 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
"Notic My Speech" -- Blending Speech Patterns With Multimedia
Jun 12, 2020
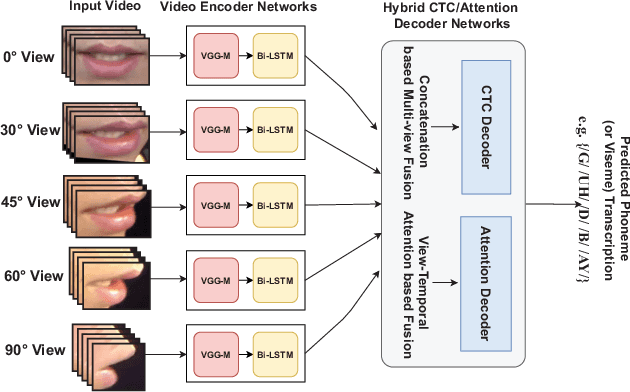
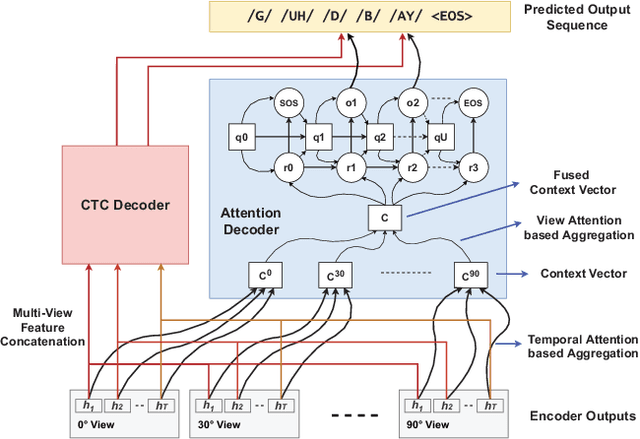
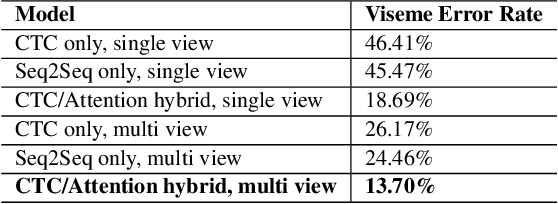
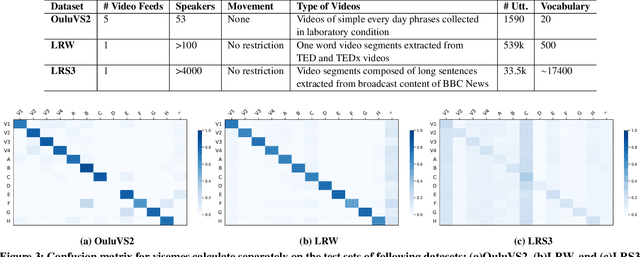
Speech as a natural signal is composed of three parts - visemes (visual part of speech), phonemes (spoken part of speech), and language (the imposed structure). However, video as a medium for the delivery of speech and a multimedia construct has mostly ignored the cognitive aspects of speech delivery. For example, video applications like transcoding and compression have till now ignored the fact how speech is delivered and heard. To close the gap between speech understanding and multimedia video applications, in this paper, we show the initial experiments by modelling the perception on visual speech and showing its use case on video compression. On the other hand, in the visual speech recognition domain, existing studies have mostly modeled it as a classification problem, while ignoring the correlations between views, phonemes, visemes, and speech perception. This results in solutions which are further away from how human perception works. To bridge this gap, we propose a view-temporal attention mechanism to model both the view dependence and the visemic importance in speech recognition and understanding. We conduct experiments on three public visual speech recognition datasets. The experimental results show that our proposed method outperformed the existing work by 4.99% in terms of the viseme error rate. Moreover, we show that there is a strong correlation between our model's understanding of multi-view speech and the human perception. This characteristic benefits downstream applications such as video compression and streaming where a significant number of less important frames can be compressed or eliminated while being able to maximally preserve human speech understanding with good user experience.
TaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020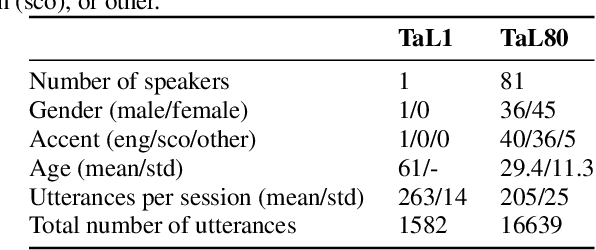
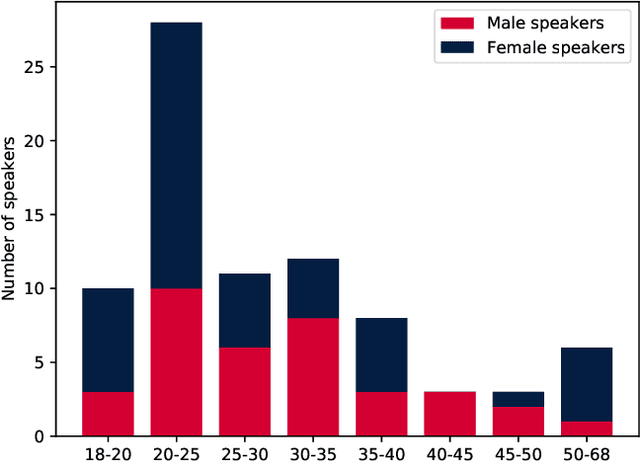
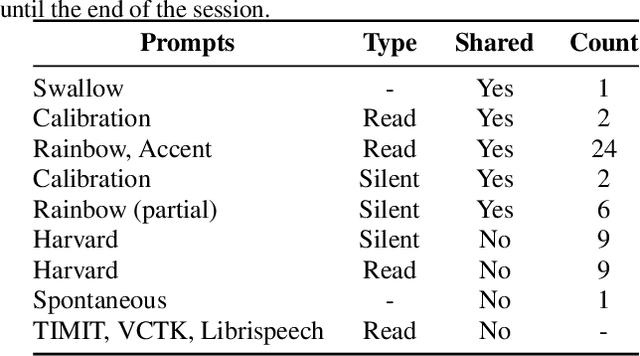

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.
Keyword Transformer: A Self-Attention Model for Keyword Spotting
Apr 15, 2021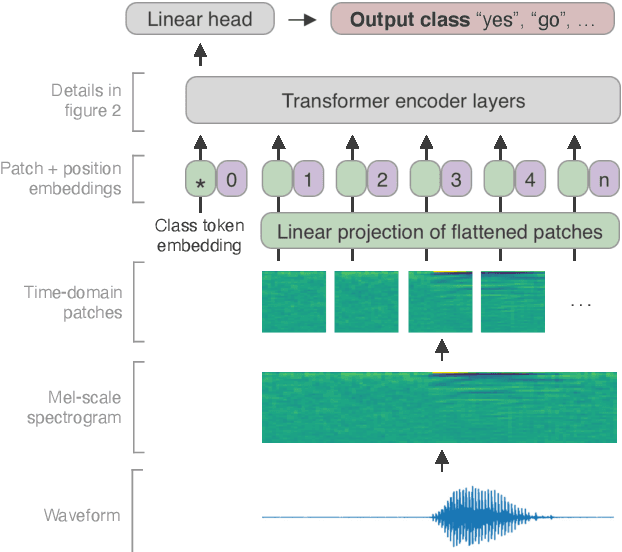

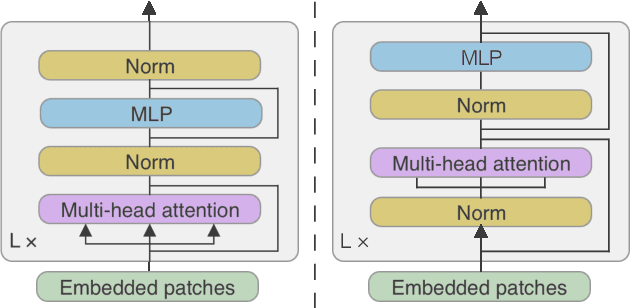

The Transformer architecture has been successful across many domains, including natural language processing, computer vision and speech recognition. In keyword spotting, self-attention has primarily been used on top of convolutional or recurrent encoders. We investigate a range of ways to adapt the Transformer architecture to keyword spotting and introduce the Keyword Transformer (KWT), a fully self-attentional architecture that exceeds state-of-the-art performance across multiple tasks without any pre-training or additional data. Surprisingly, this simple architecture outperforms more complex models that mix convolutional, recurrent and attentive layers. KWT can be used as a drop-in replacement for these models, setting two new benchmark records on the Google Speech Commands dataset with 98.6% and 97.7% accuracy on the 12 and 35-command tasks respectively.
