluent Hindi speech using a French speaker's voice and accent. We present extensive results on six languages in terms of speech naturalness and speaker similarity in parallel and cross-lingual synthesis. The proposed model outperforms the state-of-the-art multilingual TTS models and baselines, using only a small fraction of supervised training data. Speech samples from our model can be found at https://paper2438.github.io/tts/
HTEC: Human Transcription Error Correction
Sep 18, 2023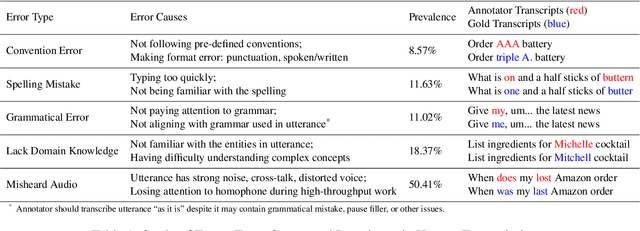
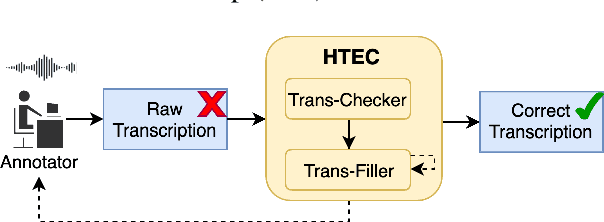

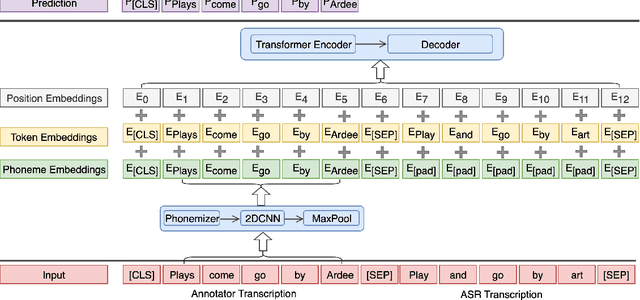
High-quality human transcription is essential for training and improving Automatic Speech Recognition (ASR) models. Recent study~\cite{libricrowd} has found that every 1% worse transcription Word Error Rate (WER) increases approximately 2% ASR WER by using the transcriptions to train ASR models. Transcription errors are inevitable for even highly-trained annotators. However, few studies have explored human transcription correction. Error correction methods for other problems, such as ASR error correction and grammatical error correction, do not perform sufficiently for this problem. Therefore, we propose HTEC for Human Transcription Error Correction. HTEC consists of two stages: Trans-Checker, an error detection model that predicts and masks erroneous words, and Trans-Filler, a sequence-to-sequence generative model that fills masked positions. We propose a holistic list of correction operations, including four novel operations handling deletion errors. We further propose a variant of embeddings that incorporates phoneme information into the input of the transformer. HTEC outperforms other methods by a large margin and surpasses human annotators by 2.2% to 4.5% in WER. Finally, we deployed HTEC to assist human annotators and showed HTEC is particularly effective as a co-pilot, which improves transcription quality by 15.1% without sacrificing transcription velocity.
OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment
Jun 10, 2023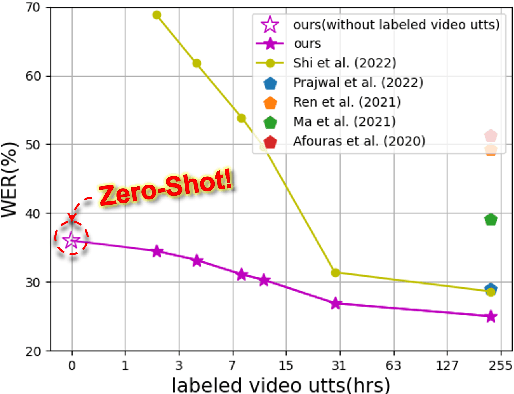
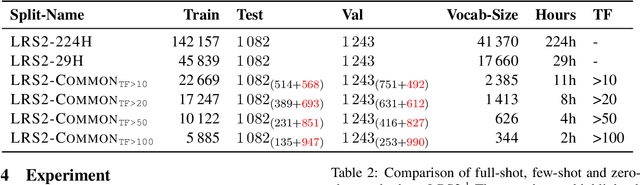
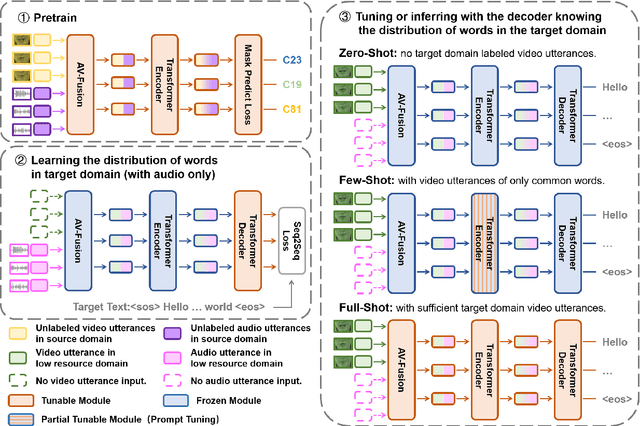
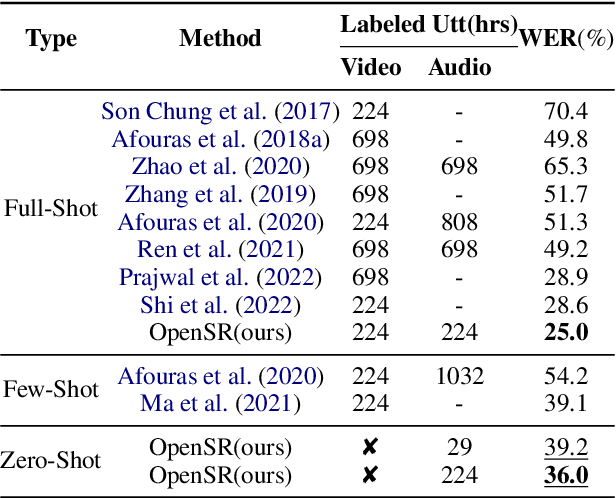
Speech Recognition builds a bridge between the multimedia streaming (audio-only, visual-only or audio-visual) and the corresponding text transcription. However, when training the specific model of new domain, it often gets stuck in the lack of new-domain utterances, especially the labeled visual utterances. To break through this restriction, we attempt to achieve zero-shot modality transfer by maintaining the multi-modality alignment in phoneme space learned with unlabeled multimedia utterances in the high resource domain during the pre-training \cite{shi2022learning}, and propose a training system Open-modality Speech Recognition (\textbf{OpenSR}) that enables the models trained on a single modality (e.g., audio-only) applicable to more modalities (e.g., visual-only and audio-visual). Furthermore, we employ a cluster-based prompt tuning strategy to handle the domain shift for the scenarios with only common words in the new domain utterances. We demonstrate that OpenSR enables modality transfer from one to any in three different settings (zero-, few- and full-shot), and achieves highly competitive zero-shot performance compared to the existing few-shot and full-shot lip-reading methods. To the best of our knowledge, OpenSR achieves the state-of-the-art performance of word error rate in LRS2 on audio-visual speech recognition and lip-reading with 2.7\% and 25.0\%, respectively. The code and demo are available at https://github.com/Exgc/OpenSR.
