 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Dual-Attention Neural Transducers for Efficient Wake Word Spotting in Speech Recognition
Apr 03, 2023
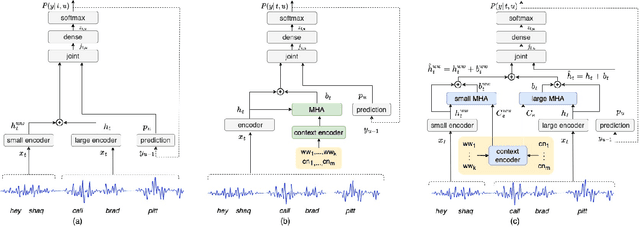
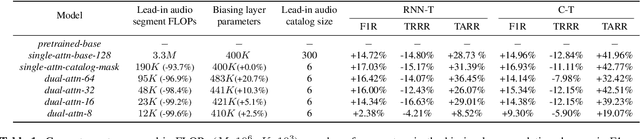
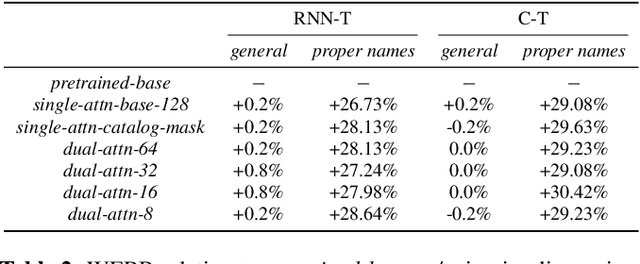
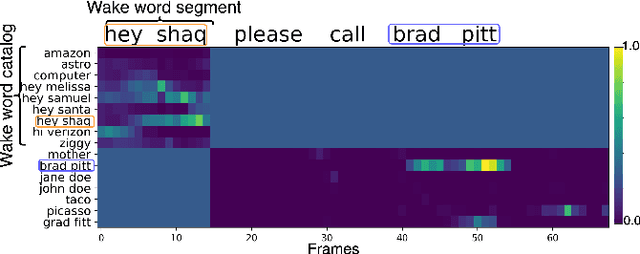
We present dual-attention neural biasing, an architecture designed to boost Wake Words (WW) recognition and improve inference time latency on speech recognition tasks. This architecture enables a dynamic switch for its runtime compute paths by exploiting WW spotting to select which branch of its attention networks to execute for an input audio frame. With this approach, we effectively improve WW spotting accuracy while saving runtime compute cost as defined by floating point operations (FLOPs). Using an in-house de-identified dataset, we demonstrate that the proposed dual-attention network can reduce the compute cost by $90\%$ for WW audio frames, with only $1\%$ increase in the number of parameters. This architecture improves WW F1 score by $16\%$ relative and improves generic rare word error rate by $3\%$ relative compared to the baselines.
Exploring Self-supervised Pre-trained ASR Models For Dysarthric and Elderly Speech Recognition
Feb 28, 2023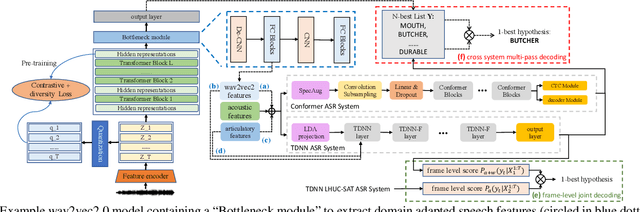
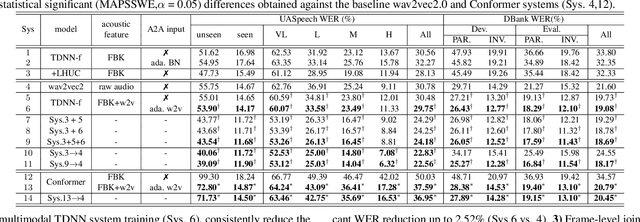
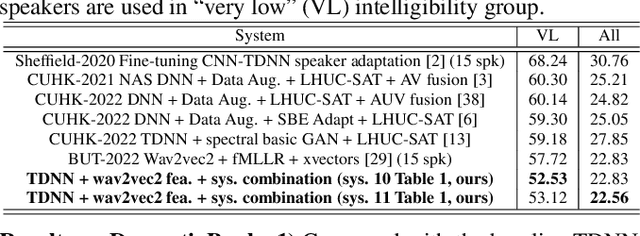

Automatic recognition of disordered and elderly speech remains a highly challenging task to date due to the difficulty in collecting such data in large quantities. This paper explores a series of approaches to integrate domain adapted SSL pre-trained models into TDNN and Conformer ASR systems for dysarthric and elderly speech recognition: a) input feature fusion between standard acoustic frontends and domain adapted wav2vec2.0 speech representations; b) frame-level joint decoding of TDNN systems separately trained using standard acoustic features alone and with additional wav2vec2.0 features; and c) multi-pass decoding involving the TDNN/Conformer system outputs to be rescored using domain adapted wav2vec2.0 models. In addition, domain adapted wav2vec2.0 representations are utilized in acoustic-to-articulatory (A2A) inversion to construct multi-modal dysarthric and elderly speech recognition systems. Experiments conducted on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest TDNN and Conformer ASR systems integrated domain