 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
An Extended Variational Mode Decomposition Algorithm Developed Speech Emotion Recognition Performance
Dec 18, 2023
Emotion recognition (ER) from speech signals is a robust approach since it cannot be imitated like facial expression or text based sentiment analysis. Valuable information underlying the emotions are significant for human-computer interactions enabling intelligent machines to interact with sensitivity in the real world. Previous ER studies through speech signal processing have focused exclusively on associations between different signal mode decomposition methods and hidden informative features. However, improper decomposition parameter selections lead to informative signal component losses due to mode duplicating and mixing. In contrast, the current study proposes VGG-optiVMD, an empowered variational mode decomposition algorithm, to distinguish meaningful speech features and automatically select the number of decomposed modes and optimum balancing parameter for the data fidelity constraint by assessing their effects on the VGG16 flattening output layer. Various feature vectors were employed to train the VGG16 network on different databases and assess VGG-optiVMD reproducibility and reliability. One, two, and three-dimensional feature vectors were constructed by concatenating Mel-frequency cepstral coefficients, Chromagram, Mel spectrograms, Tonnetz diagrams, and spectral centroids. Results confirmed a synergistic relationship between the fine-tuning of the signal sample rate and decomposition parameters with classification accuracy, achieving state-of-the-art 96.09% accuracy in predicting seven emotions on the Berlin EMO-DB database.
* 12 pages
App for Resume-Based Job Matching with Speech Interviews and Grammar Analysis: A Review
Nov 20, 2023Through the advancement in natural language processing (NLP), specifically in speech recognition, fully automated complex systems functioning on voice input have started proliferating in areas such as home automation. These systems have been termed Automatic Speech Recognition Systems (ASR). In this review paper, we explore the feasibility of an end-to-end system providing speech and text based natural language processing for job interview preparation as well as recommendation of relevant job postings. We also explore existing recommender-based systems and note their limitations. This literature review would help us identify the approaches and limitations of the various similar use-cases of NLP technology for our upcoming project.
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 23, 2023Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
Meta-AF Echo Cancellation for Improved Keyword Spotting
Dec 17, 2023Adaptive filters (AFs) are vital for enhancing the performance of downstream tasks, such as speech recognition, sound event detection, and keyword spotting. However, traditional AF design prioritizes isolated signal-level objectives, often overlooking downstream task performance. This can lead to suboptimal performance. Recent research has leveraged meta-learning to automatically learn AF update rules from data, alleviating the need for manual tuning when using simple signal-level objectives. This paper improves the Meta-AF framework by expanding it to support end-to-end training for arbitrary downstream tasks. We focus on classification tasks, where we introduce a novel training methodology that harnesses self-supervision and classifier feedback. We evaluate our approach on the combined task of acoustic echo cancellation and keyword spotting. Our findings demonstrate consistent performance improvements with both pre-trained and joint-trained keyword spotting models across synthetic and real playback. Notably, these improvements come without requiring additional tuning, increased inference-time complexity, or reliance on oracle signal-level training data.
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023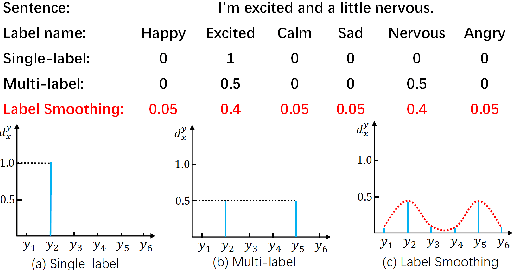

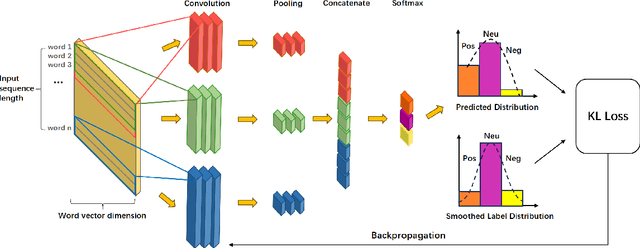
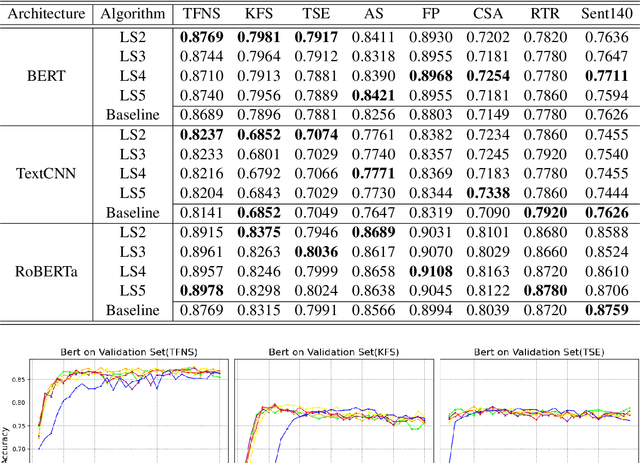
Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
Iterative Shallow Fusion of Backward Language Model for End-to-End Speech Recognition
Oct 17, 2023We propose a new shallow fusion (SF) method to exploit an external backward language model (BLM) for end-to-end automatic speech recognition (ASR). The BLM has complementary characteristics with a forward language model (FLM), and the effectiveness of their combination has been confirmed by rescoring ASR hypotheses as post-processing. In the proposed SF, we iteratively apply the BLM to partial ASR hypotheses in the backward direction (i.e., from the possible next token to the start symbol) during decoding, substituting the newly calculated BLM scores for the scores calculated at the last iteration. To enhance the effectiveness of this iterative SF (ISF), we train a partial sentence-aware BLM (PBLM) using reversed text data including partial sentences, considering the framework of ISF. In experiments using an attention-based encoder-decoder ASR system, we confirmed that ISF using the PBLM shows comparable performance with SF using the FLM. By performing ISF, early pruning of prospective hypotheses can be prevented during decoding, and we can obtain a performance improvement compared to applying the PBLM as post-processing. Finally, we confirmed that, by combining SF and ISF, further performance improvement can be obtained thanks to the complementarity of the FLM and PBLM.