A Review of Deep Learning Techniques for Speech Processing
May 02, 2023
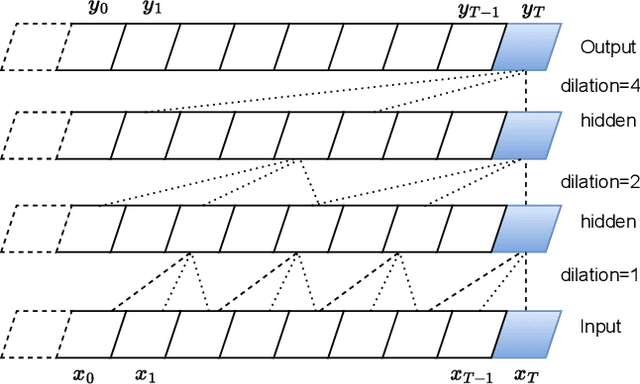
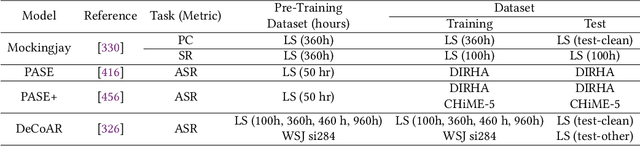
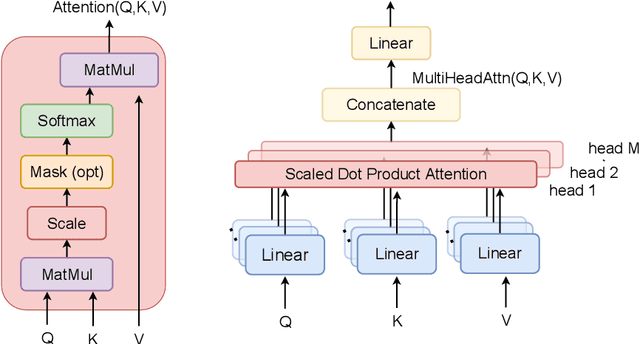
The field of speech processing has undergone a transformative shift with the advent of deep learning. The use of multiple processing layers has enabled the creation of models capable of extracting intricate features from speech data. This development has paved the way for unparalleled advancements in speech recognition, text-to-speech synthesis, automatic speech recognition, and emotion recognition, propelling the performance of these tasks to unprecedented heights. The power of deep learning techniques has opened up new avenues for research and innovation in the field of speech processing, with far-reaching implications for a range of industries and applications. This review paper provides a comprehensive overview of the key deep learning models and their applications in speech-processing tasks. We begin by tracing the evolution of speech processing research, from early approaches, such as MFCC and HMM, to more recent advances in deep learning architectures, such as CNNs, RNNs, transformers, conformers, and diffusion models. We categorize the approaches and compare their strengths and weaknesses for solving speech-processing tasks. Furthermore, we extensively cover various speech-processing tasks, datasets, and benchmarks used in the literature and describe how different deep-learning networks have been utilized to tackle these tasks. Additionally, we discuss the challenges and future directions of deep learning in speech processing, including the need for more parameter-efficient, interpretable models and the potential of deep learning for multimodal speech processing. By examining the field's evolution, comparing and contrasting different approaches, and highlighting future directions and challenges, we hope to inspire further research in this exciting and rapidly advancing field.