adapted wav2vec2.0 models consistently outperform the standalone wav2vec2.0 models by statistically significant WER reductions of 8.22% and 3.43% absolute (26.71% and 15.88% relative) on the two tasks respectively. The lowest published WERs of 22.56% (52.53% on very low intelligibility, 39.09% on unseen words) and 18.17% are obtained on the UASpeech test set of 16 dysarthric speakers, and the DementiaBank Pitt test set respectively.
Code-Switched Urdu ASR for Noisy Telephonic Environment using Data Centric Approach with Hybrid HMM and CNN-TDNN
Jul 24, 2023Call Centers have huge amount of audio data which can be used for achieving valuable business insights and transcription of phone calls is manually tedious task. An effective Automated Speech Recognition system can accurately transcribe these calls for easy search through call history for specific context and content allowing automatic call monitoring, improving QoS through keyword search and sentiment analysis. ASR for Call Center requires more robustness as telephonic environment are generally noisy. Moreover, there are many low-resourced languages that are on verge of extinction which can be preserved with help of Automatic Speech Recognition Technology. Urdu is the $10^{th}$ most widely spoken language in the world, with 231,295,440 worldwide still remains a resource constrained language in ASR. Regional call-center conversations operate in local language, with a mix of English numbers and technical terms generally causing a "code-switching" problem. Hence, this paper describes an implementation framework of a resource efficient Automatic Speech Recognition/ Speech to Text System in a noisy call-center environment using Chain Hybrid HMM and CNN-TDNN for Code-Switched Urdu Language. Using Hybrid HMM-DNN approach allowed us to utilize the advantages of Neural Network with less labelled data. Adding CNN with TDNN has shown to work better in noisy environment due to CNN's additional frequency dimension which captures extra information from noisy speech, thus improving accuracy. We collected data from various open sources and labelled some of the unlabelled data after analysing its general context and content from Urdu language as well as from commonly used words from other languages, primarily English and were able to achieve WER of 5.2% with noisy as well as clean environment in isolated words or numbers as well as in continuous spontaneous speech.
