 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speech Emotion Recognition via Contrastive Loss under Siamese Networks
Oct 23, 2019
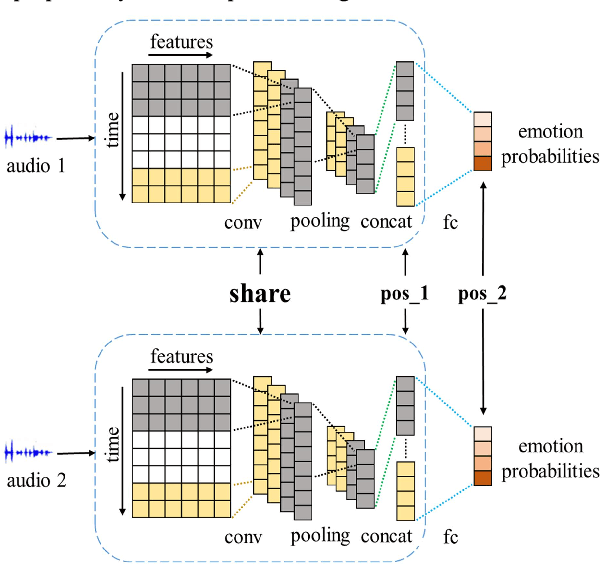
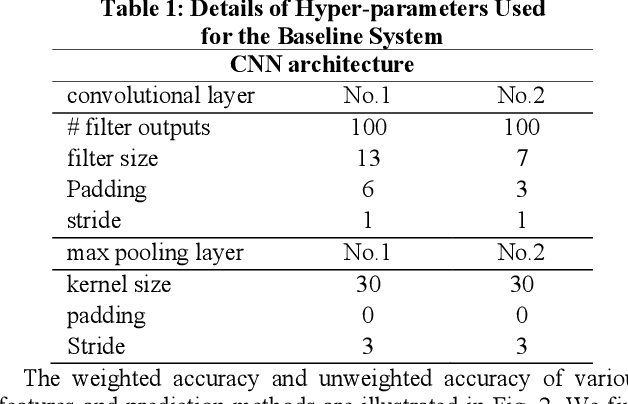
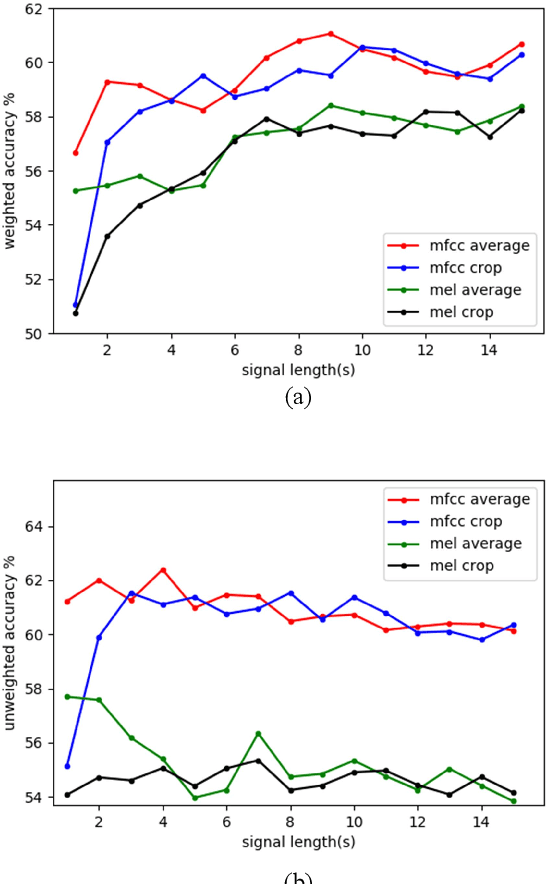
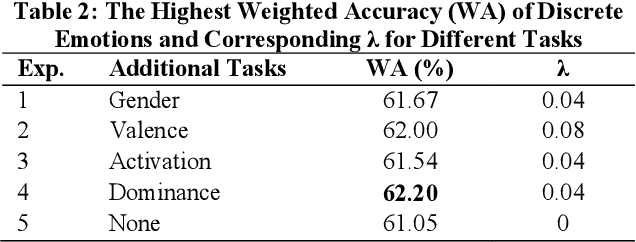
Speech emotion recognition is an important aspect of human-computer interaction. Prior work proposes various end-to-end models to improve the classification performance. However, most of them rely on the cross-entropy loss together with softmax as the supervision component, which does not explicitly encourage discriminative learning of features. In this paper, we introduce the contrastive loss function to encourage intra-class compactness and inter-class separability between learnable features. Furthermore, multiple feature selection methods and pairwise sample selection methods are evaluated. To verify the performance of the proposed system, we conduct experiments on The Interactive Emotional Dyadic Motion Capture (IEMOCAP) database, a common evaluation corpus. Experimental results reveal the advantages of the proposed method, which reaches 62.19% in the weighted accuracy and 63.21% in the unweighted accuracy. It outperforms the baseline system that is optimized without the contrastive loss function with 1.14% and 2.55% in the weighted accuracy and the unweighted accuracy, respectively.
