 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions
Sep 15, 2023
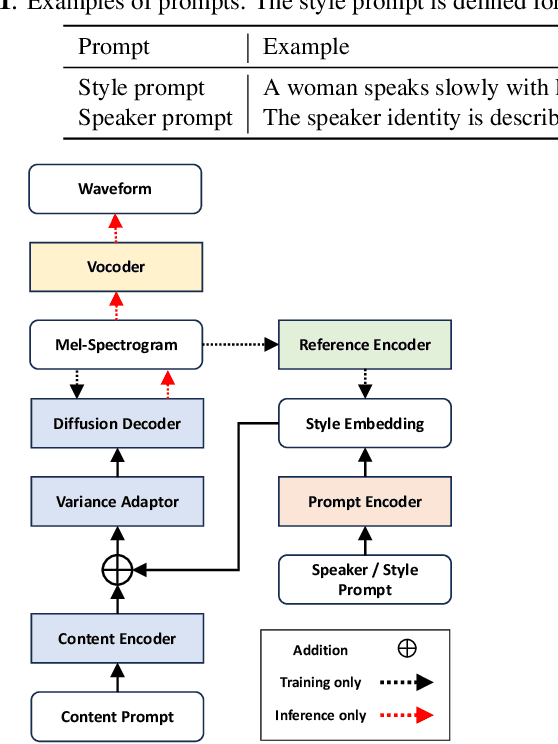
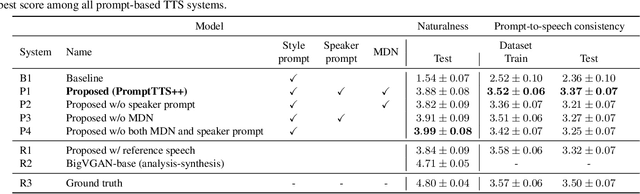
We propose PromptTTS++, a prompt-based text-to-speech (TTS) synthesis system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce the concept of speaker prompt, which describes voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent of speaking style. Since there is no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality, such as pitch, speaking speed, and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Our subjective evaluation results show that the proposed method can better control speaker characteristics than the methods without the speaker prompt. Audio samples are available at https://reppy4620.github.io/demo.promptttspp/.
Towards an Interpretable Representation of Speaker Identity via Perceptual Voice Qualities
Oct 04, 2023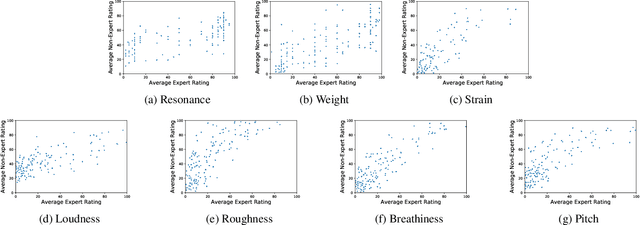

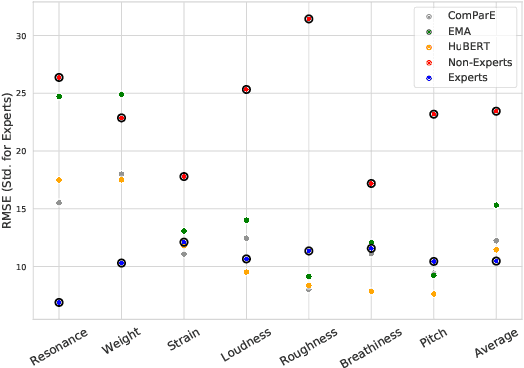
Unlike other data modalities such as text and vision, speech does not lend itself to easy interpretation. While lay people can understand how to describe an image or sentence via perception, non-expert descriptions of speech often end at high-level demographic information, such as gender or age. In this paper, we propose a possible interpretable representation of speaker identity based on perceptual voice qualities (PQs). By adding gendered PQs to the pathology-focused Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) protocol, our PQ-based approach provides a perceptual latent space of the character of adult voices that is an intermediary of abstraction between high-level demographics and low-level acoustic, physical, or learned representations. Contrary to prior belief, we demonstrate that these PQs are hearable by ensembles of non-experts, and further demonstrate that the information encoded in a PQ-based representation is predictable by various speech representations.
