 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Personalized Speech Enhancement: New Models and Comprehensive Evaluation
Oct 18, 2021
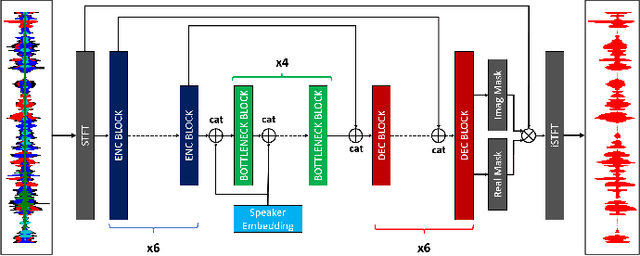


Personalized speech enhancement (PSE) models utilize additional cues, such as speaker embeddings like d-vectors, to remove background noise and interfering speech in real-time and thus improve the speech quality of online video conferencing systems for various acoustic scenarios. In this work, we propose two neural networks for PSE that achieve superior performance to the previously proposed VoiceFilter. In addition, we create test sets that capture a variety of scenarios that users can encounter during video conferencing. Furthermore, we propose a new metric to measure the target speaker over-suppression (TSOS) problem, which was not sufficiently investigated before despite its critical importance in deployment. Besides, we propose multi-task training with a speech recognition back-end. Our results show that the proposed models can yield better speech recognition accuracy, speech intelligibility, and perceptual quality than the baseline models, and the multi-task training can alleviate the TSOS issue in addition to improving the speech recognition accuracy.
Towards Online End-to-end Transformer Automatic Speech Recognition
Oct 25, 2019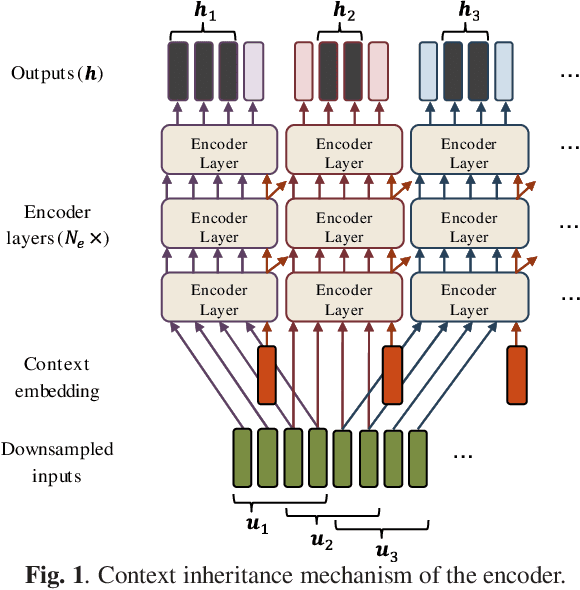
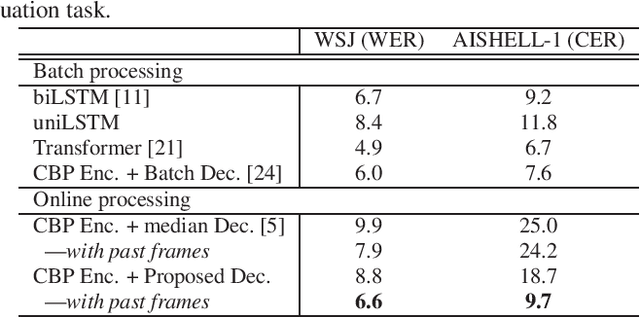
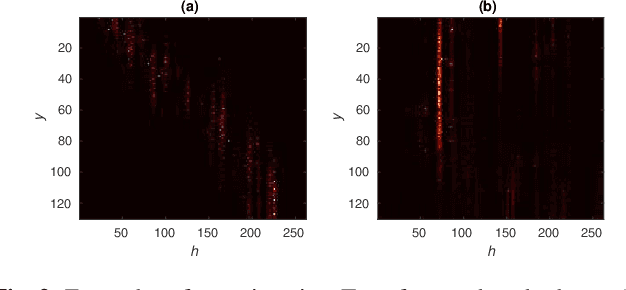
The Transformer self-attention network has recently shown promising performance as an alternative to recurrent neural networks in end-to-end (E2E) automatic speech recognition (ASR) systems. However, Transformer has a drawback in that the entire input sequence is required to compute self-attention. We have proposed a block processing method for the Transformer encoder by introducing a context-aware inheritance mechanism. An additional context embedding vector handed over from the previously processed block helps to encode not only local acoustic information but also global linguistic, channel, and speaker attributes. In this paper, we extend it towards an entire online E2E ASR system by introducing an online decoding process inspired by monotonic chunkwise attention (MoChA) into the Transformer decoder. Our novel MoChA training and inference algorithms exploit the unique properties of Transformer, whose attentions are not always monotonic or peaky, and have multiple heads and residual connections of the decoder layers. Evaluations of the Wall Street Journal (WSJ) and AISHELL-1 show that our proposed online Transformer decoder outperforms conventional chunkwise approaches.
