 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Sep 22, 2023
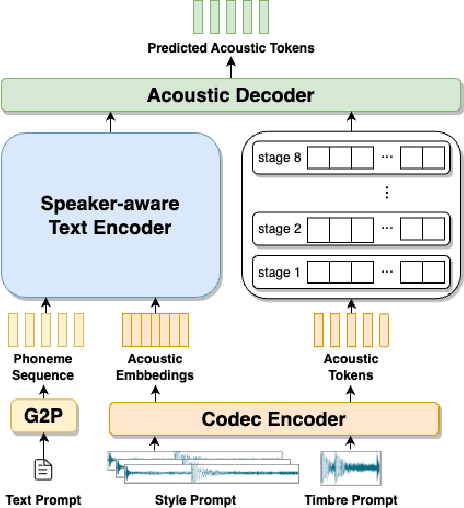
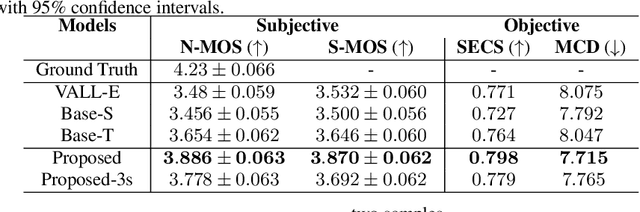
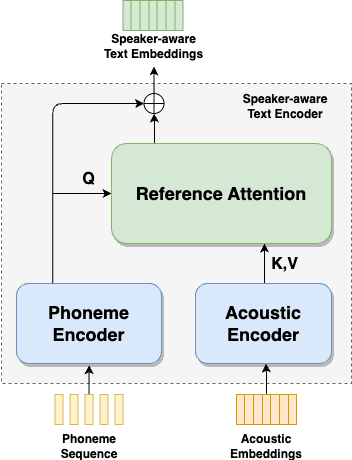
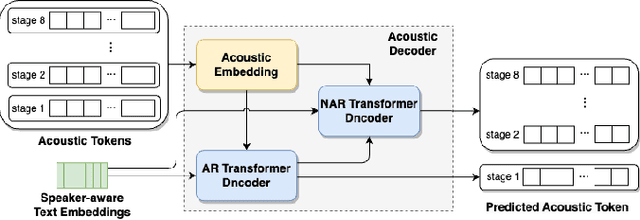
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Deep Neural Networks for Automatic Speaker Recognition Do Not Learn Supra-Segmental Temporal Features
Nov 02, 2023While deep neural networks have shown impressive results in automatic speaker recognition and related tasks, it is dissatisfactory how little is understood about what exactly is responsible for these results. Part of the success has been attributed in prior work to their capability to model supra-segmental temporal information (SST), i.e., learn rhythmic-prosodic characteristics of speech in addition to spectral features. In this paper, we (i) present and apply a novel test to quantify to what extent the performance of state-of-the-art neural networks for speaker recognition can be explained by modeling SST; and (ii) present several means to force respective nets to focus more on SST and evaluate their merits. We find that a variety of CNN- and RNN-based neural network architectures for speaker recognition do not model SST to any sufficient degree, even when forced. The results provide a highly relevant basis for impactful future research into better exploitation of the full speech signal and give insights into the inner workings of such networks, enhancing explainability of deep learning for speech technologies.
VoiceBank-2023: A Multi-Speaker Mandarin Speech Corpus for Constructing Personalized TTS Systems for the Speech Impaired
Aug 27, 2023Services of personalized TTS systems for the Mandarin-speaking speech impaired are rarely mentioned. Taiwan started the VoiceBanking project in 2020, aiming to build a complete set of services to deliver personalized Mandarin TTS systems to amyotrophic lateral sclerosis patients. This paper reports the corpus design, corpus recording, data purging and correction for the corpus, and evaluations of the developed personalized TTS systems, for the VoiceBanking project. The developed corpus is named after the VoiceBank-2023 speech corpus because of its release year. The corpus contains 29.78 hours of utterances with prompts of short paragraphs and common phrases spoken by 111 native Mandarin speakers. The corpus is labeled with information about gender, degree of speech impairment, types of users, transcription, SNRs, and speaking rates. The VoiceBank-2023 is available by request for non-commercial use and welcomes all parties to join the VoiceBanking project to improve the services for the speech impaired.
