 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
May 22, 2024



Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
LanSER: Language-Model Supported Speech Emotion Recognition
Sep 07, 2023



Speech emotion recognition (SER) models typically rely on costly human-labeled data for training, making scaling methods to large speech datasets and nuanced emotion taxonomies difficult. We present LanSER, a method that enables the use of unlabeled data by inferring weak emotion labels via pre-trained large language models through weakly-supervised learning. For inferring weak labels constrained to a taxonomy, we use a textual entailment approach that selects an emotion label with the highest entailment score for a speech transcript extracted via automatic speech recognition. Our experimental results show that models pre-trained on large datasets with this weak supervision outperform other baseline models on standard SER datasets when fine-tuned, and show improved label efficiency. Despite being pre-trained on labels derived only from text, we show that the resulting representations appear to model the prosodic content of speech.
* Presented at INTERSPEECH 2023
MM-AU:Towards Multimodal Understanding of Advertisement Videos
Aug 27, 2023Advertisement videos (ads) play an integral part in the domain of Internet e-commerce as they amplify the reach of particular products to a broad audience or can serve as a medium to raise awareness about specific issues through concise narrative structures. The narrative structures of advertisements involve several elements like reasoning about the broad content (topic and the underlying message) and examining fine-grained details involving the transition of perceived tone due to the specific sequence of events and interaction among characters. In this work, to facilitate the understanding of advertisements along the three important dimensions of topic categorization, perceived tone transition, and social message detection, we introduce a multimodal multilingual benchmark called MM-AU composed of over 8.4K videos (147 hours) curated from multiple web sources. We explore multiple zero-shot reasoning baselines through the application of large language models on the ads transcripts. Further, we demonstrate that leveraging signals from multiple modalities, including audio, video, and text, in multimodal transformer-based supervised models leads to improved performance compared to unimodal approaches.
Contextually-rich human affect perception using multimodal scene information
Mar 13, 2023



The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.
Heterogeneous Graph Learning for Acoustic Event Classification
Mar 12, 2023


Heterogeneous graphs provide a compact, efficient, and scalable way to model data involving multiple disparate modalities. This makes modeling audiovisual data using heterogeneous graphs an attractive option. However, graph structure does not appear naturally in audiovisual data. Graphs for audiovisual data are constructed manually which is both difficult and sub-optimal. In this work, we address this problem by (i) proposing a parametric graph construction strategy for the intra-modal edges, and (ii) learning the crossmodal edges. To this end, we develop a new model, heterogeneous graph crossmodal network (HGCN) that learns the crossmodal edges. Our proposed model can adapt to various spatial and temporal scales owing to its parametric construction, while the learnable crossmodal edges effectively connect the relevant nodes across modalities. Experiments on a large benchmark dataset (AudioSet) show that our model is state-of-the-art (0.53 mean average precision), outperforming transformer-based models and other graph-based models.
A dataset for Audio-Visual Sound Event Detection in Movies
Feb 14, 2023



Audio event detection is a widely studied audio processing task, with applications ranging from self-driving cars to healthcare. In-the-wild datasets such as Audioset have propelled research in this field. However, many efforts typically involve manual annotation and verification, which is expensive to perform at scale. Movies depict various real-life and fictional scenarios which makes them a rich resource for mining a wide-range of audio events. In this work, we present a dataset of audio events called Subtitle-Aligned Movie Sounds (SAM-S). We use publicly-available closed-caption transcripts to automatically mine over 110K audio events from 430 movies. We identify three dimensions to categorize audio events: sound, source, quality, and present the steps involved to produce a final taxonomy of 245 sounds. We discuss the choices involved in generating the taxonomy, and also highlight the human-centered nature of sounds in our dataset. We establish a baseline performance for audio-only sound classification of 34.76% mean average precision and show that incorporating visual information can further improve the performance by about 5%. Data and code are made available for research at https://github.com/usc-sail/mica-subtitle-aligned-movie-sounds
Visually-aware Acoustic Event Detection using Heterogeneous Graphs
Jul 16, 2022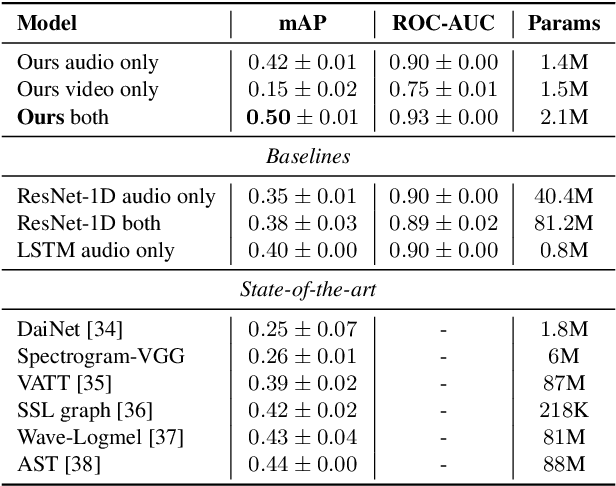