Seed Words Based Data Selection for Language Model Adaptation
Jul 20, 2021

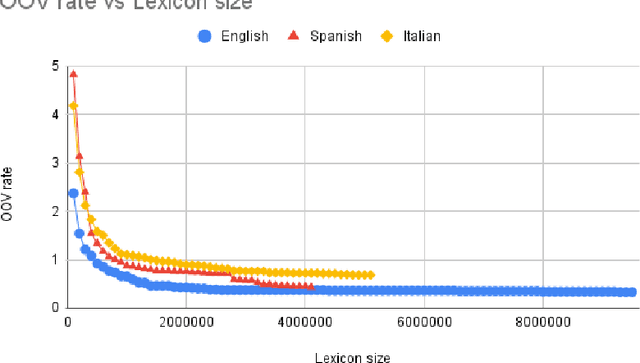
We address the problem of language model customization in applications where the ASR component needs to manage domain-specific terminology; although current state-of-the-art speech recognition technology provides excellent results for generic domains, the adaptation to specialized dictionaries or glossaries is still an open issue. In this work we present an approach for automatically selecting sentences, from a text corpus, that match, both semantically and morphologically, a glossary of terms (words or composite words) furnished by the user. The final goal is to rapidly adapt the language model of an hybrid ASR system with a limited amount of in-domain text data in order to successfully cope with the linguistic domain at hand; the vocabulary of the baseline model is expanded and tailored, reducing the resulting OOV rate. Data selection strategies based on shallow morphological seeds and semantic similarity viaword2vec are introduced and discussed; the experimental setting consists in a simultaneous interpreting scenario, where ASRs in three languages are designed to recognize the domain-specific terms (i.e. dentistry). Results using different metrics (OOV rate, WER, precision and recall) show the effectiveness of the proposed techniques.
Future Vector Enhanced LSTM Language Model for LVCSR
Jul 31, 2020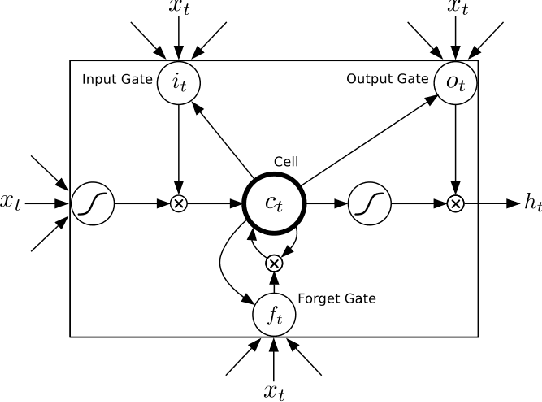

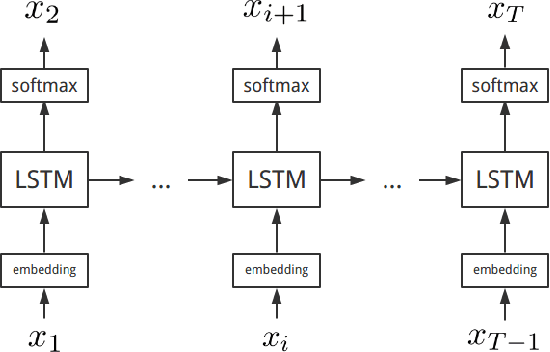
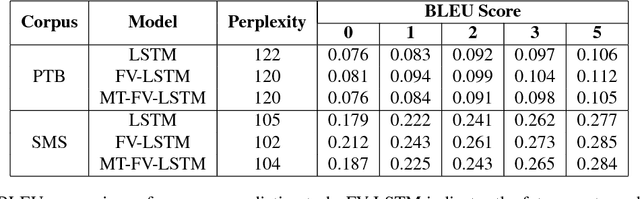
Language models (LM) play an important role in large vocabulary continuous speech recognition (LVCSR). However, traditional language models only predict next single word with given history, while the consecutive predictions on a sequence of words are usually demanded and useful in LVCSR. The mismatch between the single word prediction modeling in trained and the long term sequence prediction in read demands may lead to the performance degradation. In this paper, a novel enhanced long short-term memory (LSTM) LM using the future vector is proposed. In addition to the given history, the rest of the sequence will be also embedded by future vectors. This future vector can be incorporated with the LSTM LM, so it has the ability to model much longer term sequence level information. Experiments show that, the proposed new LSTM LM gets a better result on BLEU scores for long term sequence prediction. For the speech recognition rescoring, although the proposed LSTM LM obtains very slight gains, the new model seems obtain the great complementary with the conventional LSTM LM. Rescoring using both the new and conventional LSTM LMs can achieve a very large improvement on the word error rate.