Self-regularised Minimum Latency Training for Streaming Transformer-based Speech Recognition
Apr 24, 2023
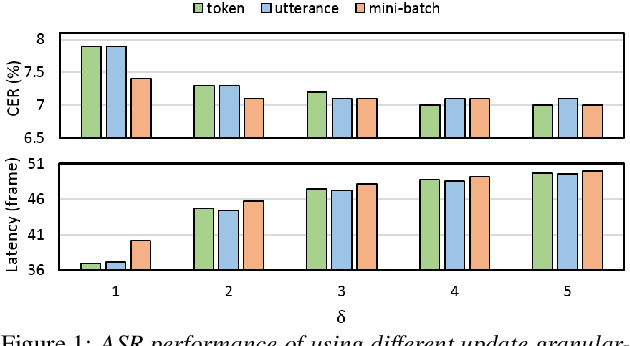
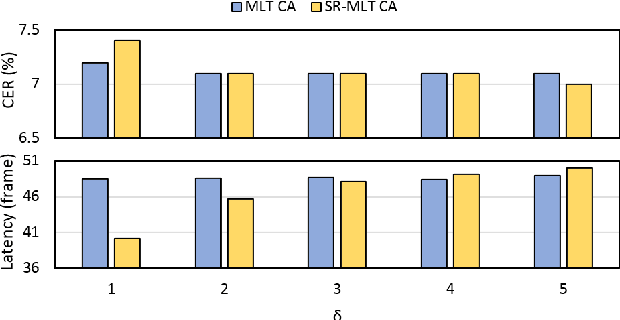
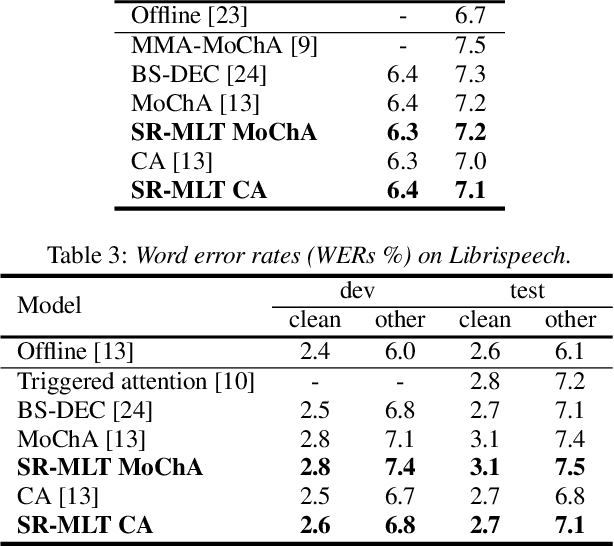
This paper proposes a self-regularised minimum latency training (SR-MLT) method for streaming Transformer-based automatic speech recognition (ASR) systems. In previous works, latency was optimised by truncating the online attention weights based on the hard alignments obtained from conventional ASR models, without taking into account the potential loss of ASR accuracy. On the contrary, here we present a strategy to obtain the alignments as a part of the model training without external supervision. The alignments produced by the proposed method are dynamically regularised on the training data, such that the latency reduction does not result in the loss of ASR accuracy. SR-MLT is applied as a fine-tuning step on the pre-trained Transformer models that are based on either monotonic chunkwise attention (MoChA) or cumulative attention (CA) algorithms for online decoding. ASR experiments on the AIShell-1 and Librispeech datasets show that when applied on a decent pre-trained MoChA or CA baseline model, SR-MLT can effectively reduce the latency with the relative gains ranging from 11.8% to 39.5%. Furthermore, we also demonstrate that under certain accuracy levels, the models trained with SR-MLT can achieve lower latency when compared to those supervised using external hard alignments.
Leveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023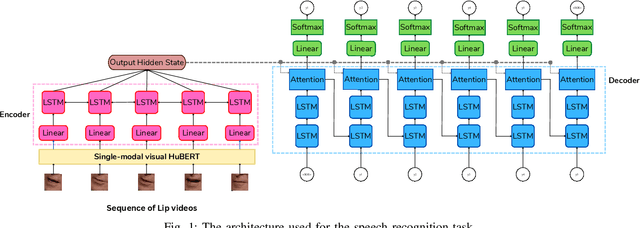
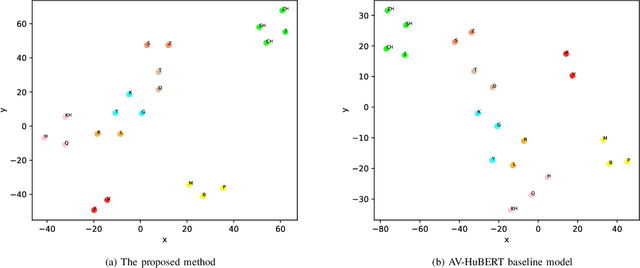
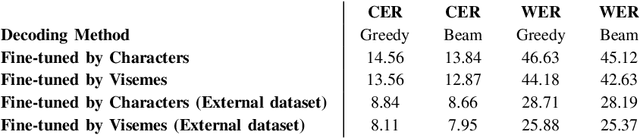
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
Pyramid Multi-branch Fusion DCNN with Multi-Head Self-Attention for Mandarin Speech Recognition