Regularized Conventions: Equilibrium Computation as a Model of Pragmatic Reasoning
Nov 16, 2023We present a model of pragmatic language understanding, where utterances are produced and understood by searching for regularized equilibria of signaling games. In this model (which we call ReCo, for Regularized Conventions), speakers and listeners search for contextually appropriate utterance--meaning mappings that are both close to game-theoretically optimal conventions and close to a shared, ''default'' semantics. By characterizing pragmatic communication as equilibrium search, we obtain principled sampling algorithms and formal guarantees about the trade-off between communicative success and naturalness. Across several datasets capturing real and idealized human judgments about pragmatic implicatures, ReCo matches or improves upon predictions made by best response and rational speech act models of language understanding.
EMOCONV-DIFF: Diffusion-based Speech Emotion Conversion for Non-parallel and In-the-wild Data
Sep 14, 2023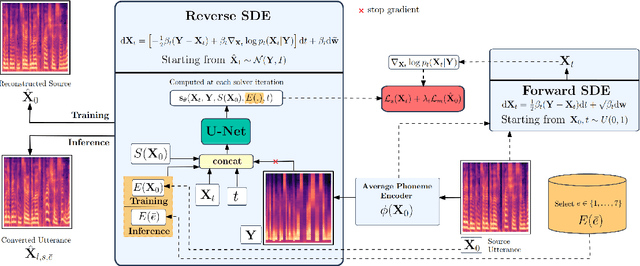
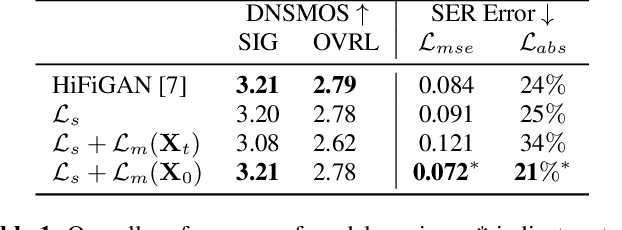
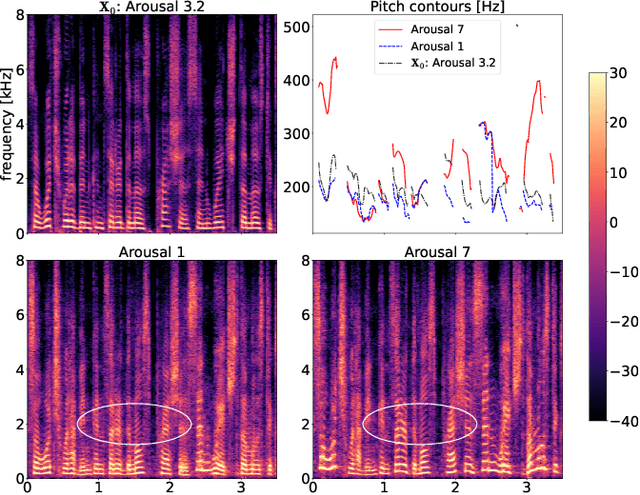
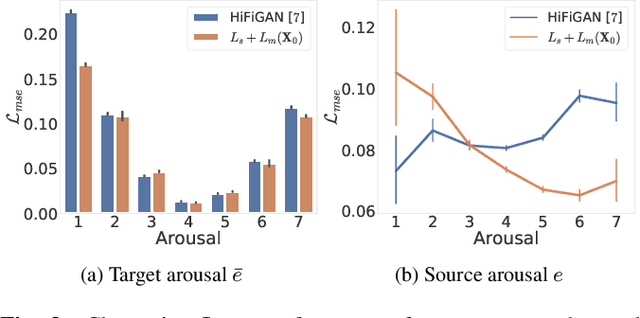
Speech emotion conversion is the task of converting the expressed emotion of a spoken utterance to a target emotion while preserving the lexical content and speaker identity. While most existing works in speech emotion conversion rely on acted-out datasets and parallel data samples, in this work we specifically focus on more challenging in-the-wild scenarios and do not rely on parallel data. To this end, we propose a diffusion-based generative model for speech emotion conversion, the EmoConv-Diff, that is trained to reconstruct an input utterance while also conditioning on its emotion. Subsequently, at inference, a target emotion embedding is employed to convert the emotion of the input utterance to the given target emotion. As opposed to performing emotion conversion on categorical representations, we use a continuous arousal dimension to represent emotions while also achieving intensity control. We validate the proposed methodology on a large in-the-wild dataset, the MSP-Podcast v1.10. Our results show that the proposed diffusion model is indeed capable of synthesizing speech with a controllable target emotion. Crucially, the proposed approach shows improved performance along the extreme values of arousal and thereby addresses a common challenge in the speech emotion conversion literature.