Hierarchical Summarization for Longform Spoken Dialog
Aug 21, 2021
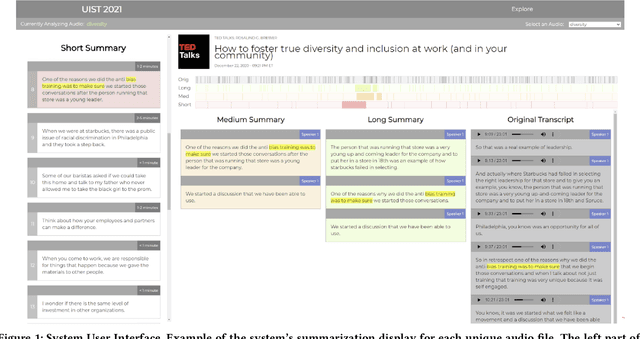

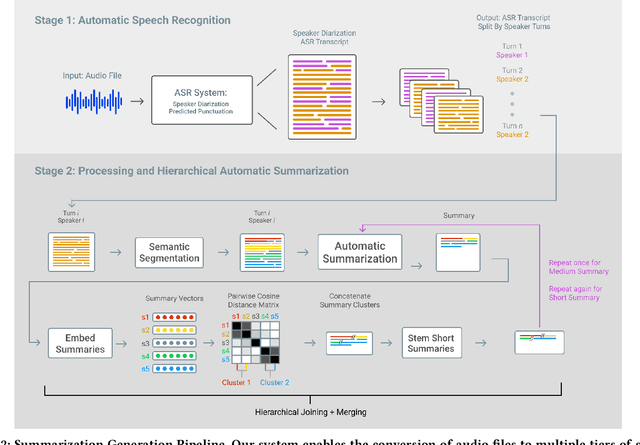
Every day we are surrounded by spoken dialog. This medium delivers rich diverse streams of information auditorily; however, systematically understanding dialog can often be non-trivial. Despite the pervasiveness of spoken dialog, automated speech understanding and quality information extraction remains markedly poor, especially when compared to written prose. Furthermore, compared to understanding text, auditory communication poses many additional challenges such as speaker disfluencies, informal prose styles, and lack of structure. These concerns all demonstrate the need for a distinctly speech tailored interactive system to help users understand and navigate the spoken language domain. While individual automatic speech recognition (ASR) and text summarization methods already exist, they are imperfect technologies; neither consider user purpose and intent nor address spoken language induced complications. Consequently, we design a two stage ASR and text summarization pipeline and propose a set of semantic segmentation and merging algorithms to resolve these speech modeling challenges. Our system enables users to easily browse and navigate content as well as recover from errors in these underlying technologies. Finally, we present an evaluation of the system which highlights user preference for hierarchical summarization as a tool to quickly skim audio and identify content of interest to the user.
