 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmploying Discrete Fourier Transform in Representational Learning
Jun 07, 2025



Image Representation learning via input reconstruction is a common technique in machine learning for generating representations that can be effectively utilized by arbitrary downstream tasks. A well-established approach is using autoencoders to extract latent representations at the network's compression point. These representations are valuable because they retain essential information necessary for reconstructing the original input from the compressed latent space. In this paper, we propose an alternative learning objective. Instead of using the raw input as the reconstruction target, we employ the Discrete Fourier Transform (DFT) of the input. The DFT provides meaningful global information at each frequency level, making individual frequency components useful as separate learning targets. When dealing with multidimensional input data, the DFT offers remarkable flexibility by enabling selective transformation across specific dimensions while preserving others in the computation. Moreover, certain types of input exhibit distinct patterns in their frequency distributions, where specific frequency components consistently contain most of the magnitude, allowing us to focus on a subset of frequencies rather than the entire spectrum. These characteristics position the DFT as a viable learning objective for representation learning and we validate our approach by achieving 52.8% top-1 accuracy on CIFAR-10 with ResNet-50 and outperforming the traditional autoencoder by 12.8 points under identical architectural configurations. Additionally, we demonstrate that training on only the lower-frequency components - those with the highest magnitudes yields results comparable to using the full frequency spectrum, with only minimal reductions in accuracy.
Mixtures of Deep Neural Experts for Automated Speech Scoring
Jun 23, 2021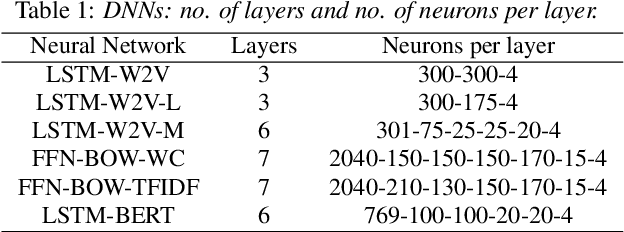
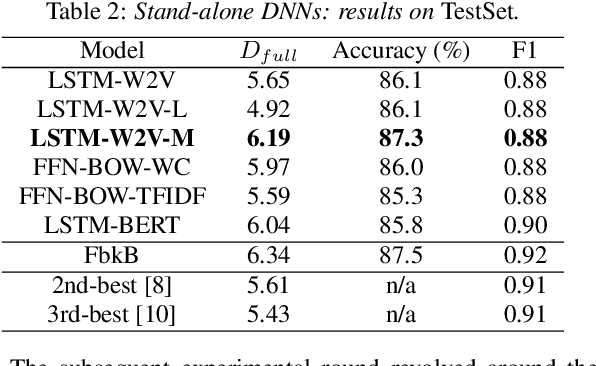
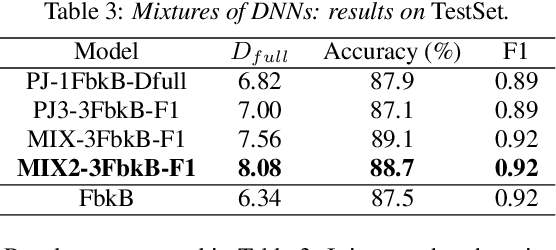
The paper copes with the task of automatic assessment of second language proficiency from the language learners' spoken responses to test prompts. The task has significant relevance to the field of computer assisted language learning. The approach presented in the paper relies on two separate modules: (1) an automatic speech recognition system that yields text transcripts of the spoken interactions involved, and (2) a multiple classifier system based on deep learners that ranks the transcripts into proficiency classes. Different deep neural network architectures (both feed-forward and recurrent) are specialized over diverse representations of the texts in terms of: a reference grammar, the outcome of probabilistic language models, several word embeddings, and two bag-of-word models. Combination of the individual classifiers is realized either via a probabilistic pseudo-joint model, or via a neural mixture of experts. Using the data of the third Spoken CALL Shared Task challenge, the highest values to date were obtained in terms of three popular evaluation metrics.
Multivariate Density Estimation with Deep Neural Mixture Models
Dec 06, 2020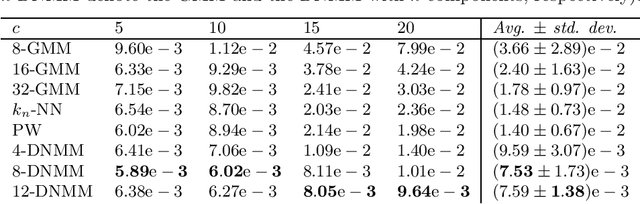

Albeit worryingly underrated in the recent literature on machine learning in general (and, on deep learning in particular), multivariate density estimation is a fundamental task in many applications, at least implicitly, and still an open issue. With a few exceptions, deep neural networks (DNNs) have seldom been applied to density estimation, mostly due to the unsupervised nature of the estimation task, and (especially) due to the need for constrained training algorithms that ended up realizing proper probabilistic models that satisfy Kolmogorov's axioms. Moreover, in spite of the well-known improvement in terms of modeling capabilities yielded by mixture models over plain single-density statistical estimators, no proper mixtures of multivariate DNN-based component densities have been investigated so far. The paper fills this gap by extending our previous work on Neural Mixture Densities (NMMs) to multivariate DNN mixtures. A maximum-likelihood (ML) algorithm for estimating Deep NMMs (DNMMs) is handed out, which satisfies numerically a combination of hard and soft constraints aimed at ensuring satisfaction of Kolmogorov's axioms. The class of probability density functions that can be modeled to any degree of precision via DNMMs is formally defined. A procedure for the automatic selection of the DNMM architecture, as well as of the hyperparameters for its ML training algorithm, is presented (exploiting the probabilistic nature of the DNMM). Experimental results on univariate and multivariate data are reported on, corroborating the effectiveness of the approach and its superiority to the most popular statistical estimation techniques.