Construction of a Large-scale Japanese ASR Corpus on TV Recordings
Mar 26, 2021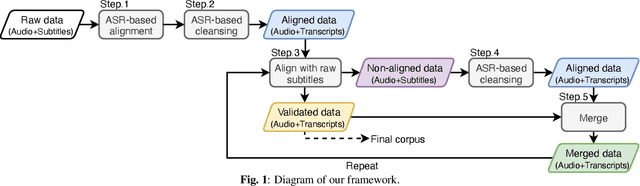
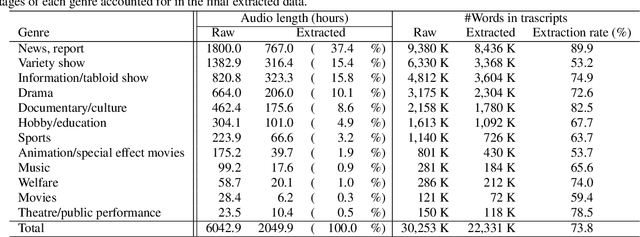
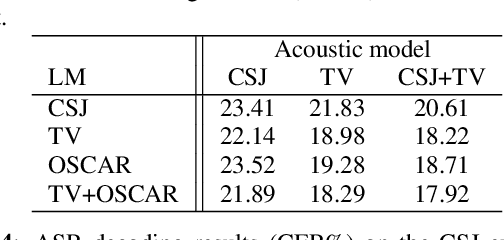
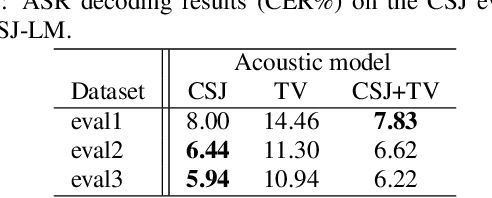
This paper presents a new large-scale Japanese speech corpus for training automatic speech recognition (ASR) systems. This corpus contains over 2,000 hours of speech with transcripts built on Japanese TV recordings and their subtitles. We develop herein an iterative workflow to extract matching audio and subtitle segments from TV recordings based on a conventional method for lightly-supervised audio-to-text alignment. We evaluate a model trained with our corpus using an evaluation dataset built on Japanese TEDx presentation videos and confirm that the performance is better than that trained with the Corpus of Spontaneous Japanese (CSJ). The experiment results show the usefulness of our corpus for training ASR systems. This corpus is made public for the research community along with Kaldi scripts for training the models reported in this paper.
