 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Long-Running Speech Recognizer:An End-to-End Multi-Task Learning Framework for Online ASR and VAD
Mar 02, 2021
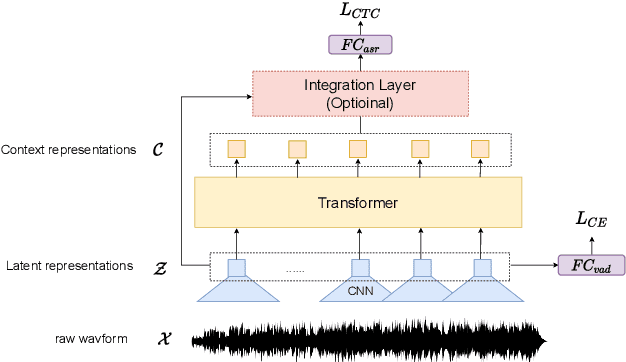
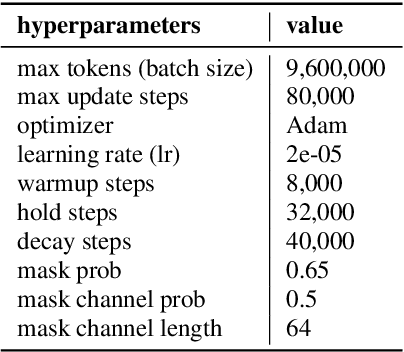
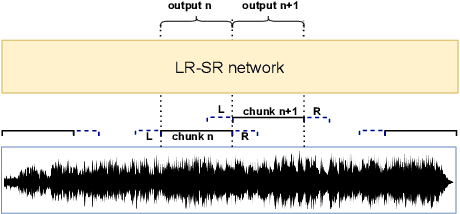

When we use End-to-end automatic speech recognition (E2E-ASR) system for real-world applications, a voice activity detection (VAD) system is usually needed to improve the performance and to reduce the computational cost by discarding non-speech parts in the audio. This paper presents a novel end-to-end (E2E), multi-task learning (MTL) framework that integrates ASR and VAD into one model. The proposed system, which we refer to as Long-Running Speech Recognizer (LR-SR), learns ASR and VAD jointly from two seperate task-specific datasets in the training stage. With the assistance of VAD, the ASR performance improves as its connectionist temporal classification (CTC) loss function can leverage the VAD alignment information. In the inference stage, the LR-SR system removes non-speech parts at low computational cost and recognizes speech parts with high robustness. Experimental results on segmented speech data show that the proposed MTL framework outperforms the baseline single-task learning (STL) framework in ASR task. On unsegmented speech data, we find that the LR-SR system outperforms the baseline ASR systems that build an extra GMM-based or DNN-based voice activity detector.
A Resource for Computational Experiments on Mapudungun
Dec 04, 2019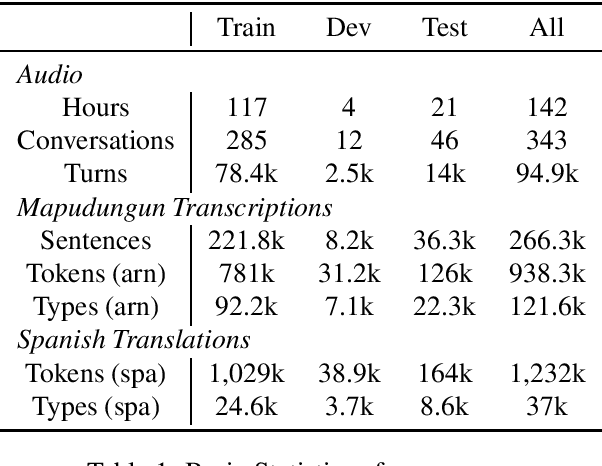

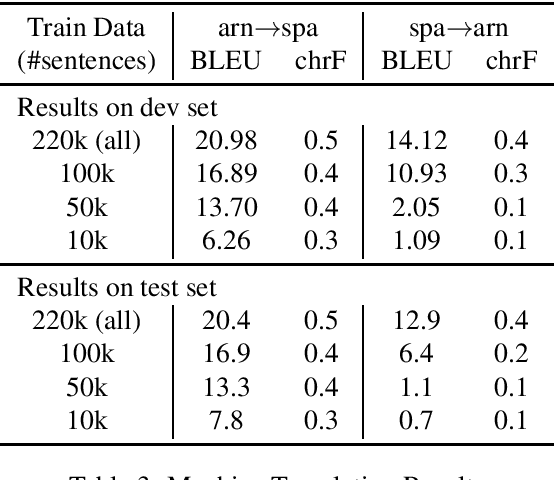
