 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction of a Large-scale Japanese ASR Corpus on TV Recordings
Mar 26, 2021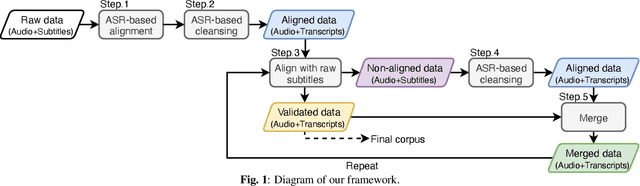
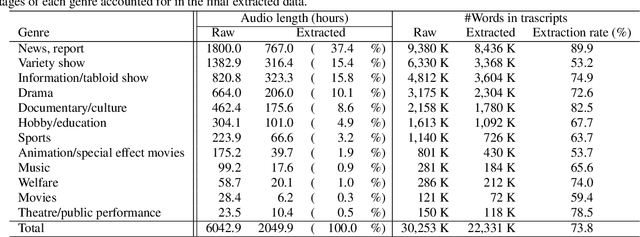
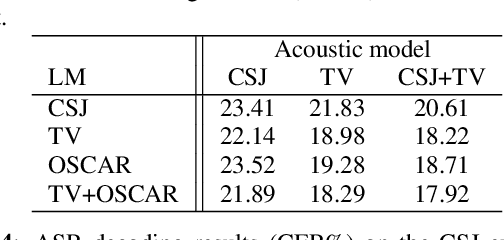
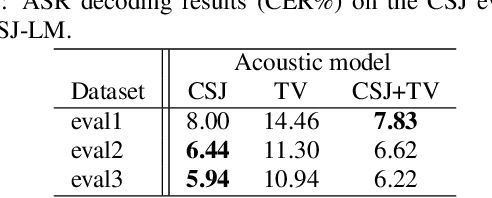
This paper presents a new large-scale Japanese speech corpus for training automatic speech recognition (ASR) systems. This corpus contains over 2,000 hours of speech with transcripts built on Japanese TV recordings and their subtitles. We develop herein an iterative workflow to extract matching audio and subtitle segments from TV recordings based on a conventional method for lightly-supervised audio-to-text alignment. We evaluate a model trained with our corpus using an evaluation dataset built on Japanese TEDx presentation videos and confirm that the performance is better than that trained with the Corpus of Spontaneous Japanese (CSJ). The experiment results show the usefulness of our corpus for training ASR systems. This corpus is made public for the research community along with Kaldi scripts for training the models reported in this paper.
Revisiting a single-stage method for face detection
Feb 05, 2019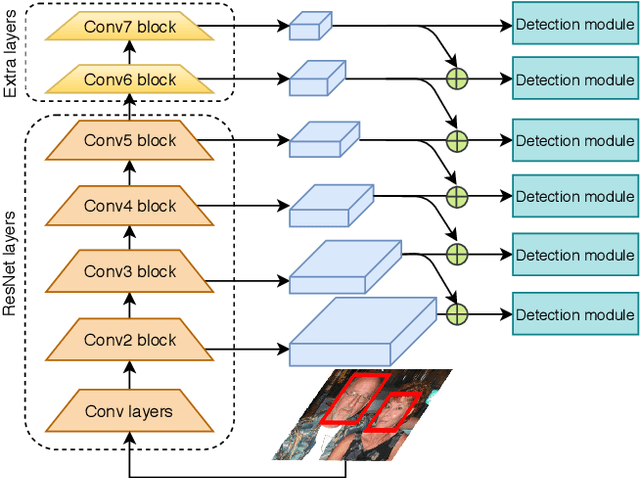


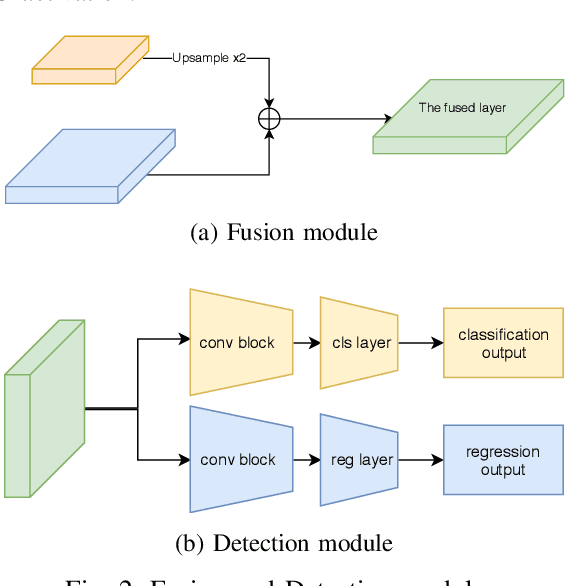
Although accurate, two-stage face detectors usually require more inference time than single-stage detectors do. This paper proposes a simple yet effective single-stage model for real-time face detection with a prominently high accuracy. We build our single-stage model on the top of the ResNet-101 backbone and analyze some problems with the baseline single-stage detector in order to design several strategies for reducing the false positive rate. The design leverages the context information from the deeper layers in order to increase recall rate while maintaining a low false positive rate. In addition, we reduce the detection time by an improved inference procedure for decoding outputs faster. The inference time of a VGA ($640{\times}480$) image was only approximately 26 ms with a Titan X GPU. The effectiveness of our proposed method was evaluated on several face detection benchmarks (Wider Face, AFW, Pascal Face, and FDDB). The experiments show that our method achieved competitive results on these popular datasets with a faster runtime than the current best two-stage practices.