 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Human-Model Discrepancies in Speech Quality Assessment via Acoustic and Prosodic Perturbations
Jun 18, 2026Mean opinion score (MOS) prediction models are widely used as proxy metrics in text-to-speech (TTS) research, yet their ability to capture quality differences beyond acoustic fidelity remains unclear. We investigate this via controlled perturbations on speech: acoustic degradation, prosodic errors, and manipulation of speaker-specific characteristics such as pitch and speaking rate. We obtained MOS predictions for these speech samples from both human listeners and the model, and analyzed the differences in their perceptual characteristics. Results show that most models track acoustic degradation well, while all are insensitive to prosodic errors despite large subjective score drops. For speaker characteristics, models exhibit a double dissociation: strong mean fundamental frequency (F0) biases absent in human ratings, yet insensitivity to speaking rate and F0 variability that humans notice. These findings highlight limitations of scalar MOS prediction beyond acoustic fidelity.
PASQA: Pitch-Accent-Focused Speech Quality Assessment Model Trained on Synthetic Speech with Accent Errors
Jun 18, 2026Existing mean opinion score (MOS) prediction models typically predict utterance-level naturalness MOS and can be insensitive to localized pitch-accent errors. We propose Pitch-Accent-focused Speech Quality Assessment (PASQA), which explicitly targets pitch-accent correctness. To train our model, we construct a controlled Japanese accent-error dataset by changing accent patterns using an accent-controllable text-to-speech system, and compute a pseudo accent-quality score from the accent-error rate. PASQA builds on self-supervised representations and employs mora-conditioned fusion, ranking loss, an auxiliary accent-error localization task, and speaker-invariant training. Experiments show that conventional models fail to preserve the ordering by accent-error severity, whereas PASQA achieves high ordering accuracy on both seen and unseen speakers. Further, PASQA shows stronger agreement with human accent-correctness judgments. The code is available at https://github.com/lycorp-jp/PASQA.
Schödinger Bridge Type Diffusion Models as an Extension of Variational Autoencoders
Dec 24, 2024
Generative diffusion models use time-forward and backward stochastic differential equations to connect the data and prior distributions. While conventional diffusion models (e.g., score-based models) only learn the backward process, more flexible frameworks have been proposed to also learn the forward process by employing the Schr\"odinger bridge (SB). However, due to the complexity of the mathematical structure behind SB-type models, we can not easily give an intuitive understanding of their objective function. In this work, we propose a unified framework to construct diffusion models by reinterpreting the SB-type models as an extension of variational autoencoders. In this context, the data processing inequality plays a crucial role. As a result, we find that the objective function consists of the prior loss and drift matching parts.
PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions
Sep 15, 2023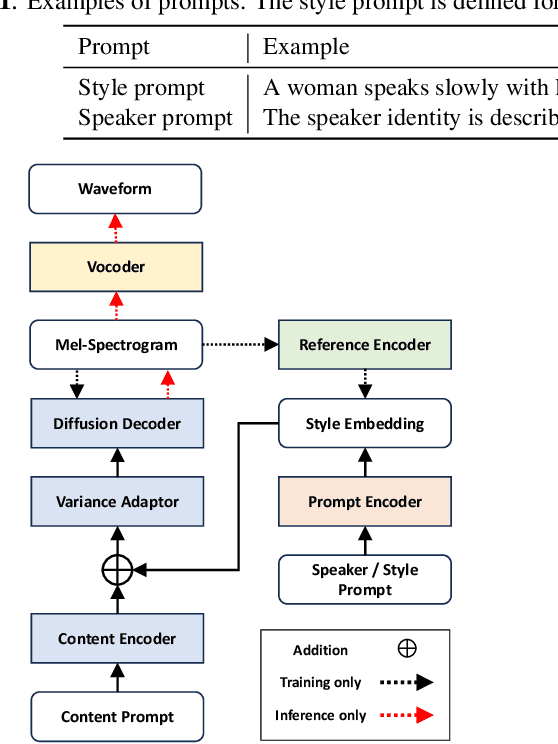
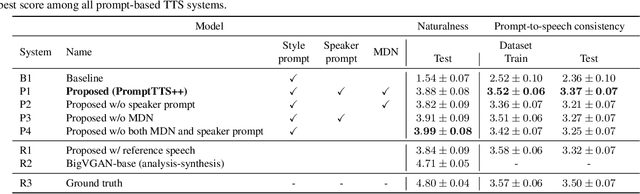
We propose PromptTTS++, a prompt-based text-to-speech (TTS) synthesis system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce the concept of speaker prompt, which describes voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent of speaking style. Since there is no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality, such as pitch, speaking speed, and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Our subjective evaluation results show that the proposed method can better control speaker characteristics than the methods without the speaker prompt. Audio samples are available at https://reppy4620.github.io/demo.promptttspp/.