Mar 23, 2023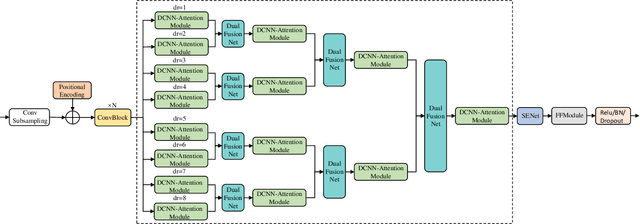

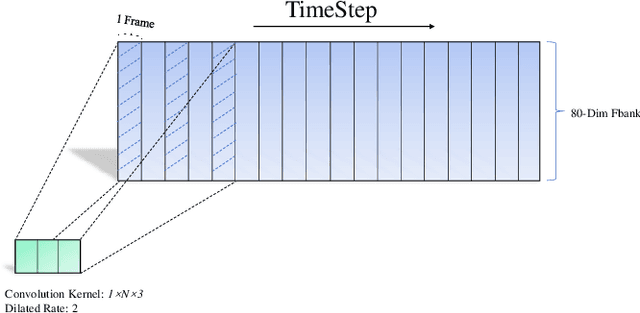

As one of the major branches of automatic speech recognition, attention-based models greatly improves the feature representation ability of the model. In particular, the multi-head mechanism is employed in the attention, hoping to learn speech features of more aspects in different attention subspaces. For speech recognition of complex languages, on the one hand, a small head size will lead to an obvious shortage of learnable aspects. On the other hand, we need to reduce the dimension of each subspace to keep the size of the overall feature space unchanged when we increase the number of heads, which will significantly weaken the ability to represent the feature of each subspace. Therefore, this paper explores how to use a small attention subspace to represent complete speech features while ensuring many heads. In this work we propose a novel neural network architecture, namely, pyramid multi-branch fusion DCNN with multi-head self-attention. The proposed architecture is inspired by Dilated Convolution Neural Networks (DCNN), it uses multiple branches with DCNN to extract the feature of the input speech under different receptive fields. To reduce the number of parameters, every two branches are merged until all the branches are merged into one. Thus, its shape is like a pyramid rotated 90 degrees. We demonstrate that on Aishell-1, a widely used Mandarin speech dataset, our model achieves a character error rate (CER) of 6.45% on the test sets.
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023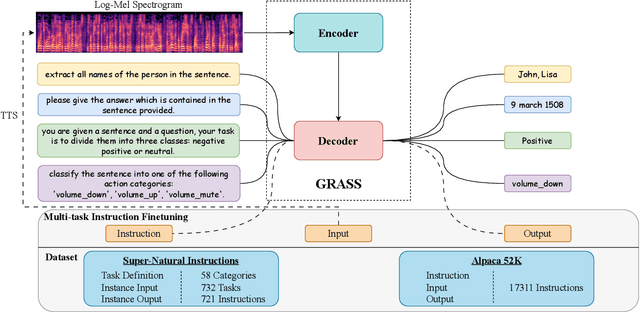
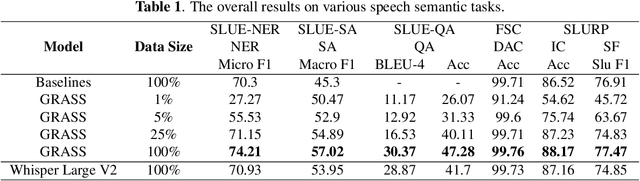

This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Injecting Categorical Labels and Syntactic Information into Biomedical NER
Nov 06, 2023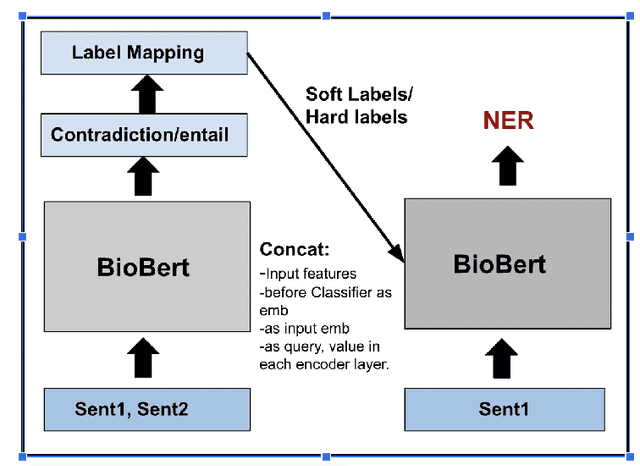