Mixtures of Deep Neural Experts for Automated Speech Scoring
Jun 23, 2021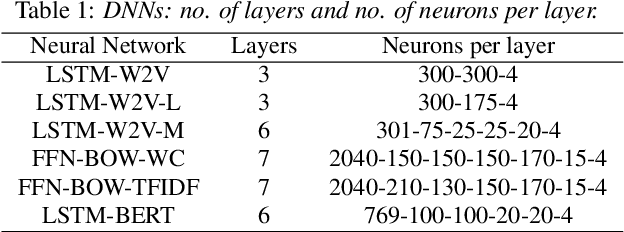
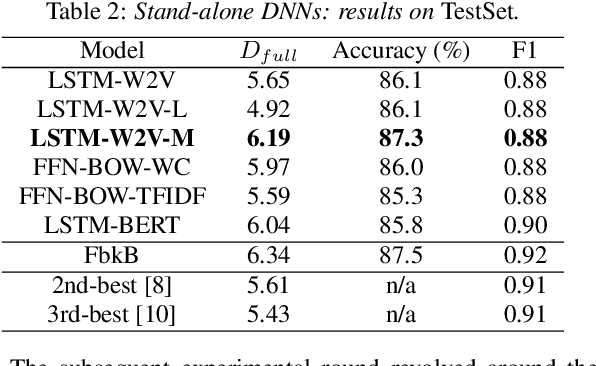
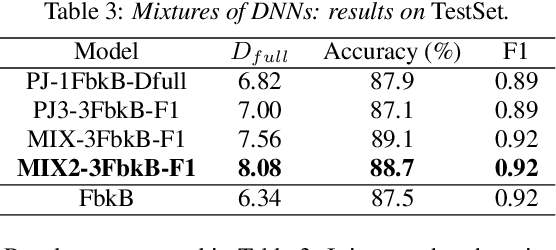
The paper copes with the task of automatic assessment of second language proficiency from the language learners' spoken responses to test prompts. The task has significant relevance to the field of computer assisted language learning. The approach presented in the paper relies on two separate modules: (1) an automatic speech recognition system that yields text transcripts of the spoken interactions involved, and (2) a multiple classifier system based on deep learners that ranks the transcripts into proficiency classes. Different deep neural network architectures (both feed-forward and recurrent) are specialized over diverse representations of the texts in terms of: a reference grammar, the outcome of probabilistic language models, several word embeddings, and two bag-of-word models. Combination of the individual classifiers is realized either via a probabilistic pseudo-joint model, or via a neural mixture of experts. Using the data of the third Spoken CALL Shared Task challenge, the highest values to date were obtained in terms of three popular evaluation metrics.
May I Ask Who's Calling? Named Entity Recognition on Call Center Transcripts for Privacy Law Compliance
Oct 29, 2020
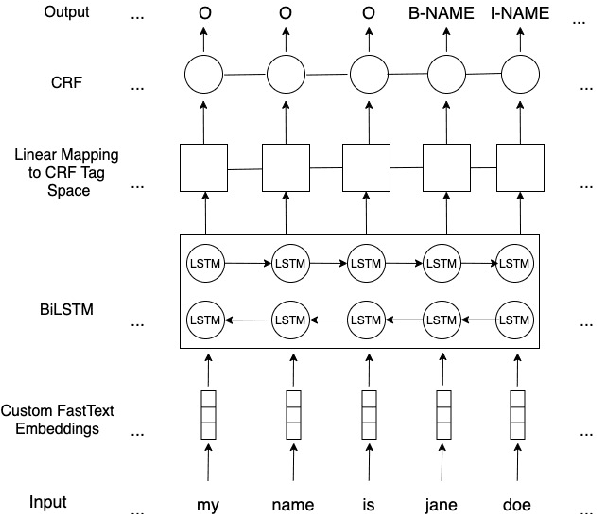
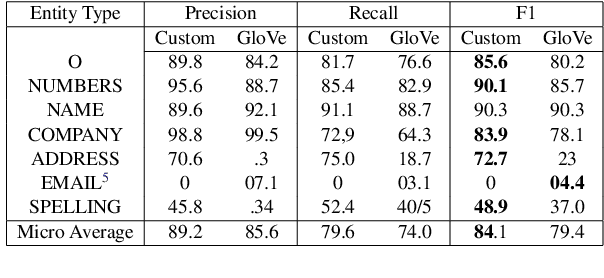
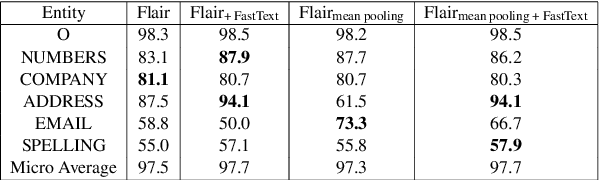
We investigate using Named Entity Recognition on a new type of user-generated text: a call center conversation. These conversations combine problems from spontaneous speech with problems novel to conversational Automated Speech Recognition, including incorrect recognition, alongside other common problems from noisy user-generated text. Using our own corpus with new annotations, training custom contextual string embeddings, and applying a BiLSTM-CRF, we match state-of-the-art results on our novel task.