Pushing the Limits of Unsupervised Unit Discovery for SSL Speech Representation
Jun 15, 2023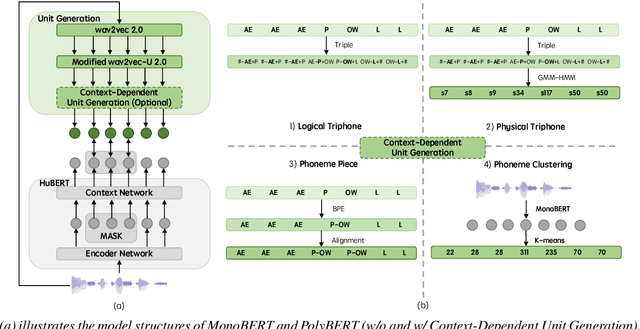
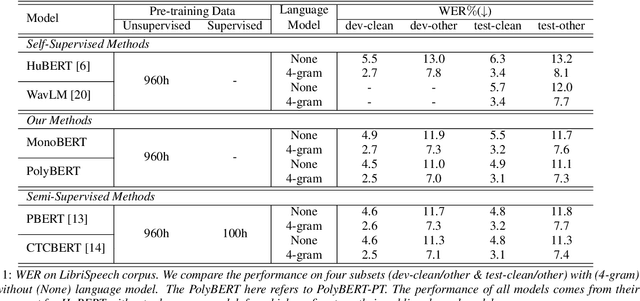
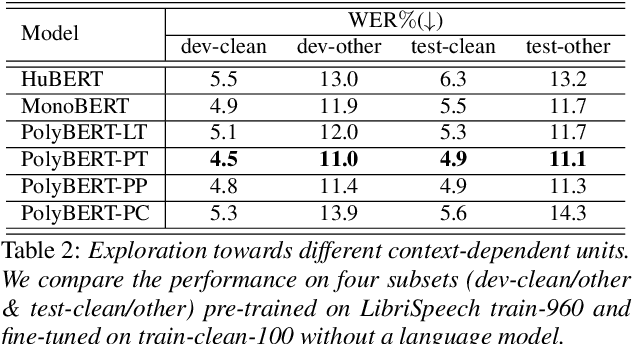
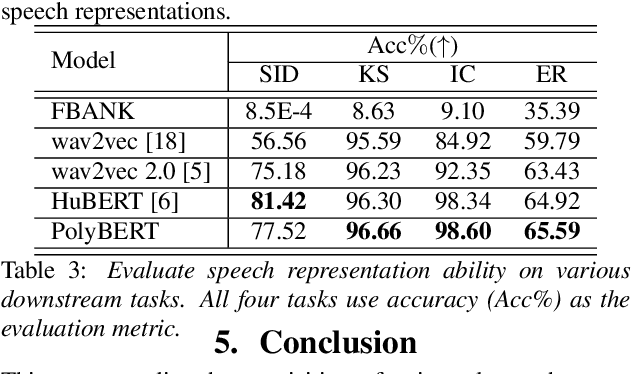
The excellent generalization ability of self-supervised learning (SSL) for speech foundation models has garnered significant attention. HuBERT is a successful example that utilizes offline clustering to convert speech features into discrete units for a masked language modeling pretext task. However, simply clustering features as targets by k-means does not fully inspire the model's performance. In this work, we present an unsupervised method to improve SSL targets. Two models are proposed, MonoBERT and PolyBERT, which leverage context-independent and context-dependent phoneme-based units for pre-training. Our models outperform other SSL models significantly on the LibriSpeech benchmark without the need for iterative re-clustering and re-training. Furthermore, our models equipped with context-dependent units even outperform target-improvement models that use labeled data during pre-training. How we progressively improve the unit discovery process is demonstrated through experiments.