MLS: A Large-Scale Multilingual Dataset for Speech Research
Dec 19, 2020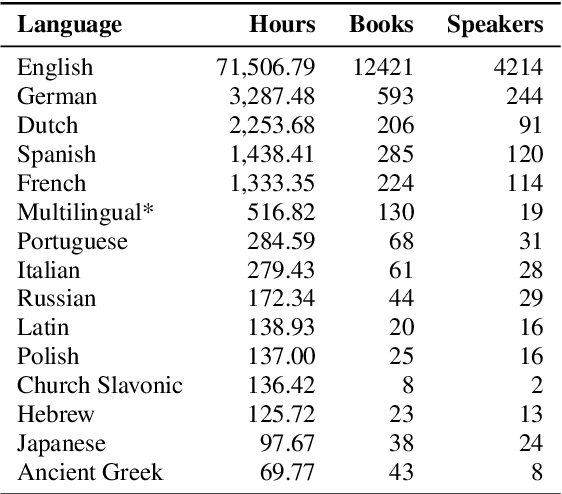
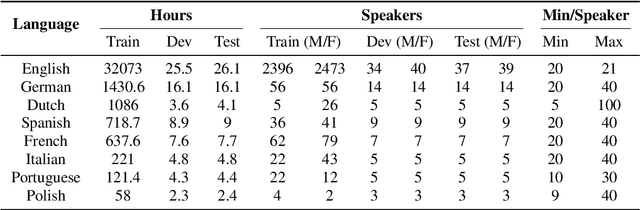
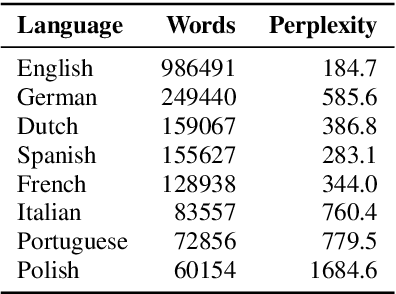
This paper introduces Multilingual LibriSpeech (MLS) dataset, a large multilingual corpus suitable for speech research. The dataset is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages. Additionally, we provide Language Models (LM) and baseline Automatic Speech Recognition (ASR) models and for all the languages in our dataset. We believe such a large transcribed dataset will open new avenues in ASR and Text-To-Speech (TTS) research. The dataset will be made freely available for anyone at http://www.openslr.org.
An exhaustive variable selection study for linear models of soundscape emotions: rankings and Gibbs analysis
Jul 26, 2022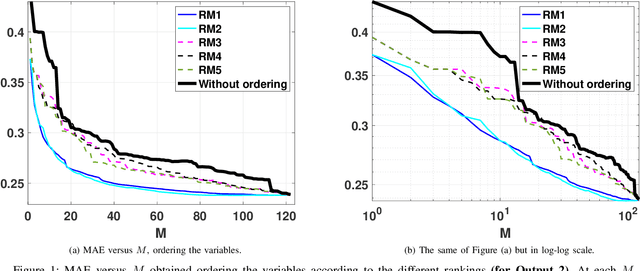
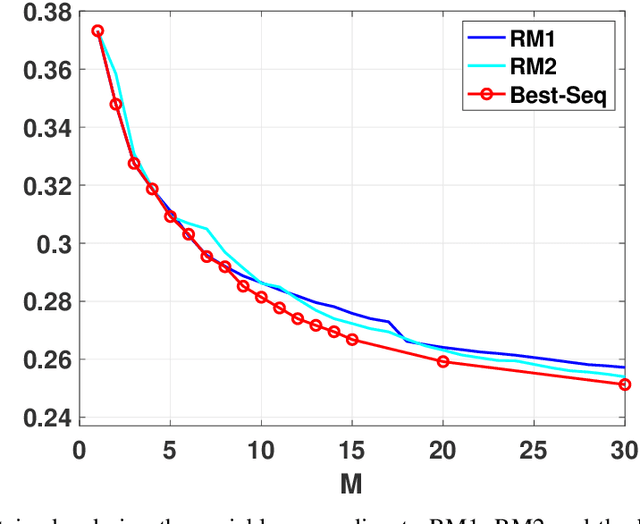
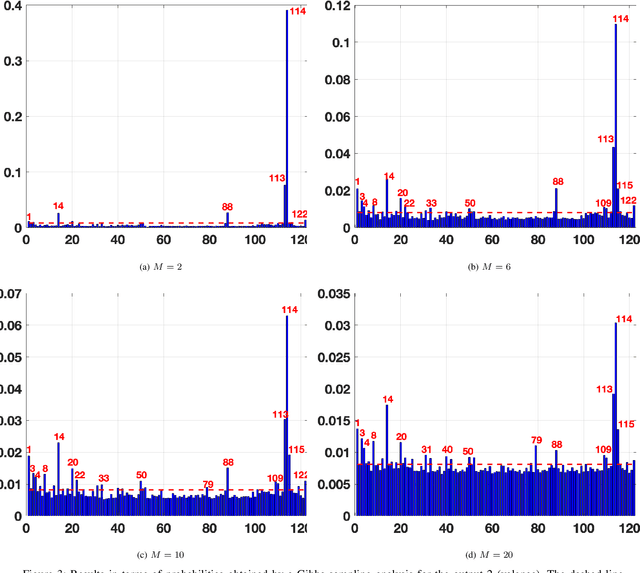

In the last decade, soundscapes have become one of the most active topics in Acoustics, providing a holistic approach to the acoustic environment, which involves human perception and context. Soundscapes-elicited emotions are central and substantially subtle and unnoticed (compared to speech or music). Currently, soundscape emotion recognition is a very active topic in the literature. We provide an exhaustive variable selection study (i.e., a selection of the soundscapes indicators) to a well-known dataset (emo-soundscapes). We consider linear soundscape emotion models for two soundscapes descriptors: arousal and valence. Several ranking schemes and procedures for selecting the number of variables are applied. We have also performed an alternating optimization scheme for obtaining the best sequences keeping fixed a certain number of features. Furthermore, we have designed a novel technique based on Gibbs sampling, which provides a more complete and clear view of the relevance of each variable. Finally, we have also compared our results with the analysis obtained by the classical methods based on p-values. As a result of our study, we suggest two simple and parsimonious linear models of only 7 and 16 variables (within the 122 possible features) for the two outputs (arousal and valence), respectively. The suggested linear models provide very good and competitive performance, with $R^2>0.86$ and $R^2>0.63$ (values obtained after a cross-validation procedure), respectively.