* The 6th Workshop on Noisy User-generated Text (W-NUT) 2020 at EMNLP
Domain Adaptation Using Class Similarity for Robust Speech Recognition
Nov 05, 2020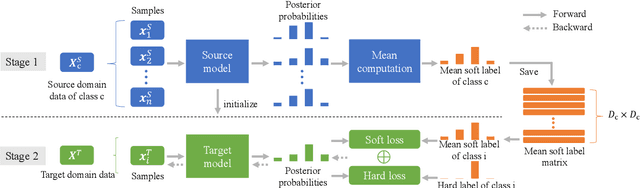
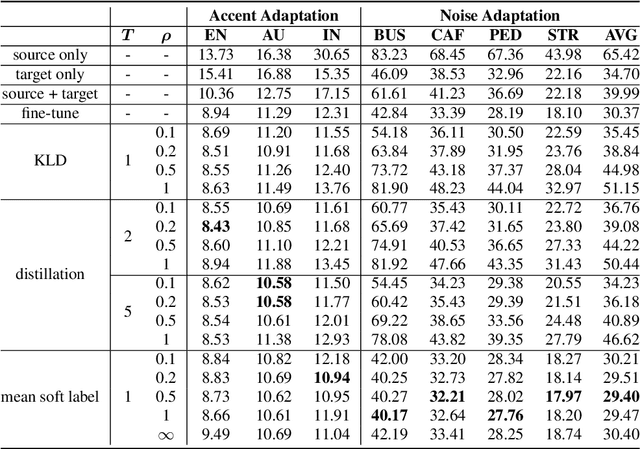
When only limited target domain data is available, domain adaptation could be used to promote performance of deep neural network (DNN) acoustic model by leveraging well-trained source model and target domain data. However, suffering from domain mismatch and data sparsity, domain adaptation is very challenging. This paper proposes a novel adaptation method for DNN acoustic model using class similarity. Since the output distribution of DNN model contains the knowledge of similarity among classes, which is applicable to both source and target domain, it could be transferred from source to target model for the performance improvement. In our approach, we first compute the frame level posterior probabilities of source samples using source model. Then, for each class, probabilities of this class are used to compute a mean vector, which we refer to as mean soft labels. During adaptation, these mean soft labels are used in a regularization term to train the target model. Experiments showed that our approach outperforms fine-tuning using one-hot labels on both accent and noise adaptation task, especially when source and target domain are highly mismatched.