We present a resource for computational experiments on Mapudungun, a polysynthetic indigenous language spoken in Chile with upwards of 200 thousand speakers. We provide 142 hours of culturally significant conversations in the domain of medical treatment. The conversations are fully transcribed and translated into Spanish. The transcriptions also include annotations for code-switching and non-standard pronunciations. We also provide baseline results on three core NLP tasks: speech recognition, speech synthesis, and machine translation between Spanish and Mapudungun. We further explore other applications for which the corpus will be suitable, including the study of code-switching, historical orthography change, linguistic structure, and sociological and anthropological studies.
Adapting Pretrained Transformer to Lattices for Spoken Language Understanding
Nov 02, 2020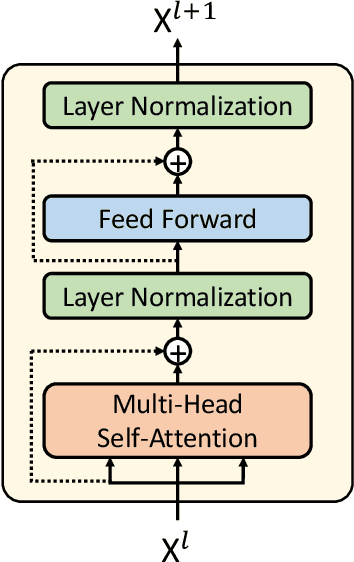
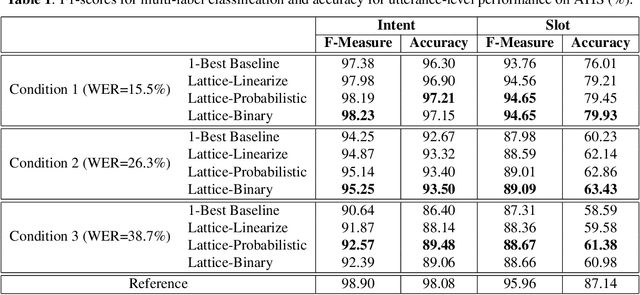

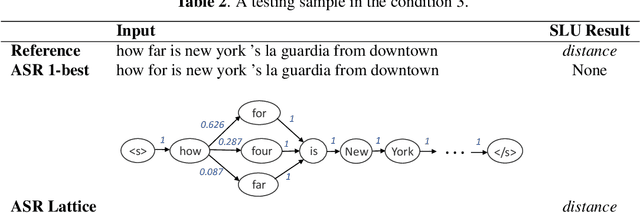
Lattices are compact representations that encode multiple hypotheses, such as speech recognition results or different word segmentations. It is shown that encoding lattices as opposed to 1-best results generated by automatic speech recognizer (ASR) boosts the performance of spoken language understanding (SLU). Recently, pretrained language models with the transformer architecture have achieved the state-of-the-art results on natural language understanding, but their ability of encoding lattices has not been explored. Therefore, this paper aims at adapting pretrained transformers to lattice inputs in order to perform understanding tasks specifically for spoken language. Our experiments on the benchmark ATIS dataset show that fine-tuning pretrained transformers with lattice inputs yields clear improvement over fine-tuning with 1-best results. Further evaluation demonstrates the effectiveness of our methods under different acoustic conditions. Our code is available at https://github.com/MiuLab/Lattice-SLU
