 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn automatic counting algorithm for the quantification and uncertainty analysis of the number of microglial cells trainable in small and heterogeneous datasets
Feb 26, 2026Counting immunopositive cells on biological tissues generally requires either manual annotation or (when available) automatic rough systems, for scanning signal surface and intensity in whole slide imaging. In this work, we tackle the problem of counting microglial cells in lumbar spinal cord cross-sections of rats by omitting cell detection and focusing only on the counting task. Manual cell counting is, however, a time-consuming task and additionally entails extensive personnel training. The classic automatic color-based methods roughly inform about the total labeled area and intensity (protein quantification) but do not specifically provide information on cell number. Since the images to be analyzed have a high resolution but a huge amount of pixels contain just noise or artifacts, we first perform a pre-processing generating several filtered images {(providing a tailored, efficient feature extraction)}. Then, we design an automatic kernel counter that is a non-parametric and non-linear method. The proposed scheme can be easily trained in small datasets since, in its basic version, it relies only on one hyper-parameter. However, being non-parametric and non-linear, the proposed algorithm is flexible enough to express all the information contained in rich and heterogeneous datasets as well (providing the maximum overfit if required). Furthermore, the proposed kernel counter also provides uncertainty estimation of the given prediction, and can directly tackle the case of receiving several expert opinions over the same image. Different numerical experiments with artificial and real datasets show very promising results. Related Matlab code is also provided.
A note on the area under the likelihood and the fake evidence for model selection
Feb 26, 2026Improper priors are not allowed for the computation of the Bayesian evidence $Z=p({\bf y})$ (a.k.a., marginal likelihood), since in this case $Z$ is not completely specified due to an arbitrary constant involved in the computation. However, in this work, we remark that they can be employed in a specific type of model selection problem: when we have several (possibly infinite) models belonging to the same parametric family (i.e., for tuning parameters of a parametric model). However, the quantities involved in this type of selection cannot be considered as Bayesian evidences: we suggest to use the name ``fake evidences'' (or ``areas under the likelihood'' in the case of uniform improper priors). We also show that, in this model selection scenario, using a diffuse prior and increasing its scale parameter asymptotically to infinity, we cannot recover the value of the area under the likelihood, obtained with a uniform improper prior. We first discuss it from a general point of view. Then we provide, as an applicative example, all the details for Bayesian regression models with nonlinear bases, considering two cases: the use of a uniform improper prior and the use of a Gaussian prior, respectively. A numerical experiment is also provided confirming and checking all the previous statements.
Effective sample size approximations as entropy measures
Feb 26, 2026In this work, we analyze alternative effective sample size (ESS) metrics for importance sampling algorithms, and discuss a possible extended range of applications. We show the relationship between the ESS expressions used in the literature and two entropy families, the Rényi and Tsallis entropy. The Rényi entropy is connected to the Huggins-Roy's ESS family introduced in \cite{Huggins15}. We prove that that all the ESS functions included in the Huggins-Roy's family fulfill all the desirable theoretical conditions. We analyzed and remark the connections with several other fields, such as the Hill numbers introduced in ecology, the Gini inequality coefficient employed in economics, and the Gini impurity index used mainly in machine learning, to name a few. Finally, by numerical simulations, we study the performance of different ESS expressions contained in the previous ESS families in terms of approximation of the theoretical ESS definition, and show the application of ESS formulas in a variable selection problem.