Convolutional Neural Networks for Speech Controlled Prosthetic Hands
Oct 03, 2019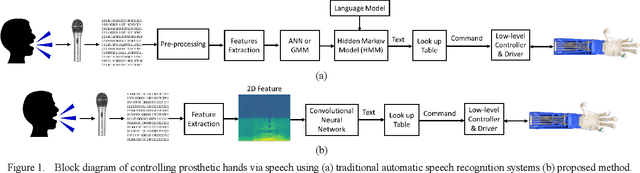
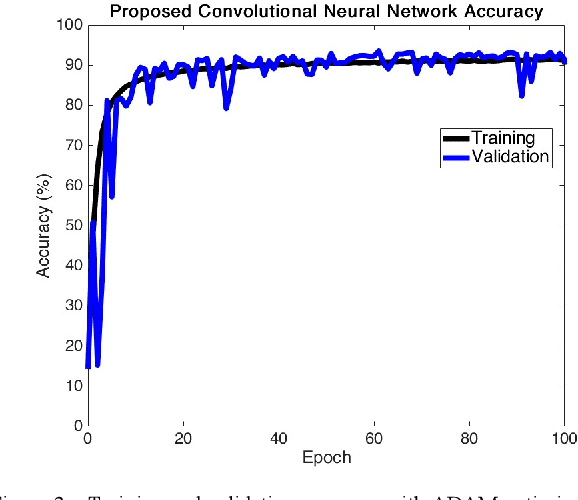
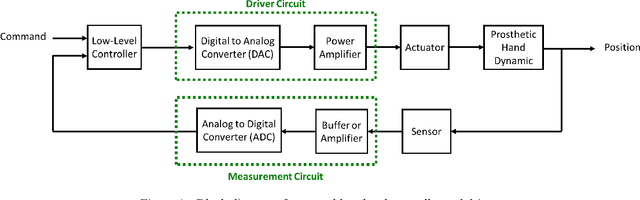
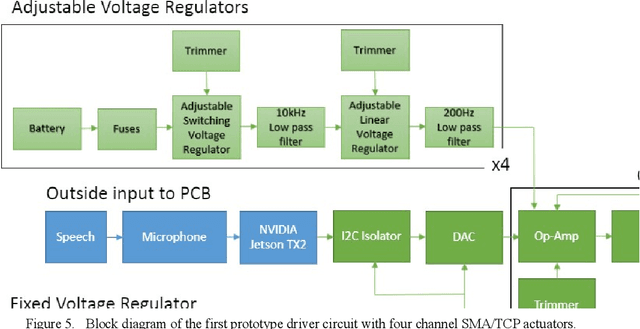
Speech recognition is one of the key topics in artificial intelligence, as it is one of the most common forms of communication in humans. Researchers have developed many speech-controlled prosthetic hands in the past decades, utilizing conventional speech recognition systems that use a combination of neural network and hidden Markov model. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, state-of-the-art speech recognition systems have rapidly shifted from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. However, a low-power embedded GPGPU cannot run these speech recognition systems in real-time. In this paper, we show the development of deep convolutional neural networks (CNN) for speech control of prosthetic hands that run in real-time on a NVIDIA Jetson TX2 developer kit. First, the device captures and converts speech into 2D features (like spectrogram). The CNN receives the 2D features and classifies the hand gestures. Finally, the hand gesture classes are sent to the prosthetic hand motion control system. The whole system is written in Python with Keras, a deep learning library that has a TensorFlow backend. Our experiments on the CNN demonstrate the 91% accuracy and 2ms running time of hand gestures (text output) from speech commands, which can be used to control the prosthetic hands in real-time.