PhyAug: Physics-Directed Data Augmentation for Deep Sensing Model Transfer in Cyber-Physical Systems
Mar 31, 2021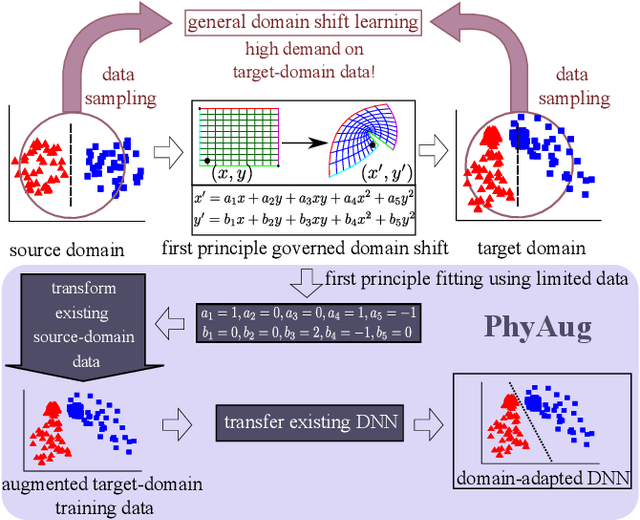
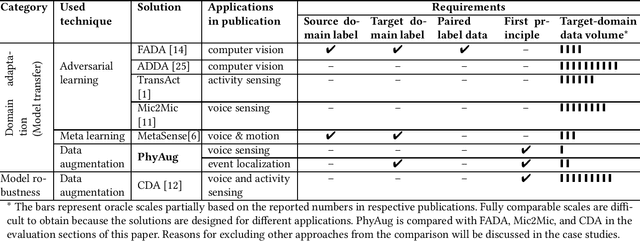
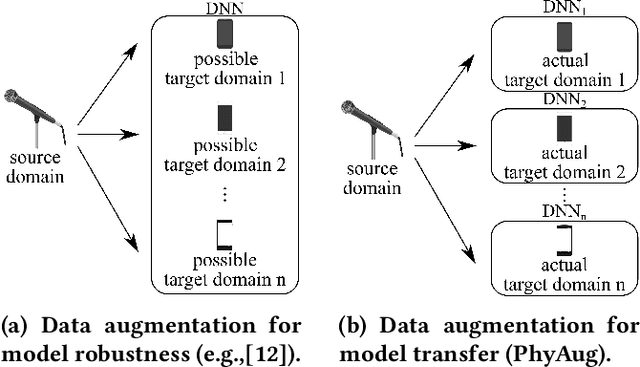

Run-time domain shifts from training-phase domains are common in sensing systems designed with deep learning. The shifts can be caused by sensor characteristic variations and/or discrepancies between the design-phase model and the actual model of the sensed physical process. To address these issues, existing transfer learning techniques require substantial target-domain data and thus incur high post-deployment overhead. This paper proposes to exploit the first principle governing the domain shift to reduce the demand on target-domain data. Specifically, our proposed approach called PhyAug uses the first principle fitted with few labeled or unlabeled source/target-domain data pairs to transform the existing source-domain training data into augmented data for updating the deep neural networks. In two case studies of keyword spotting and DeepSpeech2-based automatic speech recognition, with 5-second unlabeled data collected from the target microphones, PhyAug recovers the recognition accuracy losses due to microphone characteristic variations by 37% to 72%. In a case study of seismic source localization with TDoA fngerprints, by exploiting the frst principle of signal propagation in uneven media, PhyAug only requires 3% to 8% of labeled TDoA measurements required by the vanilla fingerprinting approach in achieving the same localization accuracy.