Written and spoken corpus of real and fake social media postings about COVID-19
Oct 06, 2023
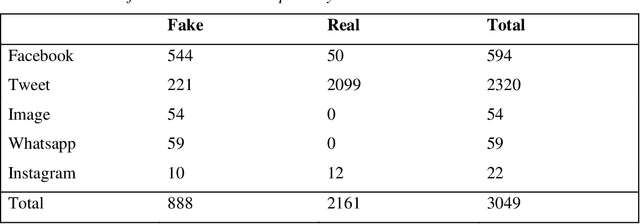

This study investigates the linguistic traits of fake news and real news. There are two parts to this study: text data and speech data. The text data for this study consisted of 6420 COVID-19 related tweets re-filtered from Patwa et al. (2021). After cleaning, the dataset contained 3049 tweets, with 2161 labeled as 'real' and 888 as 'fake'. The speech data for this study was collected from TikTok, focusing on COVID-19 related videos. Research assistants fact-checked each video's content using credible sources and labeled them as 'Real', 'Fake', or 'Questionable', resulting in a dataset of 91 real entries and 109 fake entries from 200 TikTok videos with a total word count of 53,710 words. The data was analysed using the Linguistic Inquiry and Word Count (LIWC) software to detect patterns in linguistic data. The results indicate a set of linguistic features that distinguish fake news from real news in both written and speech data. This offers valuable insights into the role of language in shaping trust, social media interactions, and the propagation of fake news.
Federated Representation Learning for Automatic Speech Recognition
Aug 07, 2023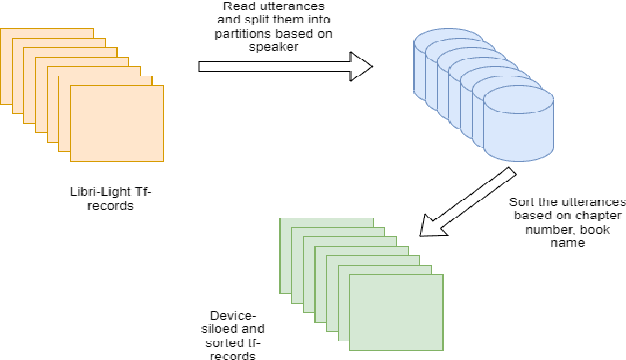
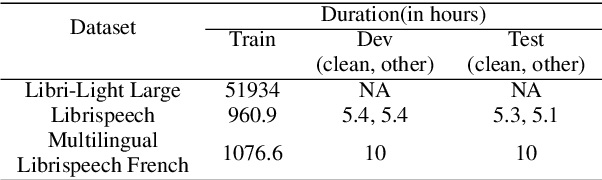
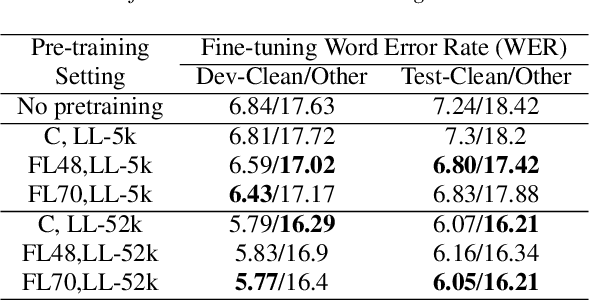
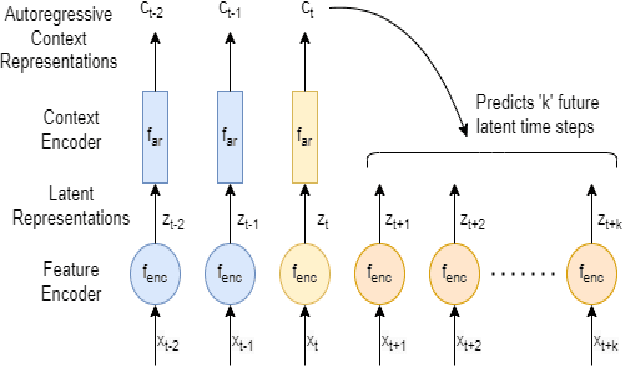
Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
A Fused Deep Denoising Sound Coding Strategy for Bilateral Cochlear Implants
Oct 02, 2023Cochlear implants (CIs) provide a solution for individuals with severe sensorineural hearing loss to regain their hearing abilities. When someone experiences this form of hearing impairment in both ears, they may be equipped with two separate CI devices, which will typically further improve the CI benefits. This spatial hearing is particularly crucial when tackling the challenge of understanding speech in noisy environments, a common issue CI users face. Currently, extensive research is dedicated to developing algorithms that can autonomously filter out undesired background noises from desired speech signals. At present, some research focuses on achieving end-to-end denoising, either as an integral component of the initial CI signal processing or by fully integrating the denoising process into the CI sound coding strategy. This work is presented in the context of bilateral CI (BiCI) systems, where we propose a deep-learning-based bilateral speech enhancement model that shares information between both