Adaptive posterior distributions for uncertainty analysis of covariance matrices in Bayesian inversion problems for multioutput signals
Jan 02, 2025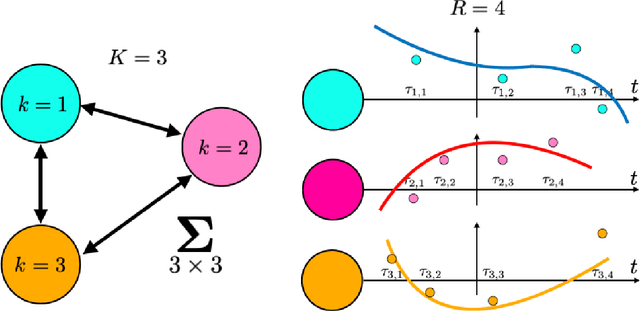

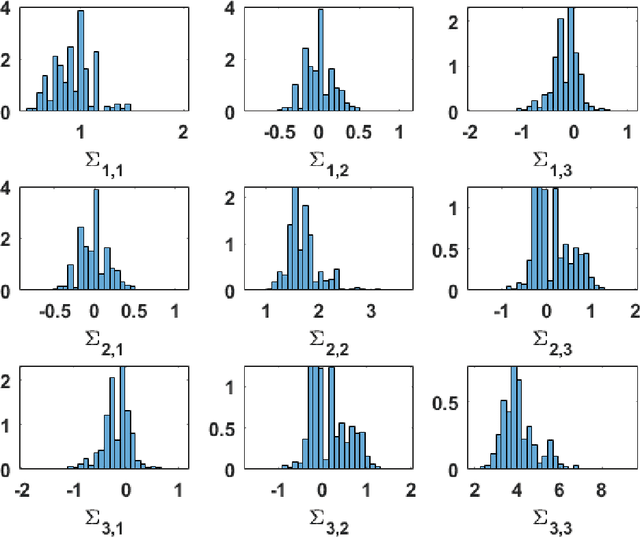
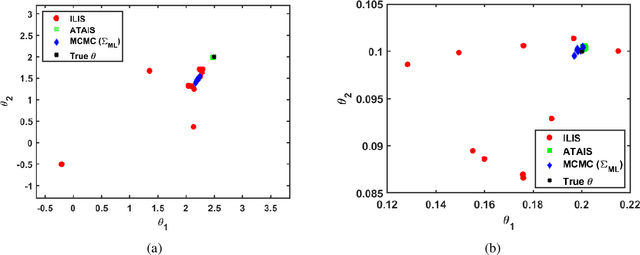
In this paper we address the problem of performing Bayesian inference for the parameters of a nonlinear multi-output model and the covariance matrix of the different output signals. We propose an adaptive importance sampling (AIS) scheme for multivariate Bayesian inversion problems, which is based in two main ideas: the variables of interest are split in two blocks and the inference takes advantage of known analytical optimization formulas. We estimate both the unknown parameters of the multivariate non-linear model and the covariance matrix of the noise. In the first part of the proposed inference scheme, a novel AIS technique called adaptive target adaptive importance sampling (ATAIS) is designed, which alternates iteratively between an IS technique over the parameters of the non-linear model and a frequentist approach for the covariance matrix of the noise. In the second part of the proposed inference scheme, a prior density over the covariance matrix is considered and the cloud of samples obtained by ATAIS are recycled and re-weighted to obtain a complete Bayesian study over the model parameters and covariance matrix. ATAIS is the main contribution of the work. Additionally, the inverted layered importance sampling (ILIS) is presented as a possible compelling algorithm (but based on a conceptually simpler idea). Different numerical examples show the benefits of the proposed approaches
Spectral information criterion for automatic elbow detection
Aug 17, 2023



We introduce a generalized information criterion that contains other well-known information criteria, such as Bayesian information Criterion (BIC) and Akaike information criterion (AIC), as special cases. Furthermore, the proposed spectral information criterion (SIC) is also more general than the other information criteria, e.g., since the knowledge of a likelihood function is not strictly required. SIC extracts geometric features of the error curve and, as a consequence, it can be considered an automatic elbow detector. SIC provides a subset of all possible models, with a cardinality that often is much smaller than the total number of possible models. The elements of this subset are elbows of the error curve. A practical rule for selecting a unique model within the sets of elbows is suggested as well. Theoretical invariance properties of SIC are analyzed. Moreover, we test SIC in ideal scenarios where provides always the optimal expected results. We also test SIC in several numerical experiments: some involving synthetic data, and two experiments involving real datasets. They are all real-world applications such as clustering, variable selection, or polynomial order selection, to name a few. The results show the benefits of the proposed scheme. Matlab code related to the experiments is also provided. Possible future research lines are finally discussed.