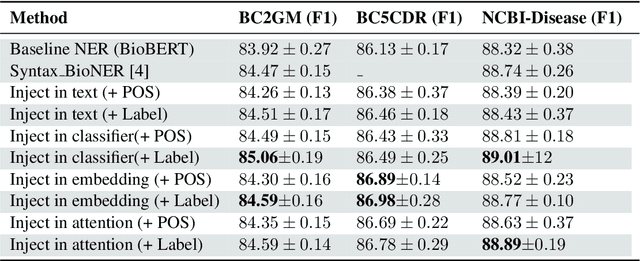

We present a simple approach to improve biomedical named entity recognition (NER) by injecting categorical labels and Part-of-speech (POS) information into the model. We use two approaches, in the first approach, we first train a sequence-level classifier to classify the sentences into categories to obtain the sentence-level tags (categorical labels). The sequence classifier is modeled as an entailment problem by modifying the labels as a natural language template. This helps to improve the accuracy of the classifier. Further, this label information is injected into the NER model. In this paper, we demonstrate effective ways to represent and inject these labels and POS attributes into the NER model. In the second approach, we jointly learn the categorical labels and NER labels. Here we also inject the POS tags into the model to increase the syntactic context of the model. Experiments on three benchmark datasets show that incorporating categorical label information with syntactic context is quite useful and outperforms baseline BERT-based models.
A Sidecar Separator Can Convert a Single-Talker Speech Recognition System to a Multi-Talker One
Mar 05, 2023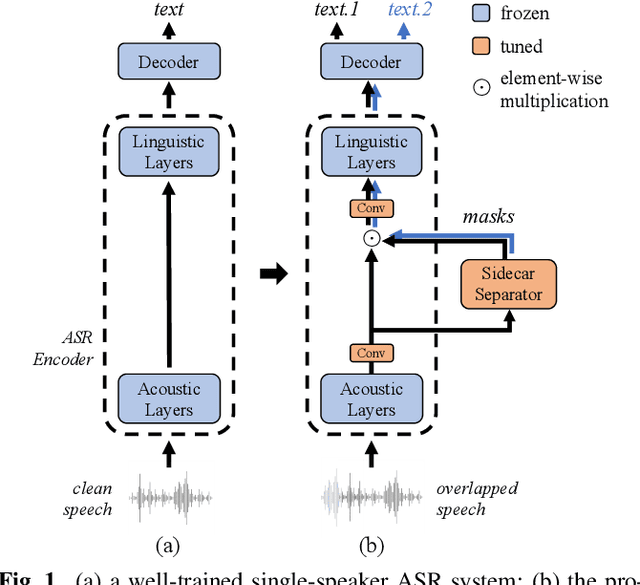
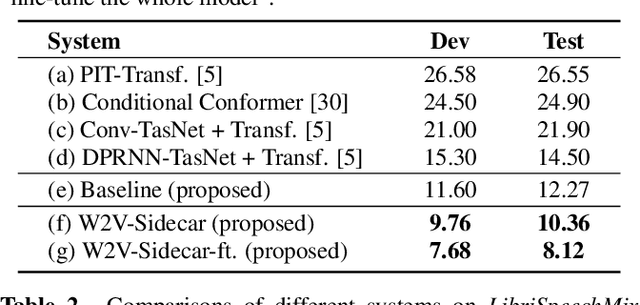
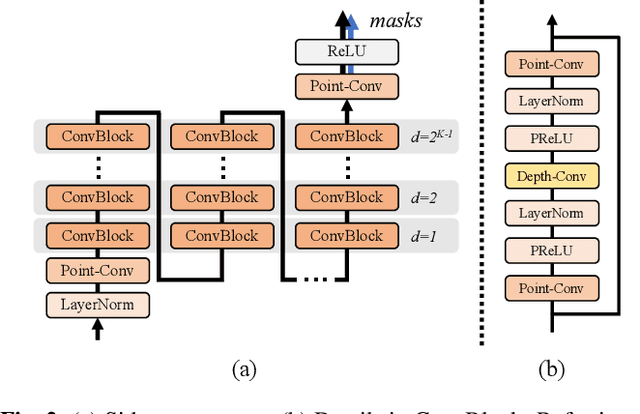
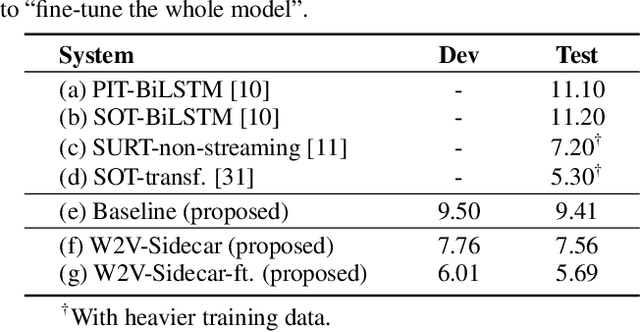
Although automatic speech recognition (ASR) can perform well in common non-overlapping environments, sustaining performance in multi-talker overlapping speech recognition remains challenging. Recent research revealed that ASR model's encoder captures different levels of information with different layers -- the lower layers tend to have more acoustic information, and the upper layers more linguistic. This inspires us to develop a Sidecar separator to empower a well-trained ASR model for multi-talker scenarios by