hearing sides. Specifically, we connect two monaural end-to-end deep denoising sound coding techniques through intermediary latent fusion layers. These layers amalgamate the latent representations generated by these techniques by multiplying them together, resulting in an enhanced ability to reduce noise and improve learning generalization. The objective instrumental results demonstrate that the proposed fused BiCI sound coding strategy achieves higher interaural coherence, superior noise reduction, and enhanced predicted speech intelligibility scores compared to the baseline methods. Furthermore, our speech-in-noise intelligibility results in BiCI users reveal that the deep denoising sound coding strategy can attain scores similar to those achieved in quiet conditions.
Many-to-Many Spoken Language Translation via Unified Speech and Text Representation Learning with Unit-to-Unit Translation
Aug 03, 2023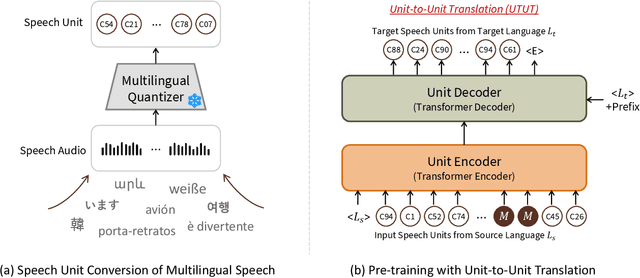
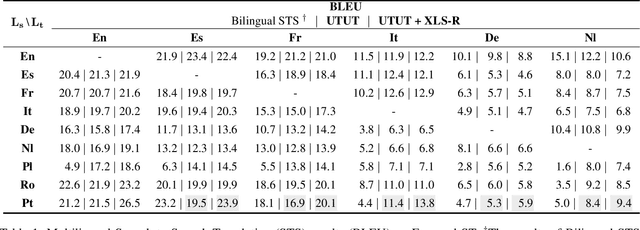
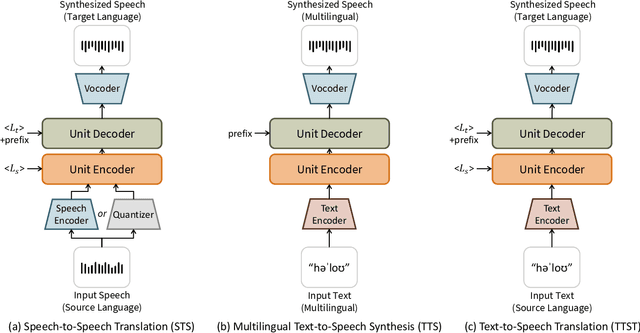

In this paper, we propose a method to learn unified representations of multilingual speech and text with a single model, especially focusing on the purpose of speech synthesis. We represent multilingual speech audio with speech units, the quantized representations of speech features encoded from a self-supervised speech model. Therefore, we can focus on their linguistic content by treating the audio as pseudo text and can build a unified representation of speech and text. Then, we propose to train an encoder-decoder structured model with a Unit-to-Unit Translation (UTUT) objective on multilingual data. Specifically, by conditioning the encoder with the source language token and the decoder with the target language token, the model is optimized to translate the spoken language into that of the target language, in a many-to-many language translation setting. Therefore, the model can build the knowledge of how spoken languages are comprehended and how to relate them to different languages. A single pre-trained model with UTUT can be employed for diverse multilingual speech- and text-related tasks, such as Speech-to-Speech Translation (STS), multilingual Text-to-Speech Synthesis (TTS), and Text-to-Speech Translation (TTST). By conducting comprehensive experiments encompassing various languages, we validate the efficacy of the proposed method across diverse multilingual tasks. Moreover, we show UTUT can perform many-to-many language STS, which has not been previously explored in the literature. Samples are available on https://choijeongsoo.github.io/utut.