DurIAN-E: Duration Informed Attention Network For Expressive Text-to-Speech Synthesis
Sep 22, 2023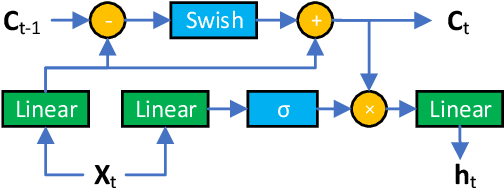

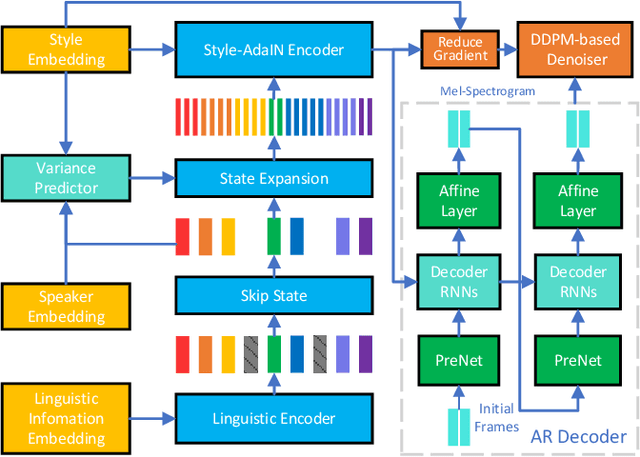
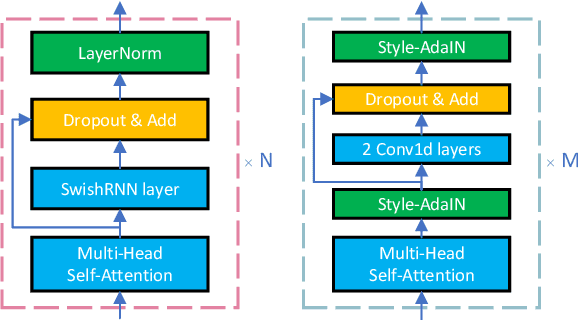
This paper introduces an improved duration informed attention neural network (DurIAN-E) for expressive and high-fidelity text-to-speech (TTS) synthesis. Inherited from the original DurIAN model, an auto-regressive model structure in which the alignments between the input linguistic information and the output acoustic features are inferred from a duration model is adopted. Meanwhile the proposed DurIAN-E utilizes multiple stacked SwishRNN-based Transformer blocks as linguistic encoders. Style-Adaptive Instance Normalization (SAIN) layers are exploited into frame-level encoders to improve the modeling ability of expressiveness. A denoiser incorporating both denoising diffusion probabilistic model (DDPM) for mel-spectrograms and SAIN modules is conducted to further improve the synthetic speech quality and expressiveness. Experimental results prove that the proposed expressive TTS model in this paper can achieve better performance than the state-of-the-art approaches in both subjective mean opinion score (MOS) and preference tests.
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack Detection
Nov 22, 2023Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset. The source code is available at https://github.com/redwankarimsony/WeightPerturbation-MSU.