Speech and Text-Based Emotion Recognizer
Dec 10, 2023Affective computing is a field of study that focuses on developing systems and technologies that can understand, interpret, and respond to human emotions. Speech Emotion Recognition (SER), in particular, has got a lot of attention from researchers in the recent past. However, in many cases, the publicly available datasets, used for training and evaluation, are scarce and imbalanced across the emotion labels. In this work, we focused on building a balanced corpus from these publicly available datasets by combining these datasets as well as employing various speech data augmentation techniques. Furthermore, we experimented with different architectures for speech emotion recognition. Our best system, a multi-modal speech, and text-based model, provides a performance of UA(Unweighed Accuracy) + WA (Weighed Accuracy) of 157.57 compared to the baseline algorithm performance of 119.66
Phoneme-aware Encoding for Prefix-tree-based Contextual ASR
Dec 15, 2023In speech recognition applications, it is important to recognize context-specific rare words, such as proper nouns. Tree-constrained Pointer Generator (TCPGen) has shown promise for this purpose, which efficiently biases such words with a prefix tree. While the original TCPGen relies on grapheme-based encoding, we propose extending it with phoneme-aware encoding to better recognize words of unusual pronunciations. As TCPGen handles biasing words as subword units, we propose obtaining subword-level phoneme-aware encoding by using alignment between phonemes and subwords. Furthermore, we propose injecting phoneme-level predictions from CTC into queries of TCPGen so that the model better interprets the phoneme-aware encodings. We conducted ASR experiments with TCPGen for RNN transducer. We observed that proposed phoneme-aware encoding outperformed ordinary grapheme-based encoding on both the English LibriSpeech and Japanese CSJ datasets, demonstrating the robustness of our approach across linguistically diverse languages.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 08, 2023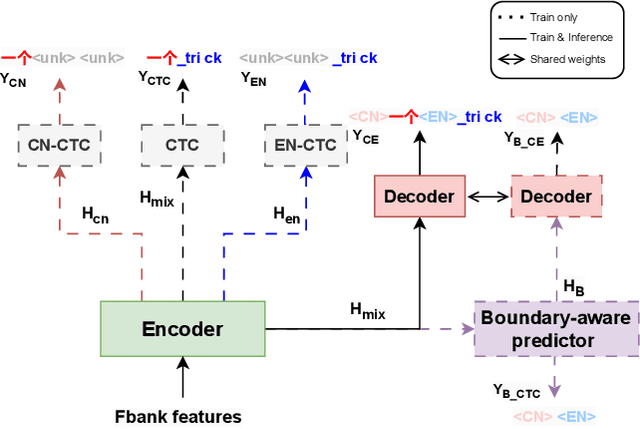
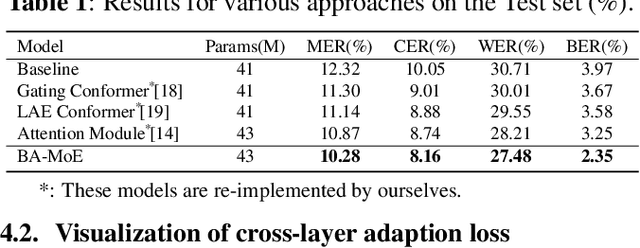
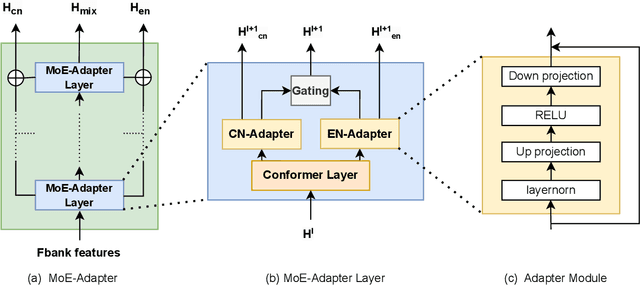
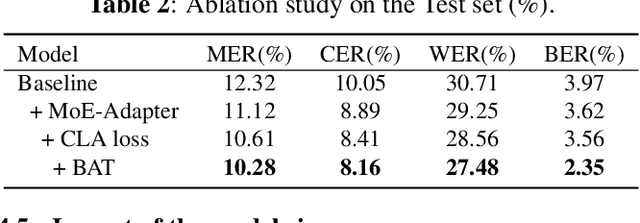
Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.