Universal and Automatic Elbow Detection for Learning the Effective Number of Components in Model Selection Problems
Aug 17, 2023We design a Universal Automatic Elbow Detector (UAED) for deciding the effective number of components in model selection problems. The relationship with the information criteria widely employed in the literature is also discussed. The proposed UAED does not require the knowledge of a likelihood function and can be easily applied in diverse applications, such as regression and classification, feature and/or order selection, clustering, and dimension reduction. Several experiments involving synthetic and real data show the advantages of the proposed scheme with benchmark techniques in the literature.
An exhaustive variable selection study for linear models of soundscape emotions: rankings and Gibbs analysis
Jul 26, 2022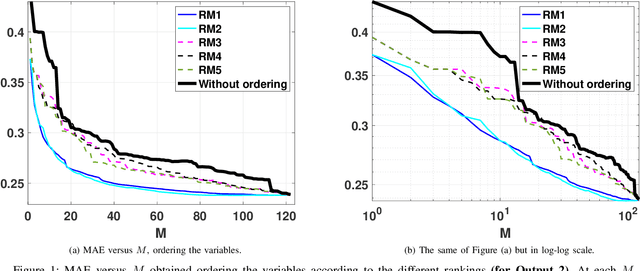
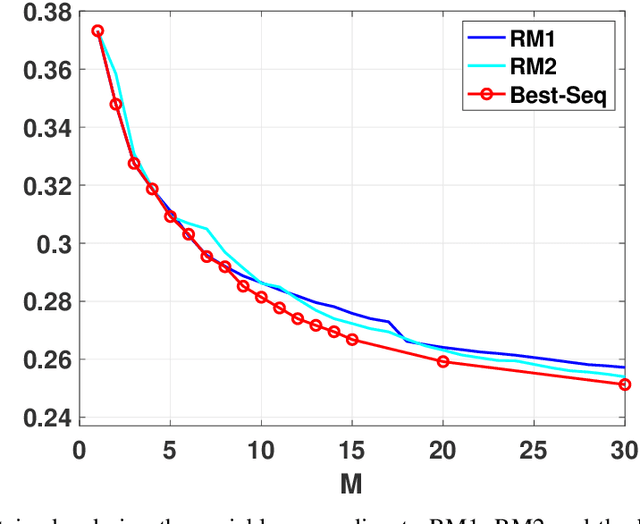
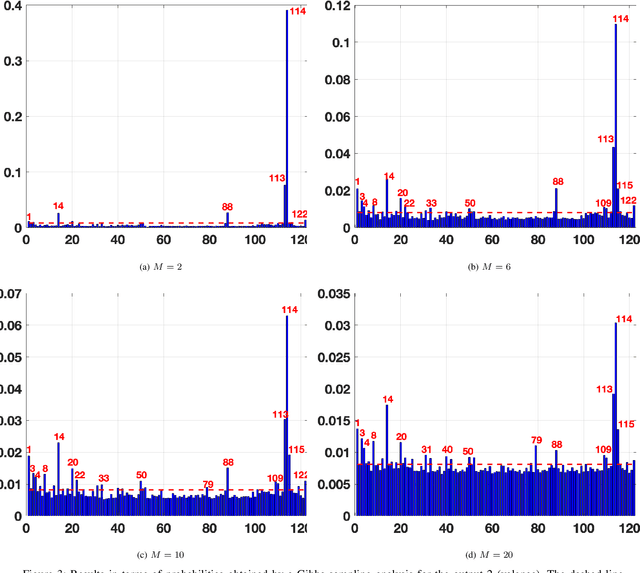

In the last decade, soundscapes have become one of the most active topics in Acoustics, providing a holistic approach to the acoustic environment, which involves human perception and context. Soundscapes-elicited emotions are central and substantially subtle and unnoticed (compared to speech or music). Currently, soundscape emotion recognition is a very active topic in the literature. We provide an exhaustive variable selection study (i.e., a selection of the soundscapes indicators) to a well-known dataset (emo-soundscapes). We consider linear soundscape emotion models for two soundscapes descriptors: arousal and valence. Several ranking schemes and procedures for selecting the number of variables are applied. We have also performed an alternating optimization scheme for obtaining the best sequences keeping fixed a certain number of features. Furthermore, we have designed a novel technique based on Gibbs sampling, which provides a more complete and clear view of the relevance of each variable. Finally, we have also compared our results with the analysis obtained by the classical methods based on p-values. As a result of our study, we suggest two simple and parsimonious linear models of only 7 and 16 variables (within the 122 possible features) for the two outputs (arousal and valence), respectively. The suggested linear models provide very good and competitive performance, with $R^2>0.86$ and $R^2>0.63$ (values obtained after a cross-validation procedure), respectively.