Causal Signal-Based DCCRN with Overlapped-Frame Prediction for Online Speech Enhancement
Sep 07, 2023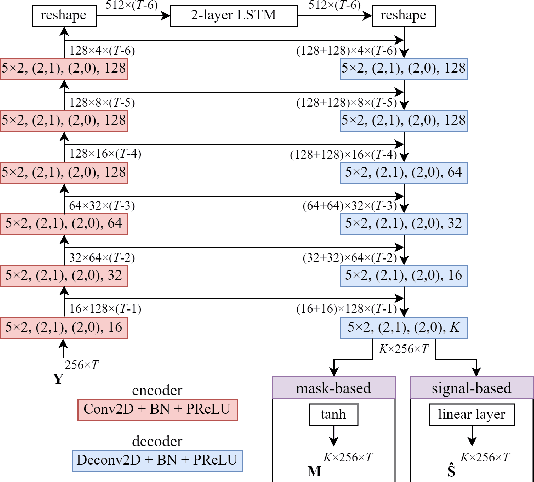
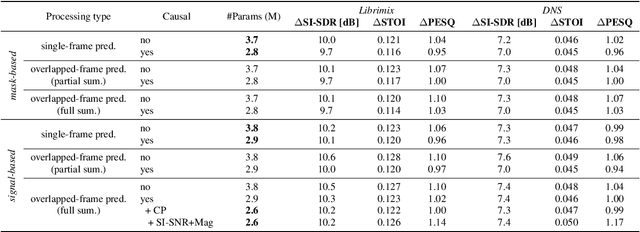
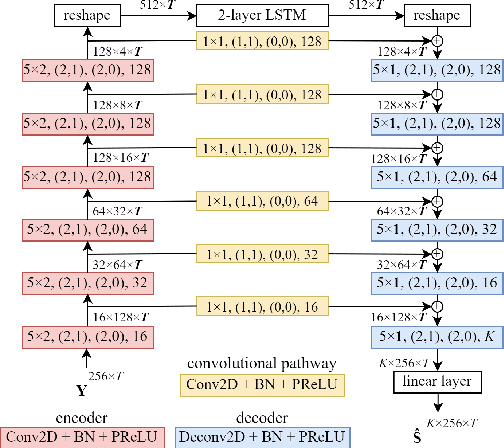
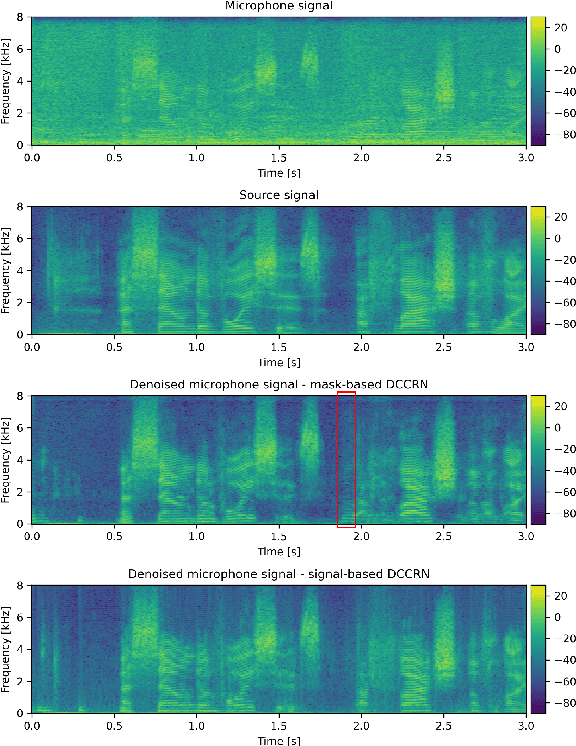
The aim of speech enhancement is to improve speech signal quality and intelligibility from a noisy microphone signal. In many applications, it is crucial to enable processing with small computational complexity and minimal requirements regarding access to future signal samples (look-ahead). This paper presents signal-based causal DCCRN that improves online single-channel speech enhancement by reducing the required look-ahead and the number of network parameters. The proposed modifications include complex filtering of the signal, application of overlapped-frame prediction, causal convolutions and deconvolutions, and modification of the loss function. Results of performed experiments indicate that the proposed model with overlapped signal prediction and additional adjustments, achieves similar or better performance than the original DCCRN in terms of various speech enhancement metrics, while it reduces the latency and network parameter number by around 30%.