* 2019 First International Conference on Transdisciplinary AI (TransAI), Laguna Hills, California, USA, 2019, pp. 35-42
Self-supervised Graphs for Audio Representation Learning with Limited Labeled Data
Jan 31, 2022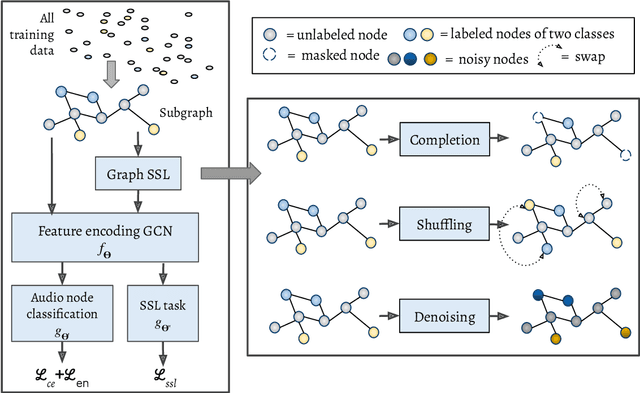
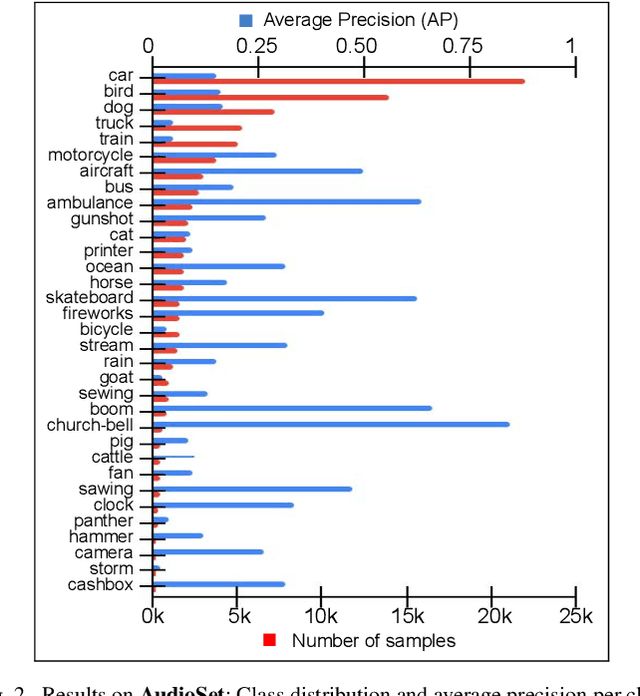
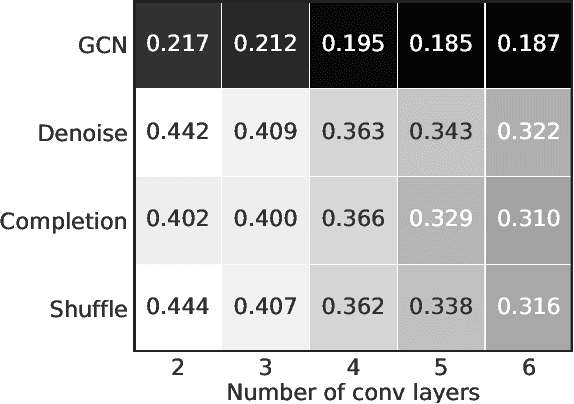
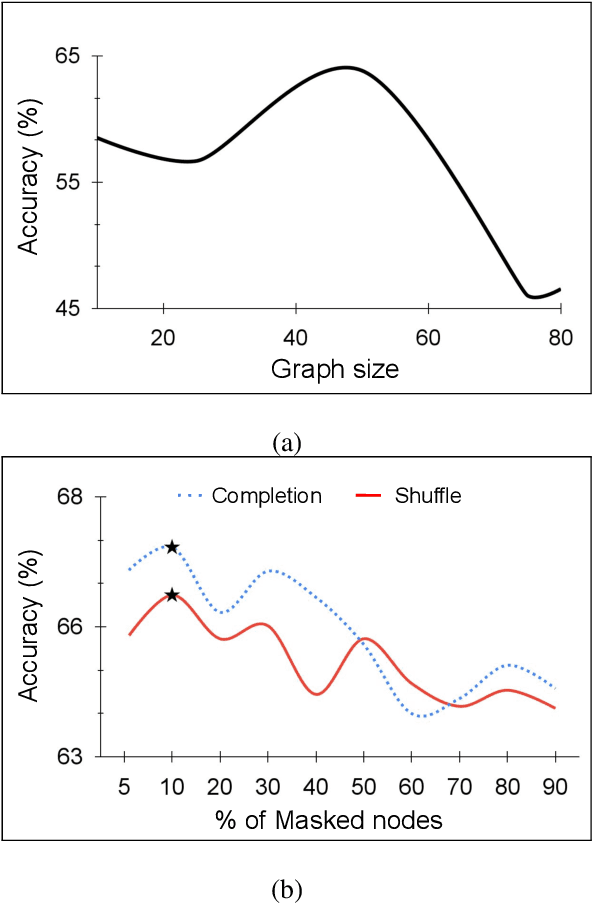
Large scale databases with high-quality manual annotations are scarce in audio domain. We thus explore a self-supervised graph approach to learning audio representations from highly limited labelled data. Considering each audio sample as a graph node, we propose a subgraph-based framework with novel self-supervision tasks that can learn effective audio representations. During training, subgraphs are constructed by sampling the entire pool of available training data to exploit the relationship between the labelled and unlabeled audio samples. During inference, we use random edges to alleviate the overhead of graph construction. We evaluate our model on three benchmark audio databases, and two tasks: acoustic event detection and speech emotion recognition. Our semi-supervised model performs better or on par with fully supervised models and outperforms several competitive existing models. Our model is compact (240k parameters), and can produce generalized audio representations that are robust to different types of signal noise.