HLT-NUS SUBMISSION FOR 2020 NIST Conversational Telephone Speech SRE
Nov 12, 2021
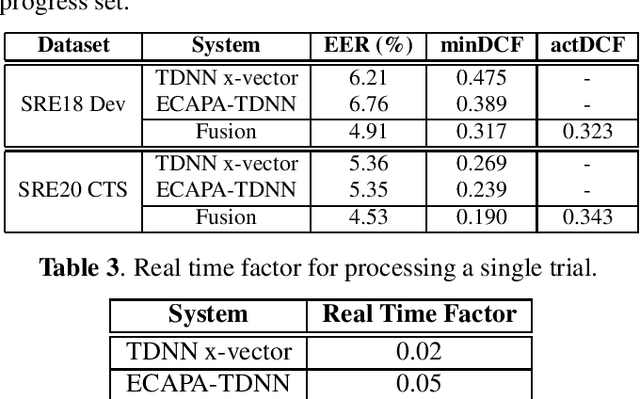
This work provides a brief description of Human Language Technology (HLT) Laboratory, National University of Singapore (NUS) system submission for 2020 NIST conversational telephone speech (CTS) speaker recognition evaluation (SRE). The challenge focuses on evaluation under CTS data containing multilingual speech. The systems developed at HLT-NUS consider time-delay neural network (TDNN) x-vector and ECAPA-TDNN systems. We also perform domain adaption of probabilistic linear discriminant analysis (PLDA) model and adaptive s-norm on our systems. The score level fusion of TDNN x-vector and ECAPA-TDNN systems is carried out, which improves the final system performance of our submission to 2020 NIST CTS SRE.
On the Effectiveness of Neural Text Generation based Data Augmentation for Recognition of Morphologically Rich Speech
Jun 09, 2020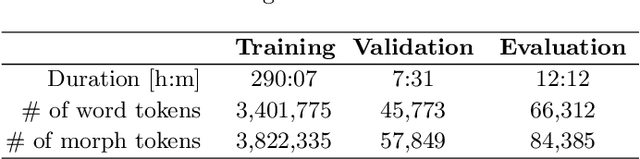
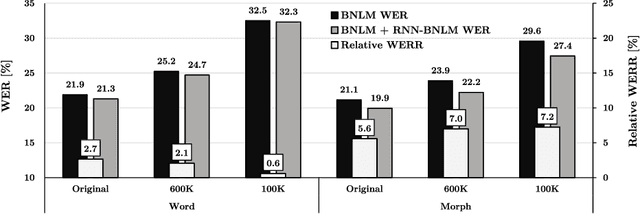
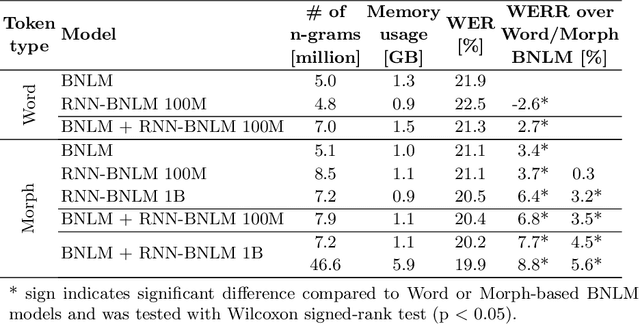
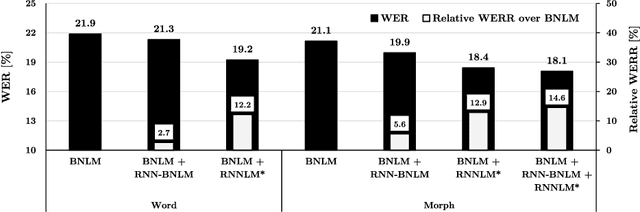
Advanced neural network models have penetrated Automatic Speech Recognition (ASR) in recent years, however, in language modeling many systems still rely on traditional Back-off N-gram Language Models (BNLM) partly or entirely. The reason for this are the high cost and complexity of training and using neural language models, mostly possible by adding a second decoding pass (rescoring). In our recent work we have significantly improved the online performance of a conversational speech transcription system by transferring knowledge from a Recurrent Neural Network Language Model (RNNLM) to the single pass BNLM with text generation based data augmentation. In the present paper we analyze the amount of transferable knowledge and demonstrate that the neural augmented LM (RNN-BNLM) can help to capture almost 50% of the knowledge of the RNNLM yet by dropping the second decoding pass and making the system real-time capable. We also systematically compare word and subword LMs and show that subword-based neural text augmentation can be especially beneficial in under-resourced conditions. In addition, we show that using the RNN-BNLM in the first pass followed by a neural second pass, offline ASR results can be even significantly improved.