PuoBERTa: Training and evaluation of a curated language model for Setswana
Oct 24, 2023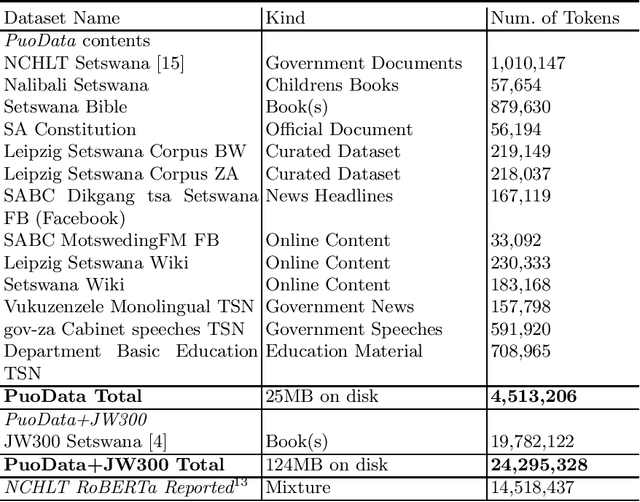
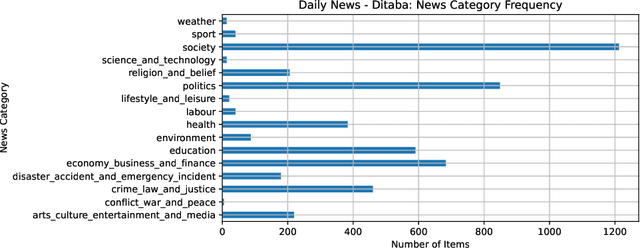

Natural language processing (NLP) has made significant progress for well-resourced languages such as English but lagged behind for low-resource languages like Setswana. This paper addresses this gap by presenting PuoBERTa, a customised masked language model trained specifically for Setswana. We cover how we collected, curated, and prepared diverse monolingual texts to generate a high-quality corpus for PuoBERTa's training. Building upon previous efforts in creating monolingual resources for Setswana, we evaluated PuoBERTa across several NLP tasks, including part-of-speech (POS) tagging, named entity recognition (NER), and news categorisation. Additionally, we introduced a new Setswana news categorisation dataset and provided the initial benchmarks using PuoBERTa. Our work demonstrates the efficacy of PuoBERTa in fostering NLP capabilities for understudied languages like Setswana and paves the way for future research directions.
Detecting Deepfakes Without Seeing Any
Nov 02, 2023Deepfake attacks, malicious manipulation of media containing people, are a serious concern for society. Conventional deepfake detection methods train supervised classifiers to distinguish real media from previously encountered deepfakes. Such techniques can only detect deepfakes similar to those previously seen, but not zero-day (previously unseen) attack types. As current deepfake generation techniques are changing at a breathtaking pace, new attack types are proposed frequently, making this a major issue. Our main observations are that: i) in many effective deepfake attacks, the fake media must be accompanied by false facts i.e. claims about the identity, speech, motion, or appearance of the person. For instance, when impersonating Obama, the attacker explicitly or implicitly claims that the fake media show Obama; ii) current generative techniques cannot perfectly synthesize the false facts claimed by the attacker. We therefore introduce the concept of "fact checking", adapted from fake news detection, for detecting zero-day deepfake attacks. Fact checking verifies that the claimed facts (e.g. identity is Obama), agree with the observed media (e.g. is the face really Obama's?), and thus can differentiate between real and fake media. Consequently, we introduce FACTOR, a practical recipe for deepfake fact checking and demonstrate its power in critical attack settings: face swapping and audio-visual synthesis. Although it is training-free, relies exclusively on off-the-shelf features, is very easy to implement, and does not see any deepfakes, it achieves better than state-of-the-art accuracy.