MeshRIR: A Dataset of Room Impulse Responses on Meshed Grid Points For Evaluating Sound Field Analysis and Synthesis Methods
Jun 21, 2021
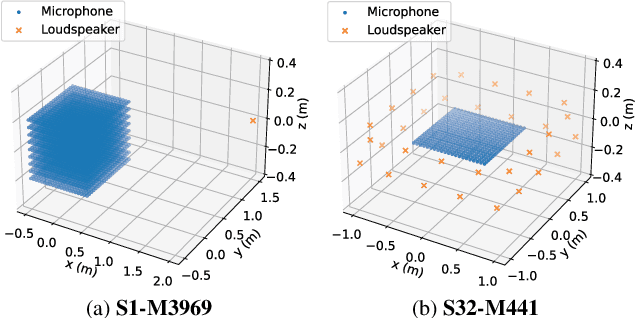
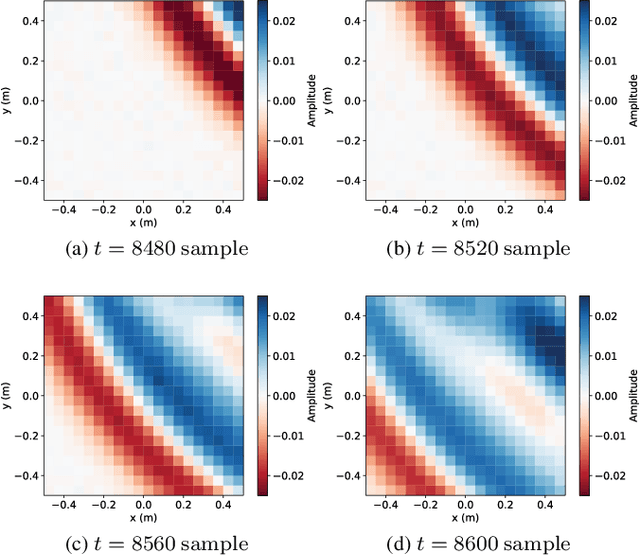
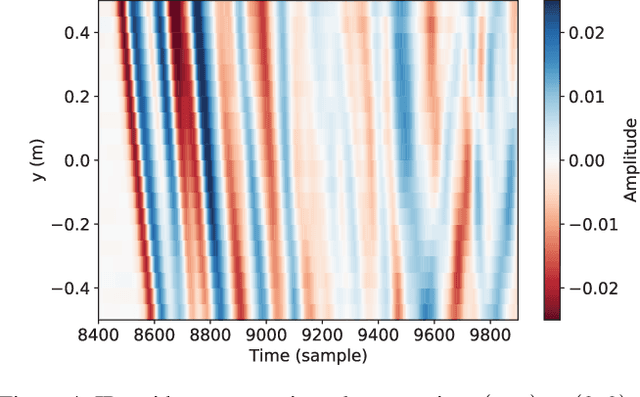
A new impulse response (IR) dataset called "MeshRIR" is introduced. Currently available datasets usually include IRs at an array of microphones from several source positions under various room conditions, which are basically designed for evaluating speech enhancement and distant speech recognition methods. On the other hand, methods of estimating or controlling spatial sound fields have been extensively investigated in recent years; however, the current IR datasets are not applicable to validating and comparing these methods because of the low spatial resolution of measurement points. MeshRIR consists of IRs measured at positions obtained by finely discretizing a spatial region. Two subdatasets are currently available: one consists of IRs in a three-dimensional cuboidal region from a single source, and the other consists of IRs in a two-dimensional square region from an array of 32 sources. Therefore, MeshRIR is suitable for evaluating sound field analysis and synthesis methods. This dataset is freely available at \url{https://sh01k.github.io/MeshRIR/} with some codes of sample applications.