Multi-scale Octave Convolutions for Robust Speech Recognition
Oct 31, 2019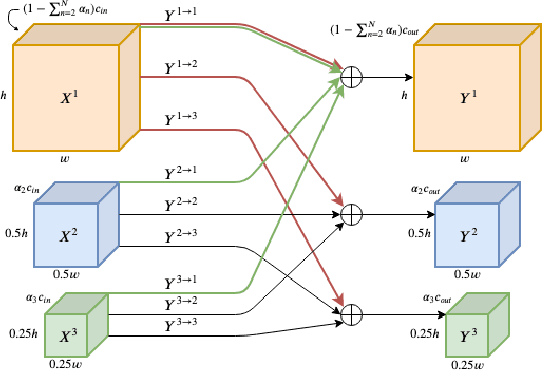
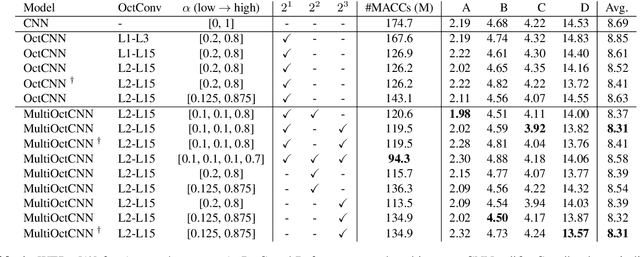
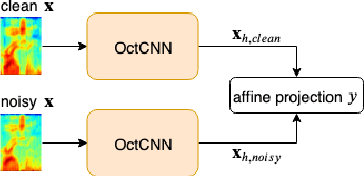
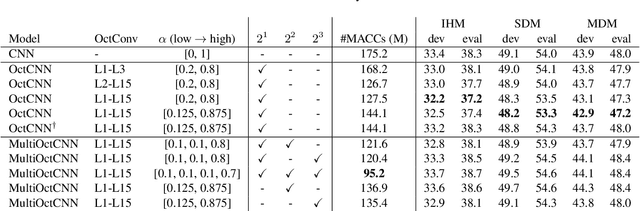
We propose a multi-scale octave convolution layer to learn robust speech representations efficiently. Octave convolutions were introduced by Chen et al [1] in the computer vision field to reduce the spatial redundancy of the feature maps by decomposing the output of a convolutional layer into feature maps at two different spatial resolutions, one octave apart. This approach improved the efficiency as well as the accuracy of the CNN models. The accuracy gain was attributed to the enlargement of the receptive field in the original input space. We argue that octave convolutions likewise improve the robustness of learned representations due to the use of average pooling in the lower resolution group, acting as a low-pass filter. We test this hypothesis by evaluating on two noisy speech corpora - Aurora-4 and AMI. We extend the octave convolution concept to multiple resolution groups and multiple octaves. To evaluate the robustness of the inferred representations, we report the similarity between clean and noisy encodings using an affine projection loss as a proxy robustness measure. The results show that proposed method reduces the WER by up to 6.6% relative for Aurora-4 and 3.6% for AMI, while improving the computational efficiency of the CNN acoustic models.