QS-TTS: Towards Semi-Supervised Text-to-Speech Synthesis via Vector-Quantized Self-Supervised Speech Representation Learning
Aug 31, 2023
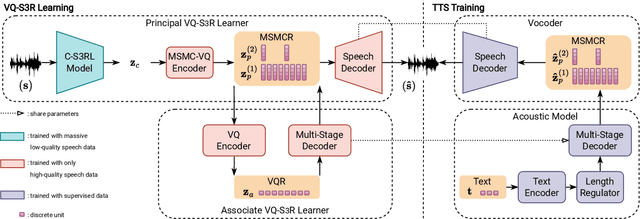
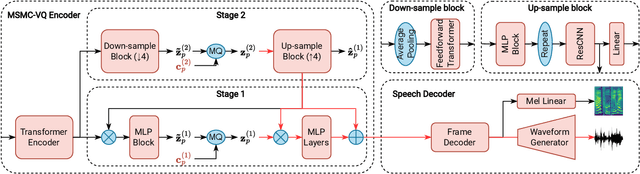
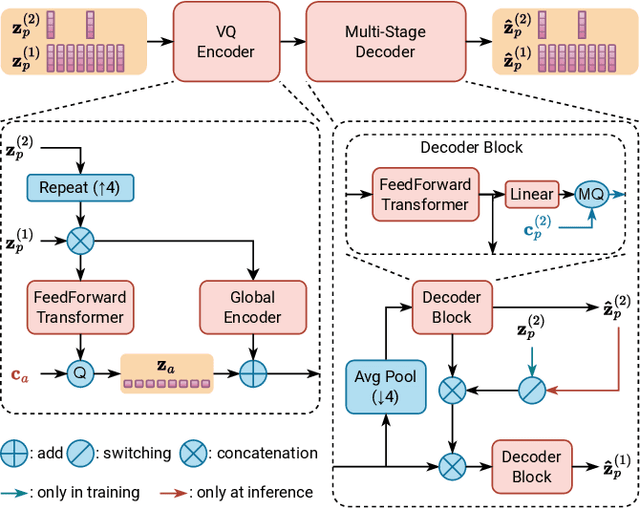
This paper proposes a novel semi-supervised TTS framework, QS-TTS, to improve TTS quality with lower supervised data requirements via Vector-Quantized Self-Supervised Speech Representation Learning (VQ-S3RL) utilizing more unlabeled speech audio. This framework comprises two VQ-S3R learners: first, the principal learner aims to provide a generative Multi-Stage Multi-Codebook (MSMC) VQ-S3R via the MSMC-VQ-GAN combined with the contrastive S3RL, while decoding it back to the high-quality audio; then, the associate learner further abstracts the MSMC representation into a highly-compact VQ representation through a VQ-VAE. These two generative VQ-S3R learners provide profitable speech representations and pre-trained models for TTS, significantly improving synthesis quality with the lower requirement for supervised data. QS-TTS is evaluated comprehensively under various scenarios via subjective and objective tests in experiments. The results powerfully demonstrate the superior performance of QS-TTS, winning the highest MOS over supervised or semi-supervised baseline TTS approaches, especially in low-resource scenarios. Moreover, comparing various speech representations and transfer learning methods in TTS further validates the notable improvement of the proposed VQ-S3RL to TTS, showing the best audio quality and intelligibility metrics. The trend of slower decay in the synthesis quality of QS-TTS with decreasing supervised data further highlights its lower requirements for supervised data, indicating its great potential in low-resource scenarios.
Speeding Up Speech Synthesis In Diffusion Models By Reducing Data Distribution Recovery Steps Via Content Transfer
Sep 18, 2023Diffusion based vocoders have been criticised for being slow due to the many steps required during sampling. Moreover, the model's loss function that is popularly implemented is designed such that the target is the original input $x_0$ or error $\epsilon_0$. For early time steps of the reverse process, this results in large prediction errors, which can lead to speech distortions and increase the learning time. We propose a setup where the targets are the different outputs of forward process time steps with a goal to reduce the magnitude of prediction errors and reduce the training time. We use the different layers of a neural network (NN) to perform denoising by training them to learn to generate representations similar to the noised outputs in the forward process of the diffusion. The NN layers learn to progressively denoise the input in the reverse process until finally the final layer estimates the clean speech. To avoid 1:1 mapping between layers of the neural network and the forward process steps, we define a skip parameter $\tau>1$ such that an NN layer is trained to cumulatively remove the noise injected in the $\tau$ steps in the forward process. This significantly reduces the number of data distribution recovery steps and, consequently, the time to generate speech. We show through extensive evaluation that the proposed technique generates high-fidelity speech in competitive time that outperforms current state-of-the-art tools. The proposed technique is also able to generalize well to unseen speech.