* published in IEEE-ACM Transactions on Audio, Speech and Language Processing
On the safe use of prior densities for Bayesian model selection
Jun 10, 2022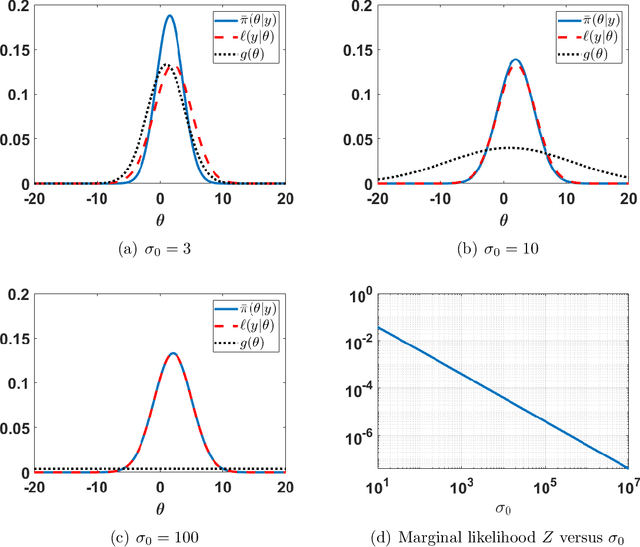


The application of Bayesian inference for the purpose of model selection is very popular nowadays. In this framework, models are compared through their marginal likelihoods, or their quotients, called Bayes factors. However, marginal likelihoods depends on the prior choice. For model selection, even diffuse priors can be actually very informative, unlike for the parameter estimation problem. Furthermore, when the prior is improper, the marginal likelihood of the corresponding model is undetermined. In this work, we discuss the issue of prior sensitivity of the marginal likelihood and its role in model selection. We also comment on the use of uninformative priors, which are very common choices in practice. Several practical suggestions are discussed and many possible solutions, proposed in the literature, to design objective priors for model selection are described. Some of them also allow the use of improper priors. The connection between the marginal likelihood approach and the well-known information criteria is also presented. We describe the main issues and possible solutions by illustrative numerical examples, providing also some related code. One of them involving a real-world application on exoplanet detection.