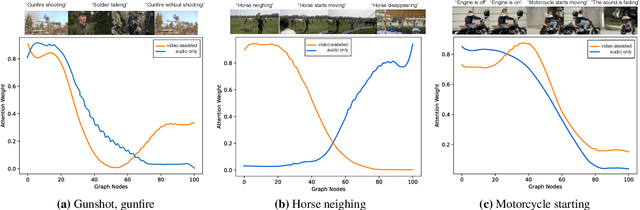
Perception of auditory events is inherently multimodal relying on both audio and visual cues. A large number of existing multimodal approaches process each modality using modality-specific models and then fuse the embeddings to encode the joint information. In contrast, we employ heterogeneous graphs to explicitly capture the spatial and temporal relationships between the modalities and represent detailed information about the underlying signal. Using heterogeneous graph approaches to address the task of visually-aware acoustic event classification, which serves as a compact, efficient and scalable way to represent data in the form of graphs. Through heterogeneous graphs, we show efficiently modelling of intra- and inter-modality relationships both at spatial and temporal scales. Our model can easily be adapted to different scales of events through relevant hyperparameters. Experiments on AudioSet, a large benchmark, shows that our model achieves state-of-the-art performance.
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022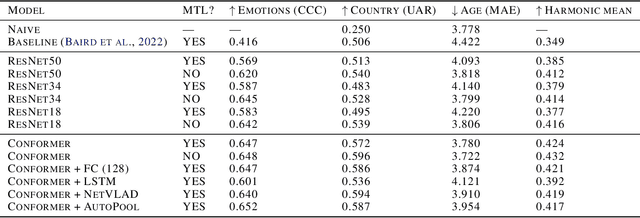
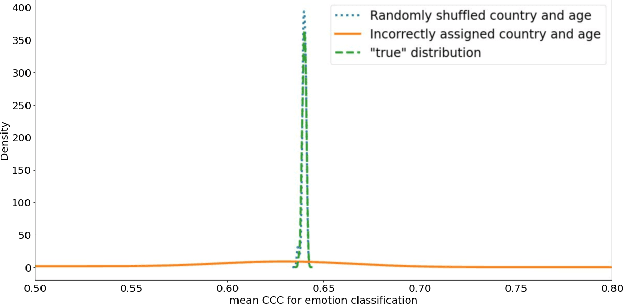
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
To train or not to train adversarially: A study of bias mitigation strategies for speaker recognition
Mar 17, 2022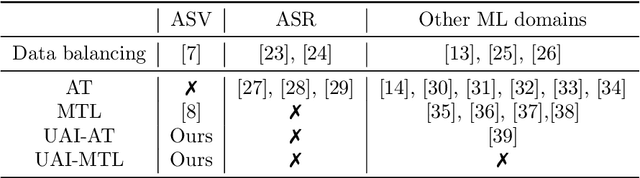
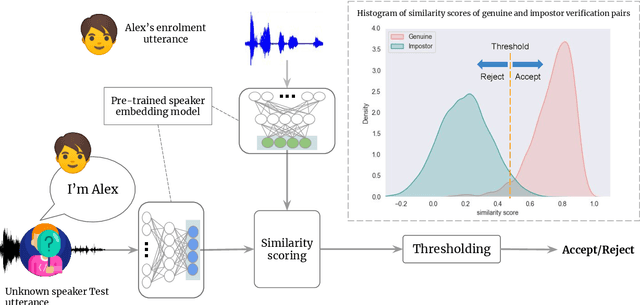
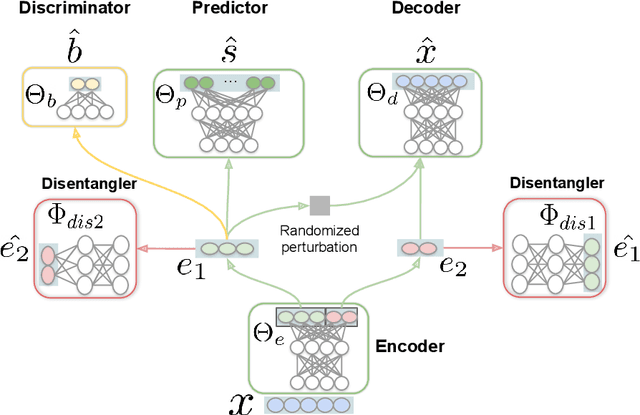
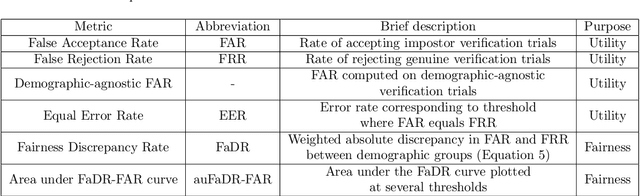
Speaker recognition is increasingly used in several everyday applications including smart speakers, customer care centers and other speech-driven analytics. It is crucial to accurately evaluate and mitigate biases present in machine learning (ML) based speech technologies, such as speaker recognition, to ensure their inclusive adoption. ML fairness studies with respect to various demographic factors in modern speaker recognition systems are lagging compared to other human-centered applications such as face recognition. Existing studies on fairness in speaker recognition systems are largely limited to evaluating biases at specific operating points of the systems, which can lead to false expectations of fairness. Moreover, there are only a handful of bias mitigation strategies developed for speaker recognition systems. In this paper, we systematically evaluate the biases present in speaker recognition systems with respect to gender across a range of system operating points. We also propose adversarial and multi-task learning techniques to improve the fairness of these systems. We show through quantitative and qualitative evaluations that the proposed methods improve the fairness of ASV systems over baseline methods trained using data balancing techniques. We also present a fairness-utility trade-off analysis to jointly examine fairness and the overall system performance. We show that although systems trained using adversarial techniques improve fairness, they are prone to reduced utility. On the other hand, multi-task methods can improve the fairness while retaining the utility. These findings can inform the choice of bias mitigation strategies in the field of speaker recognition.