 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Techniques For Online End-to-end Speech Recognition
Paper and Code
Jan 24, 2020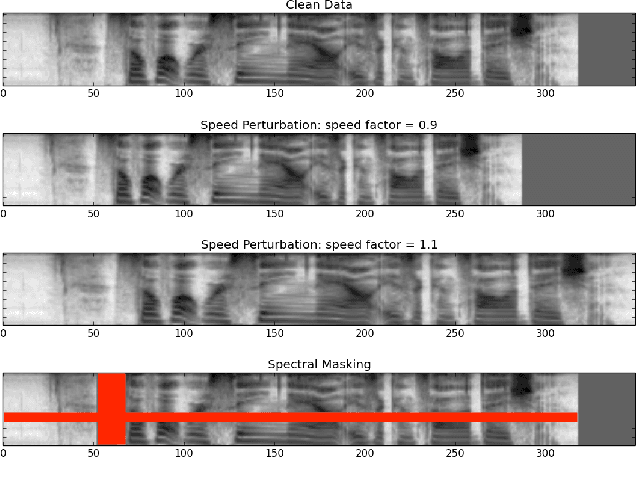



Practitioners often need to build ASR systems for new use cases in a short amount of time, given limited in-domain data. While recently developed end-to-end methods largely simplify the modeling pipelines, they still suffer from the data sparsity issue. In this work, we explore a few simple-to-implement techniques for building online ASR systems in an end-to-end fashion, with a small amount of transcribed data in the target domain. These techniques include data augmentation in the target domain, domain adaptation using models previously trained on a large source domain, and knowledge distillation on non-transcribed target domain data; they are applicable in real scenarios with different types of resources. Our experiments demonstrate that each technique is independently useful in the low-resource setting, and combining them yields significant improvement of the online ASR performance in the target domain.