* published in IEEE-ACM Transactions on Audio, Speech and Language Processing
A novel policy for pre-trained Deep Reinforcement Learning for Speech Emotion Recognition
Jan 04, 2021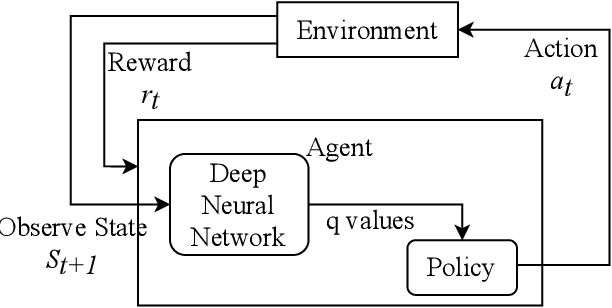


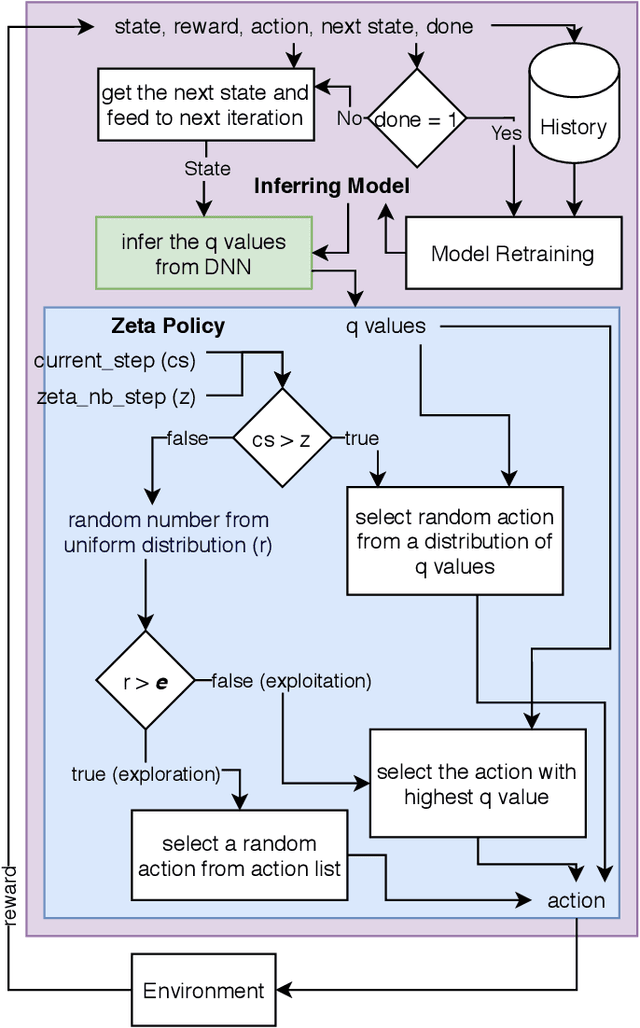
Reinforcement Learning (RL) is a semi-supervised learning paradigm which an agent learns by interacting with an environment. Deep learning in combination with RL provides an efficient method to learn how to interact with the environment is called Deep Reinforcement Learning (deep RL). Deep RL has gained tremendous success in gaming - such as AlphaGo, but its potential have rarely being explored for challenging tasks like Speech Emotion Recognition (SER). The deep RL being used for SER can potentially improve the performance of an automated call centre agent by dynamically learning emotional-aware response to customer queries. While the policy employed by the RL agent plays a major role in action selection, there is no current RL policy tailored for SER. In addition, extended learning period is a general challenge for deep RL which can impact the speed of learning for SER. Therefore, in this paper, we introduce a novel policy - "Zeta policy" which is tailored for SER and apply Pre-training in deep RL to achieve faster learning rate. Pre-training with cross dataset was also studied to discover the feasibility of pre-training the RL Agent with a similar dataset in a scenario of where no real environmental data is not available. IEMOCAP and SAVEE datasets were used for the evaluation with the problem being to recognize four emotions happy, sad, angry and neutral in the utterances provided. Experimental results show that the proposed "Zeta policy" performs better than existing policies. The results also support that pre-training can reduce the training time upon reducing the warm-up period and is robust to cross-corpus scenario.
CrypTen: Secure Multi-Party Computation Meets Machine Learning