Recovering implicit pitch contours from formants in whispered speech
Jul 06, 2023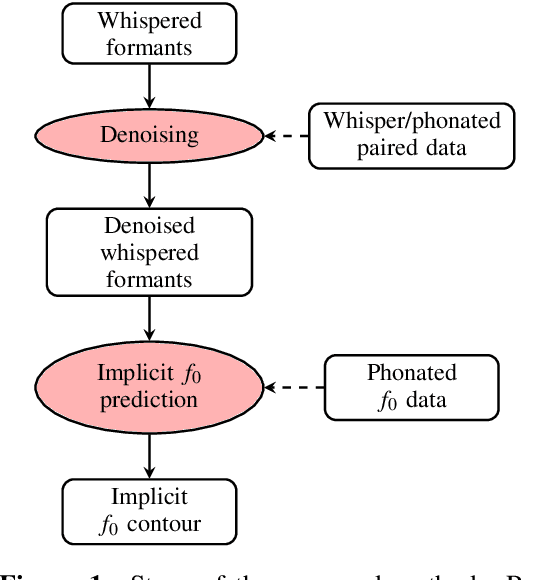
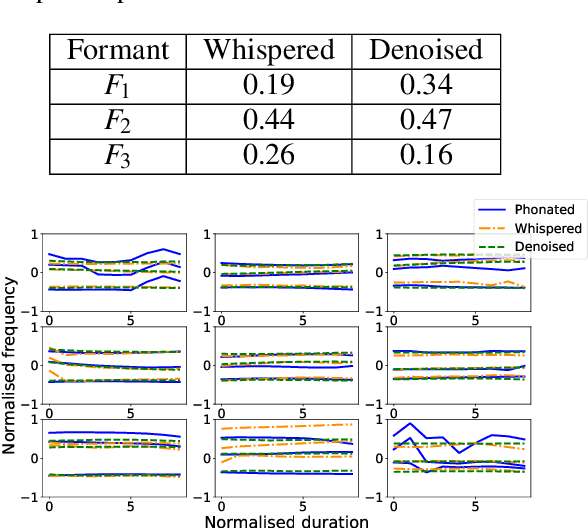
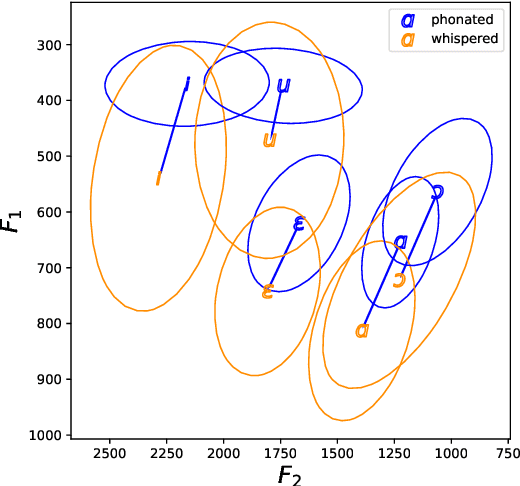
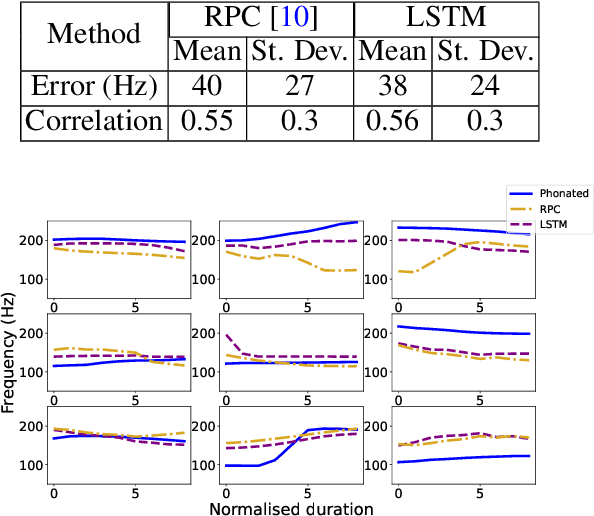
Whispered speech is characterised by a noise-like excitation that results in the lack of fundamental frequency. Considering that prosodic phenomena such as intonation are perceived through f0 variation, the perception of whispered prosody is relatively difficult. At the same time, studies have shown that speakers do attempt to produce intonation when whispering and that prosodic variability is being transmitted, suggesting that intonation "survives" in whispered formant structure. In this paper, we aim to estimate the way in which formant contours correlate with an "implicit" pitch contour in whisper, using a machine learning model. We propose a two-step method: using a parallel corpus, we first transform the whispered formants into their phonated equivalents using a denoising autoencoder. We then analyse the formant contours to predict phonated pitch contour variation. We observe that our method is effective in establishing a relationship between whispered and phonated formants and in uncovering implicit pitch contours in whisper.