M3-AUDIODEC: Multi-channel multi-speaker multi-spatial audio codec
Sep 23, 2023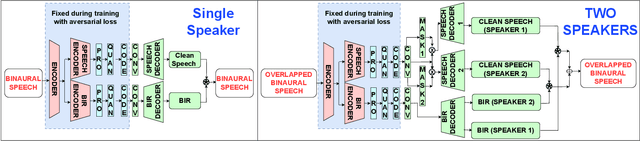

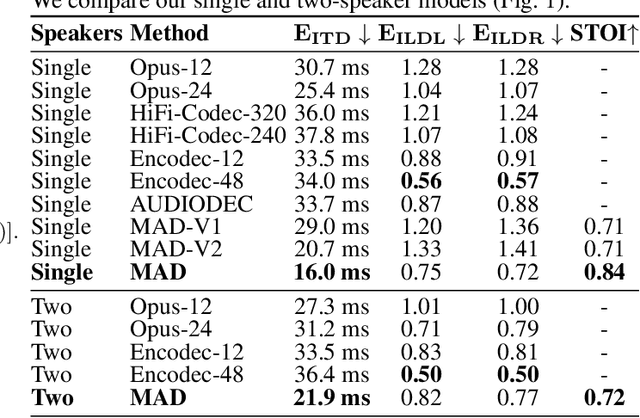
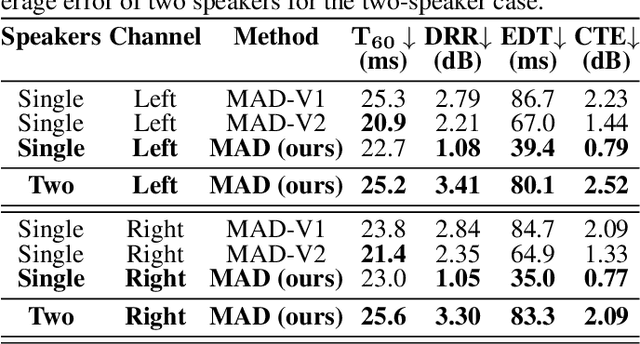
We introduce M3-AUDIODEC, an innovative neural spatial audio codec designed for efficient compression of multi-channel (binaural) speech in both single and multi-speaker scenarios, while retaining the spatial location information of each speaker. This model boasts versatility, allowing configuration and training tailored to a predetermined set of multi-channel, multi-speaker, and multi-spatial overlapping speech conditions. Key contributions are as follows: 1) Previous neural codecs are extended from single to multi-channel audios. 2) The ability of our proposed model to compress and decode for overlapping speech. 3) A groundbreaking architecture that compresses speech content and spatial cues separately, ensuring the preservation of each speaker's spatial context after decoding. 4) M3-AUDIODEC's proficiency in reducing the bandwidth for compressing two-channel speech by 48% when compared to individual binaural channel compression. Impressively, at a 12.6 kbps operation, it outperforms Opus at 24 kbps and AUDIODEC at 24 kbps by 37% and 52%, respectively. In our assessment, we employed speech enhancement and room acoustic metrics to ascertain the accuracy of clean speech and spatial cue estimates from M3-AUDIODEC. Audio demonstrations and source code are available online at https://github.com/anton-jeran/MULTI-AUDIODEC .