Sep 02, 2021Secure multi-party computation (MPC) allows parties to perform computations on data while keeping that data private. This capability has great potential for machine-learning applications: it facilitates training of machine-learning models on private data sets owned by different parties, evaluation of one party's private model using another party's private data, etc. Although a range of studies implement machine-learning models via secure MPC, such implementations are not yet mainstream. Adoption of secure MPC is hampered by the absence of flexible software frameworks that "speak the language" of machine-learning researchers and engineers. To foster adoption of secure MPC in machine learning, we present CrypTen: a software framework that exposes popular secure MPC primitives via abstractions that are common in modern machine-learning frameworks, such as tensor computations, automatic differentiation, and modular neural networks. This paper describes the design of CrypTen and measure its performance on state-of-the-art models for text classification, speech recognition, and image classification. Our benchmarks show that CrypTen's GPU support and high-performance communication between (an arbitrary number of) parties allows it to perform efficient private evaluation of modern machine-learning models under a semi-honest threat model. For example, two parties using CrypTen can securely predict phonemes in speech recordings using Wav2Letter faster than real-time. We hope that CrypTen will spur adoption of secure MPC in the machine-learning community.
STRODE: Stochastic Boundary Ordinary Differential Equation
Jul 17, 2021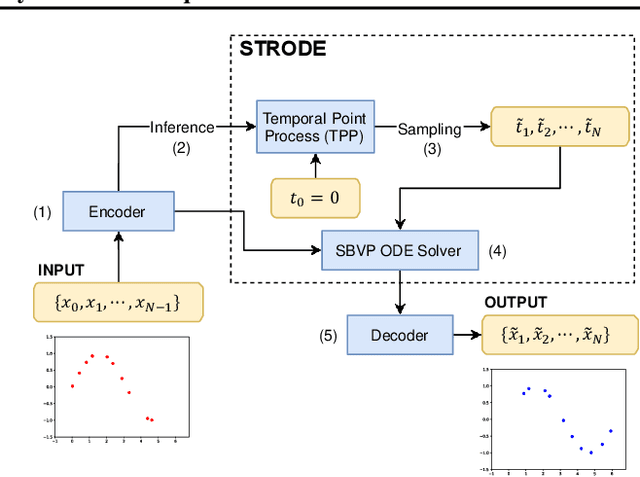

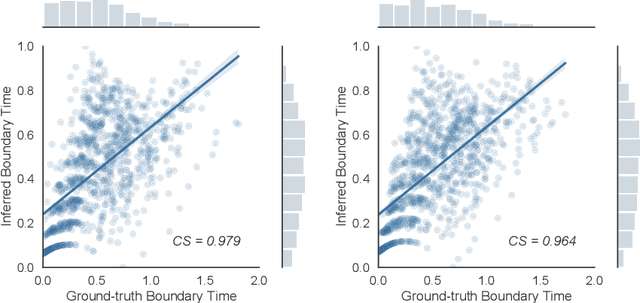

Perception of time from sequentially acquired sensory inputs is rooted in everyday behaviors of individual organisms. Yet, most algorithms for time-series modeling fail to learn dynamics of random event timings directly from visual or audio inputs, requiring timing annotations during training that are usually unavailable for real-world applications. For instance, neuroscience perspectives on postdiction imply that there exist variable temporal ranges within which