Robust Speaker Recognition Using Speech Enhancement And Attention Model
Jan 14, 2020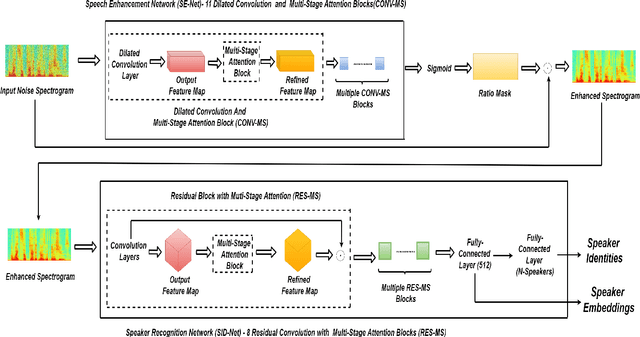
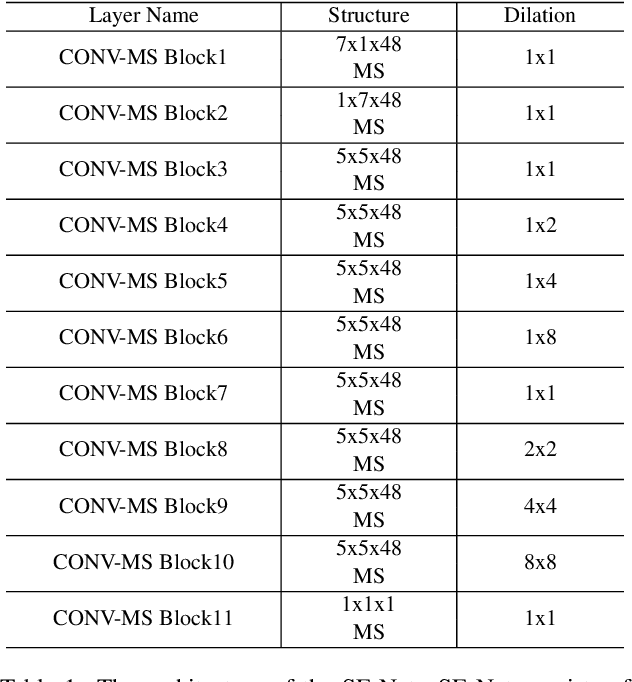
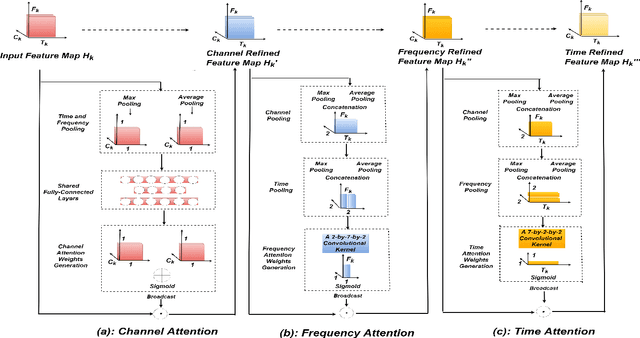
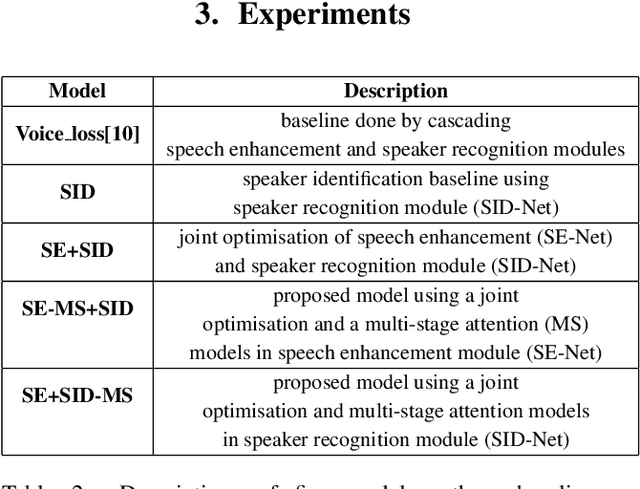
In this paper, a novel architecture for speaker recognition is proposed by cascading speech enhancement and speaker processing. Its aim is to improve speaker recognition performance when speech signals are corrupted by noise. Instead of individually processing speech enhancement and speaker recognition, the two modules are integrated into one framework by a joint optimisation using deep neural networks. Furthermore, to increase robustness against noise, a multi-stage attention mechanism is employed to highlight the speaker related features learned from context information in time and frequency domain. To evaluate speaker identification and verification performance of the proposed approach, we test it on the dataset of VoxCeleb1, one of mostly used benchmark datasets. Moreover, the robustness of our proposed approach is also tested on VoxCeleb1 data when being corrupted by three types of interferences, general noise, music, and babble, at different signal-to-noise ratio (SNR) levels. The obtained results show that the proposed approach using speech enhancement and multi-stage attention models outperforms two strong baselines not using them in most acoustic conditions in our experiments.