End-to-End Evaluation for Low-Latency Simultaneous Speech Translation
Aug 07, 2023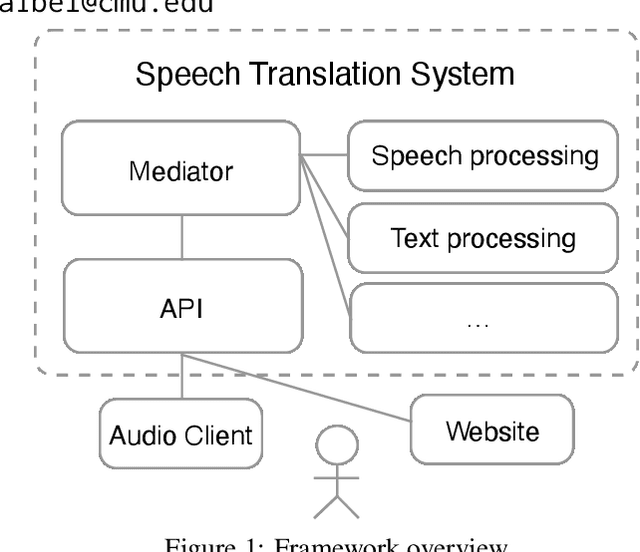
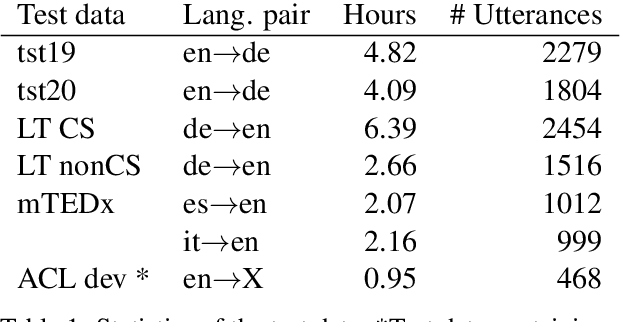
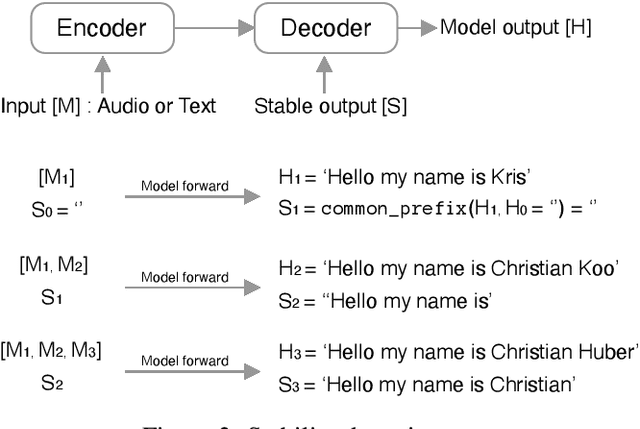
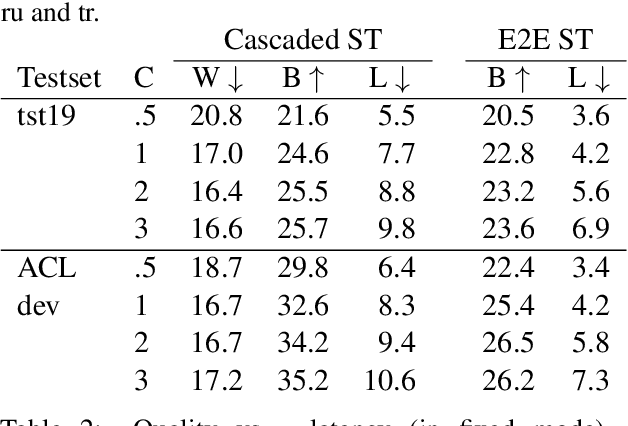
The challenge of low-latency speech translation has recently draw significant interest in the research community as shown by several publications and shared tasks. Therefore, it is essential to evaluate these different approaches in realistic scenarios. However, currently only specific aspects of the systems are evaluated and often it is not possible to compare different approaches. In this work, we propose the first framework to perform and evaluate the various aspects of low-latency speech translation under realistic conditions. The evaluation is carried out in an end-to-end fashion. This includes the segmentation of the audio as well as the run-time of the different components. Secondly, we compare different approaches to low-latency speech translation using this framework. We evaluate models with the option to revise the output as well as methods with fixed output. Furthermore, we directly compare state-of-the-art cascaded as well as end-to-end systems. Finally, the framework allows to automatically evaluate the translation quality as well as latency and also provides a web interface to show the low-latency model outputs to the user.