the incoming sensory inputs can affect the earlier perception, but such temporal ranges are mostly unannotated for real applications such as automatic speech recognition (ASR). In this paper, we present a probabilistic ordinary differential equation (ODE), called STochastic boundaRy ODE (STRODE), that learns both the timings and the dynamics of time series data without requiring any timing annotations during training. STRODE allows the usage of differential equations to sample from the posterior point processes, efficiently and analytically. We further provide theoretical guarantees on the learning of STRODE. Our empirical results show that our approach successfully infers event timings of time series data. Our method achieves competitive or superior performances compared to existing state-of-the-art methods for both synthetic and real-world datasets.
Attack on practical speaker verification system using universal adversarial perturbations
May 19, 2021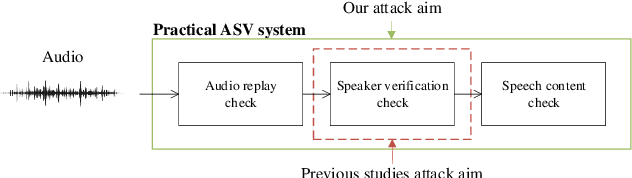
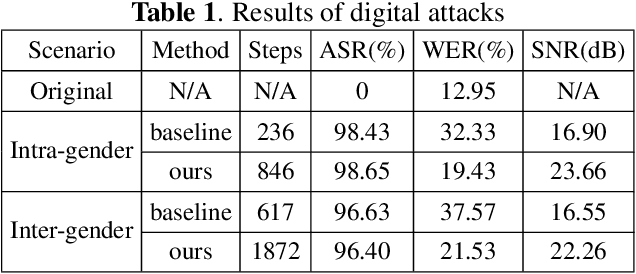
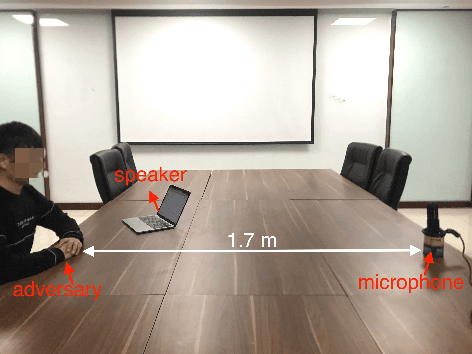
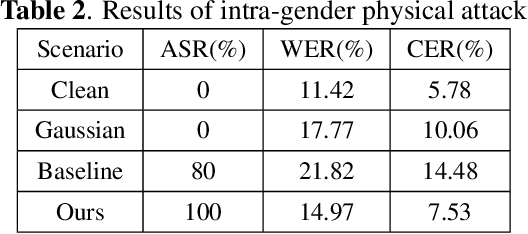
In authentication scenarios, applications of practical speaker verification systems usually require a person to read a dynamic authentication text. Previous studies played an audio adversarial example as a digital signal to perform physical attacks, which would be easily rejected by audio replay detection modules. This work shows that by playing our crafted adversarial perturbation as a separate source when the adversary is speaking, the practical speaker verification system will misjudge the adversary as a target speaker. A two-step algorithm is proposed to optimize the universal adversarial perturbation to be text-independent and has little effect on the authentication text recognition. We also estimated room impulse response (RIR) in the algorithm which allowed the perturbation to be effective after being played over the air. In the physical experiment, we achieved targeted attacks with success rate of 100%, while the word error rate (WER) on speech recognition was only increased by 3.55%. And recorded audios could pass replay detection for the live person speaking.