Exploring wav2vec 2.0 on speaker verification and language identification
Dec 11, 2020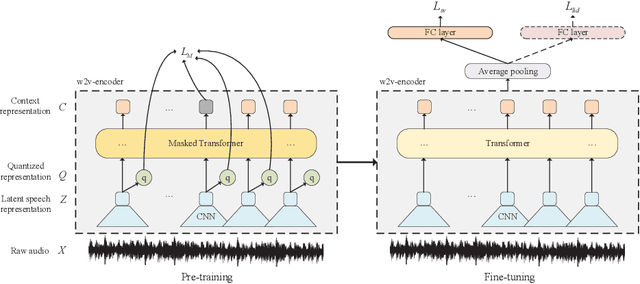



Wav2vec 2.0 is a recently proposed self-supervised framework for speech representation learning. It follows a two-stage training process of pre-training and fine-tuning, and performs well in speech recognition tasks especially ultra-low resource cases. In this work, we attempt to extend self-supervised framework to speaker verification and language identification. First, we use some preliminary experiments to indicate that wav2vec 2.0 can capture the information about the speaker and language. Then we demonstrate the effectiveness of wav2vec 2.0 on the two tasks respectively. For speaker verification, we obtain a new state-of-the-art result, Equal Error Rate (EER) of 3.61% on the VoxCeleb1 dataset. For language identification, we obtain an EER of 12.02% on 1 second condition and an EER of 3.47% on full-length condition of the AP17-OLR dataset. Finally, we utilize one model to achieve the unified modeling by the multi-task learning for the two tasks.
Data Techniques For Online End-to-end Speech Recognition
Jan 24, 2020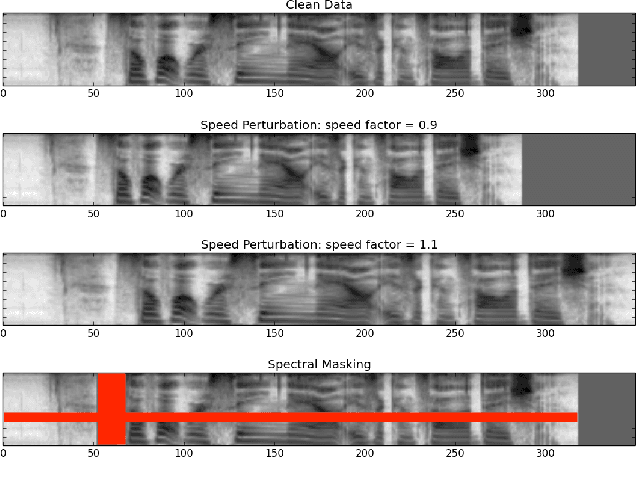



Practitioners often need to build ASR systems for new use cases in a short amount of time, given limited in-domain data. While recently developed end-to-end methods largely simplify the modeling pipelines, they still suffer from the data sparsity issue. In this work, we explore a few simple-to-implement techniques for building online ASR systems in an end-to-end fashion, with a small amount of transcribed data in the target domain. These techniques include data augmentation in the target domain, domain adaptation using models previously trained on a large source domain, and knowledge distillation on non-transcribed target domain data; they are applicable in real scenarios with different types of resources. Our experiments demonstrate that each technique is independently useful in the low-resource setting, and combining them yields significant improvement of the online ASR performance in the target domain.