 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Whisper ASR Hallucinations Induced by Non-Speech Audio
Jan 20, 2025Hallucinations of deep neural models are amongst key challenges in automatic speech recognition (ASR). In this paper, we investigate hallucinations of the Whisper ASR model induced by non-speech audio segments present during inference. By inducting hallucinations with various types of sounds, we show that there exists a set of hallucinations that appear frequently. We then study hallucinations caused by the augmentation of speech with such sounds. Finally, we describe the creation of a bag of hallucinations (BoH) that allows to remove the effect of hallucinations through the post-processing of text transcriptions. The results of our experiments show that such post-processing is capable of reducing word error rate (WER) and acts as a good safeguard against problematic hallucinations.
HeightCeleb -- an enrichment of VoxCeleb dataset with speaker height information
Oct 16, 2024



Prediction of speaker's height is of interest for voice forensics, surveillance, and automatic speaker profiling. Until now, TIMIT has been the most popular dataset for training and evaluation of the height estimation methods. In this paper, we introduce HeightCeleb, an extension to VoxCeleb, which is the dataset commonly used in speaker recognition tasks. This enrichment consists in adding information about the height of all 1251 speakers from VoxCeleb that has been extracted with an automated method from publicly available sources. Such annotated data will enable the research community to utilize freely available speaker embedding extractors, pre-trained on VoxCeleb, to build more efficient speaker height estimators. In this work, we describe the creation of the HeightCeleb dataset and show that using it enables to achieve state-of-the-art results on the TIMIT test set by using simple statistical regression methods and embeddings obtained with a popular speaker model (without any additional fine-tuning).
Refining DNN-based Mask Estimation using CGMM-based EM Algorithm for Multi-channel Noise Reduction
Sep 18, 2023In this paper, we present a method that allows to further improve speech enhancement obtained with recently introduced Deep Neural Network (DNN) models. We propose a multi-channel refinement method of time-frequency masks obtained with single-channel DNNs, which consists of an iterative Complex Gaussian Mixture Model (CGMM) based algorithm, followed by optimum spatial filtration. We validate our approach on time-frequency masks estimated with three recent deep learning models, namely DCUnet, DCCRN, and FullSubNet. We show that our method with the proposed mask refinement procedure allows to improve the accuracy of estimated masks, in terms of the Area Under the ROC Curve (AUC) measure, and as a consequence the overall speech quality of the enhanced speech signal, as measured by PESQ improvement, and that the improvement is consistent across all three DNN models.
Causal Signal-Based DCCRN with Overlapped-Frame Prediction for Online Speech Enhancement
Sep 07, 2023



The aim of speech enhancement is to improve speech signal quality and intelligibility from a noisy microphone signal. In many applications, it is crucial to enable processing with small computational complexity and minimal requirements regarding access to future signal samples (look-ahead). This paper presents signal-based causal DCCRN that improves online single-channel speech enhancement by reducing the required look-ahead and the number of network parameters. The proposed modifications include complex filtering of the signal, application of overlapped-frame prediction, causal convolutions and deconvolutions, and modification of the loss function. Results of performed experiments indicate that the proposed model with overlapped signal prediction and additional adjustments, achieves similar or better performance than the original DCCRN in terms of various speech enhancement metrics, while it reduces the latency and network parameter number by around 30%.
Adversarial Domain Adaptation with Paired Examples for Acoustic Scene Classification on Different Recording Devices
Oct 18, 2021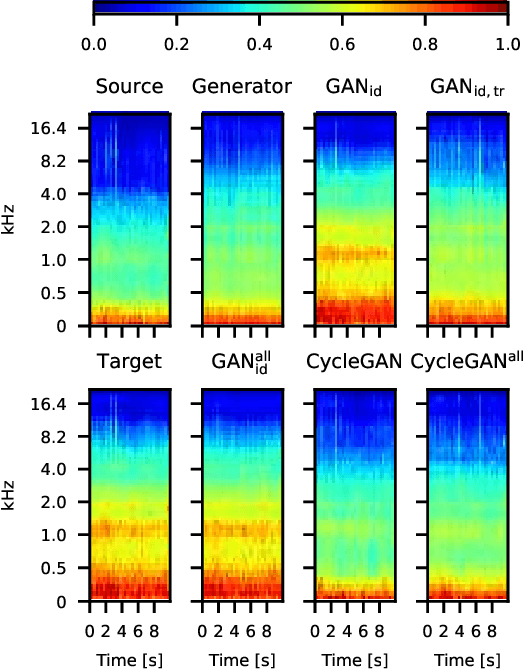
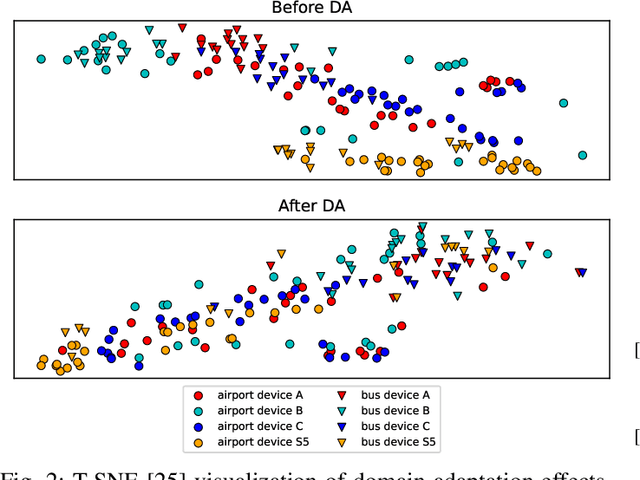
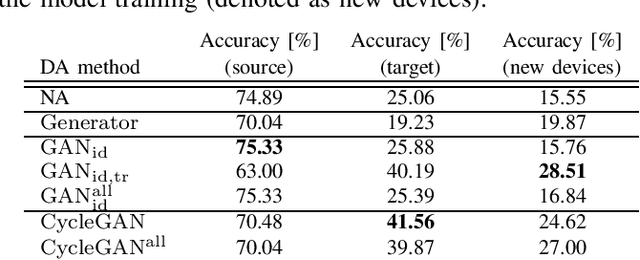
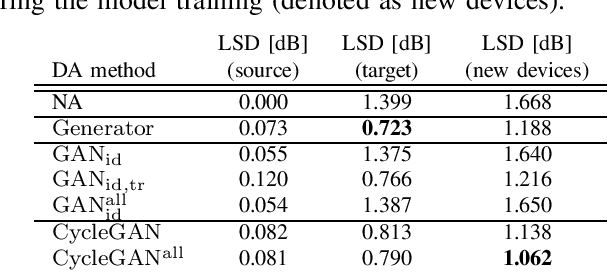
In classification tasks, the classification accuracy diminishes when the data is gathered in different domains. To address this problem, in this paper, we investigate several adversarial models for domain adaptation (DA) and their effect on the acoustic scene classification task. The studied models include several types of generative adversarial networks (GAN), with different loss functions, and the so-called cycle GAN which consists of two interconnected GAN models. The experiments are performed on the DCASE20 challenge task 1A dataset, in which we can leverage the paired examples of data recorded using different devices, i.e., the source and target domain recordings. The results of performed experiments indicate that the best performing domain adaptation can be obtained using the cycle GAN, which achieves as much as 66% relative improvement in accuracy for the target domain device, while only 6\% relative decrease in accuracy on the source domain. In addition, by utilizing the paired data examples, we are able to improve the overall accuracy over the model trained using larger unpaired data set, while decreasing the computational cost of the model training.