A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning
Aug 01, 2021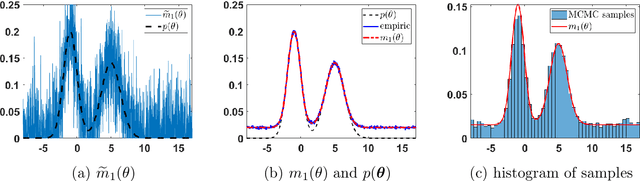
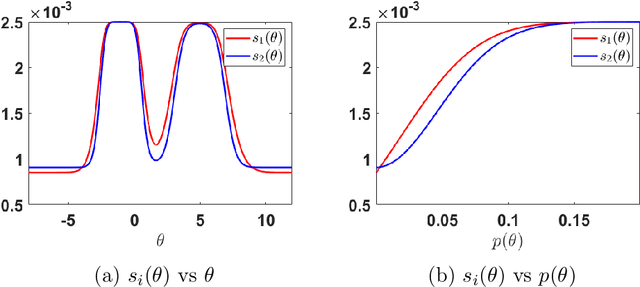
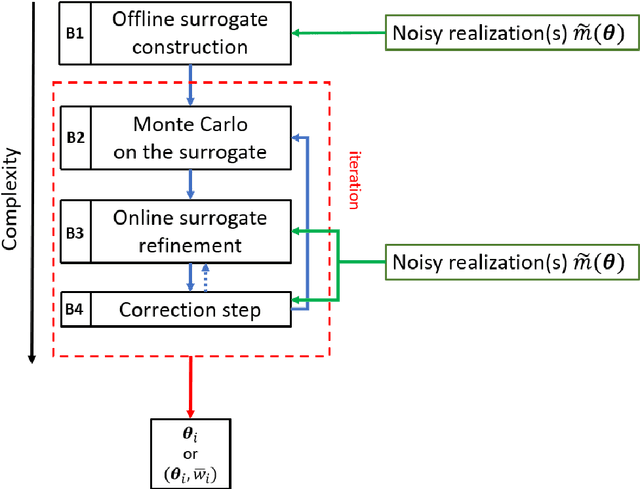

This survey gives an overview of Monte Carlo methodologies using surrogate models, for dealing with densities which are intractable, costly, and/or noisy. This type of problem can be found in numerous real-world scenarios, including stochastic optimization and reinforcement learning, where each evaluation of a density function may incur some computationally-expensive or even physical (real-world activity) cost, likely to give different results each time. The surrogate model does not incur this cost, but there are important trade-offs and considerations involved in the choice and design of such methodologies. We classify the different methodologies into three main classes and describe specific instances of algorithms under a unified notation. A modular scheme which encompasses the considered methods is also presented. A range of application scenarios is discussed, with special attention to the likelihood-free setting and reinforcement learning. Several numerical comparisons are also provided.
A Survey of Monte Carlo Methods for Parameter Estimation
Jul 25, 2021
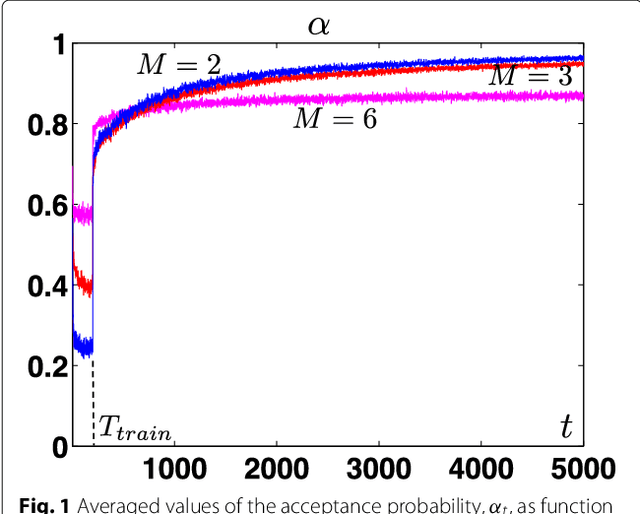
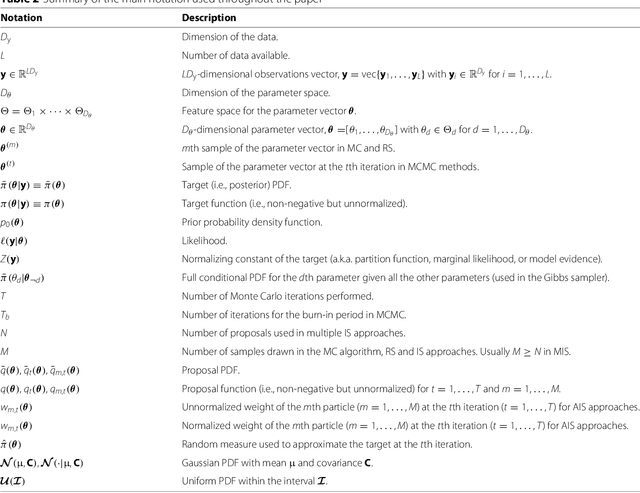
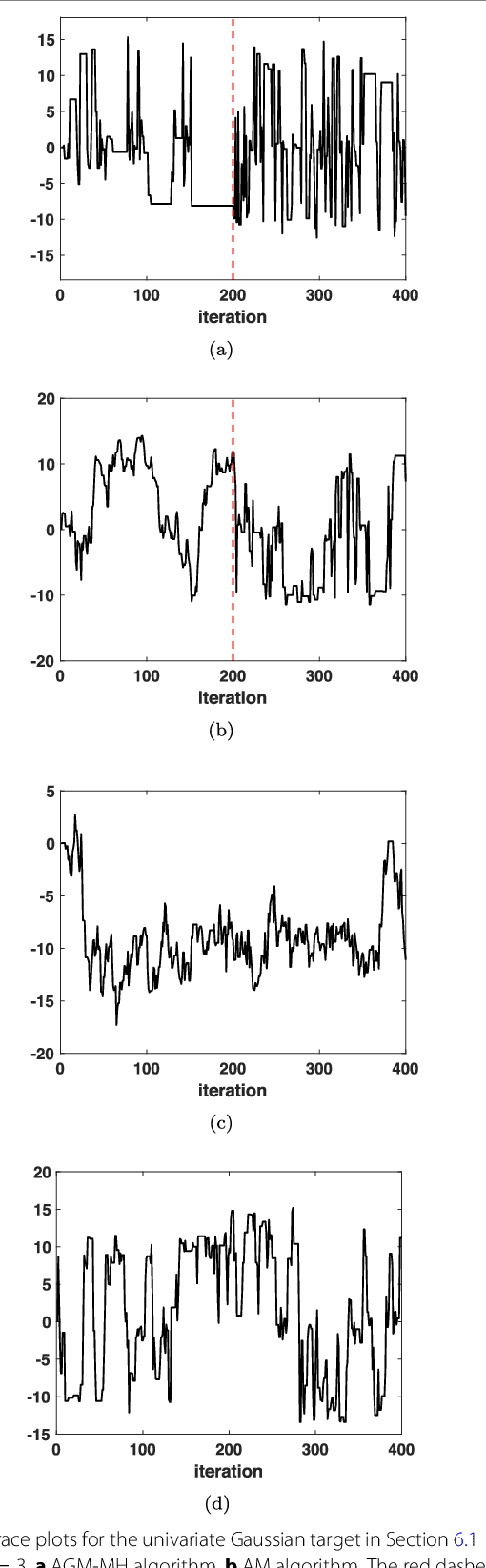
Statistical signal processing applications usually require the estimation of some parameters of interest given a set of observed data. These estimates are typically obtained either by solving a multi-variate optimization problem, as in the maximum likelihood (ML) or maximum a posteriori (MAP) estimators, or by performing a multi-dimensional integration, as in the minimum mean squared error (MMSE) estimators. Unfortunately, analytical expressions for these estimators cannot be found in most real-world applications, and the Monte Carlo (MC) methodology is one feasible approach. MC methods proceed by drawing random samples, either from the desired distribution or from a simpler one, and using them to compute consistent estimators. The most important families of MC algorithms are Markov chain MC (MCMC) and importance sampling (IS). On the one hand, MCMC methods draw samples from a proposal density, building then an ergodic Markov chain whose stationary distribution is the desired distribution by accepting or rejecting those candidate samples as the new state of the chain. On the other hand, IS techniques draw samples from a simple proposal density, and then assign them suitable weights that measure their quality in some appropriate way. In this paper, we perform a thorough review of MC methods for the estimation of static parameters in signal processing applications. A historical note on the development of MC schemes is also provided, followed by the basic MC method and a brief description of the rejection sampling (RS) algorithm, as well as three sections describing many of the most relevant MCMC and IS algorithms, and their combined use.