separating the mixed speech embedding between two suitable layers. We experimented with a wav2vec 2.0-based ASR model with a Sidecar mounted. By freezing the parameters of the original model and training only the Sidecar (8.7 M, 8.4% of all parameters), the proposed approach outperforms the previous state-of-the-art by a large margin for the 2-speaker mixed LibriMix dataset, reaching a word error rate (WER) of 10.36%; and obtains comparable results (7.56%) for LibriSpeechMix dataset when limited training.
End-to-End Speech Recognition: A Survey
Mar 03, 2023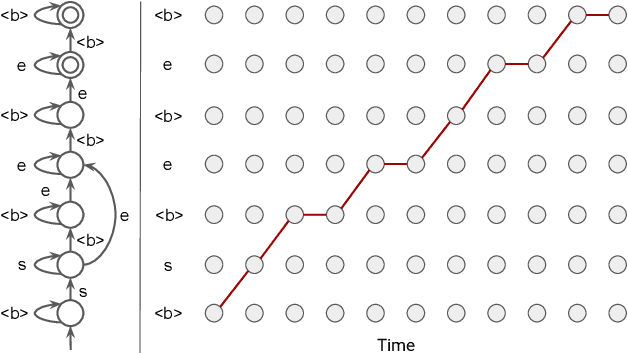
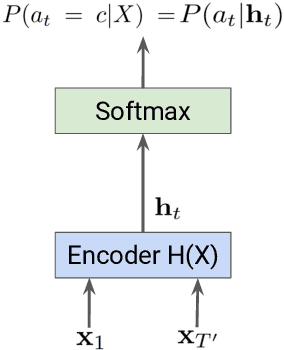
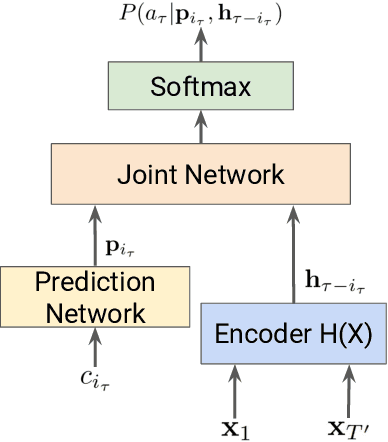

In the last decade of automatic speech recognition (ASR) research, the introduction of deep learning brought considerable reductions in word error rate of more than 50% relative, compared to modeling without deep learning. In the wake of this transition, a number of all-neural ASR architectures were introduced. These so-called end-to-end (E2E) models provide highly integrated, completely neural ASR models, which rely strongly on general machine learning knowledge, learn more consistently from data, while depending less on ASR domain-specific experience. The success and enthusiastic adoption of deep learning accompanied by more generic model architectures lead to E2E models now becoming the prominent ASR approach. The goal of this survey is to provide a taxonomy of E2E ASR models and corresponding improvements, and to discuss their properties and their relation to the classical hidden Markov model (HMM) based ASR architecture. All relevant aspects of E2E ASR are covered in this work: modeling, training, decoding, and external language model integration, accompanied by discussions of performance and deployment opportunities, as well as an outlook into potential future developments.