Streaming non-autoregressive model for any-to-many voice conversion
Jun 15, 2022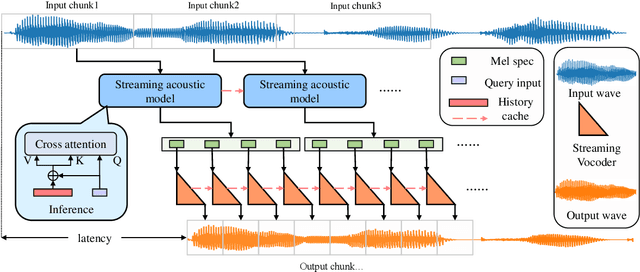
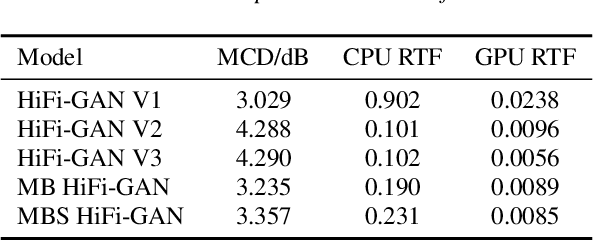
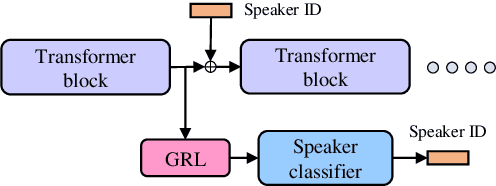
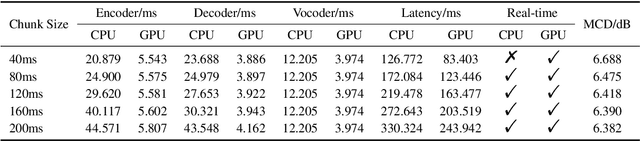
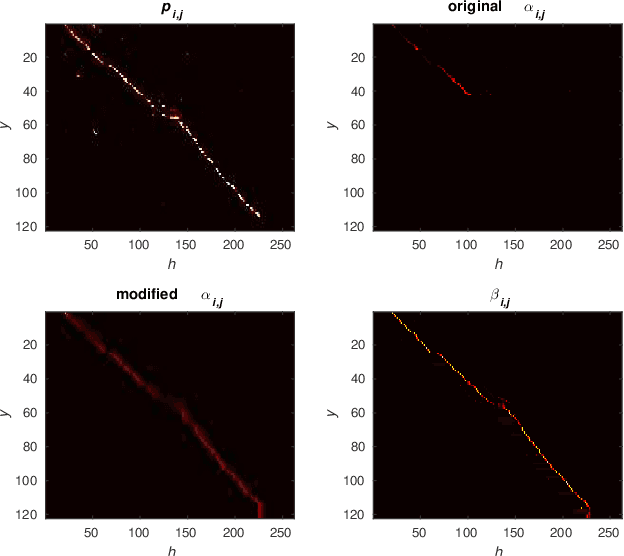
Voice conversion models have developed for decades, and current mainstream research focuses on non-streaming voice conversion. However, streaming voice conversion is more suitable for practical application scenarios than non-streaming voice conversion. In this paper, we propose a streaming any-to-many voice conversion based on fully non-autoregressive model, which includes a streaming transformer based acoustic model and a streaming vocoder. Streaming transformer based acoustic model is composed of a pre-trained encoder from streaming end-to-end based automatic speech recognition model and a decoder modified on FastSpeech blocks. Streaming vocoder is designed for streaming task with pseudo quadrature mirror filter bank and causal convolution. Experimental results show that the proposed method achieves significant performance both in latency and conversion quality and can be real-time on CPU and GPU.
Pruned RNN-T for fast, memory-efficient ASR training
Jun 23, 2022

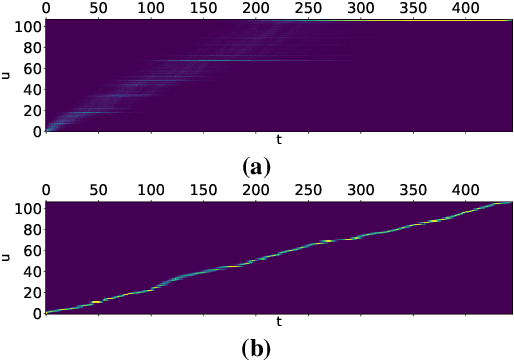
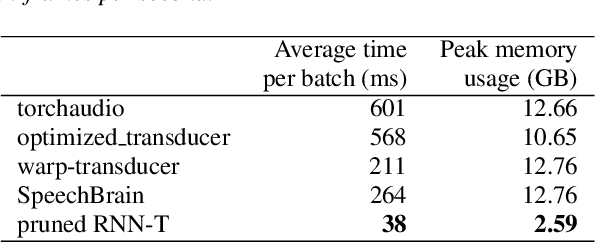
The RNN-Transducer (RNN-T) framework for speech recognition has been growing in popularity, particularly for deployed real-time ASR systems, because it combines high accuracy with naturally streaming recognition. One of the drawbacks of RNN-T is that its loss function is relatively slow to compute, and can use a lot of memory. Excessive GPU memory usage can make it impractical to use RNN-T loss in cases where the vocabulary size is large: for example, for Chinese character-based ASR. We introduce a method for faster and more memory-efficient RNN-T loss computation. We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is linear in the encoder and decoder embeddings; we can evaluate this without using much memory. We then use those pruning bounds to evaluate the full, non-linear joiner network.
End-to-End Automatic Speech Recognition Integrated With CTC-Based Voice Activity Detection
Feb 03, 2020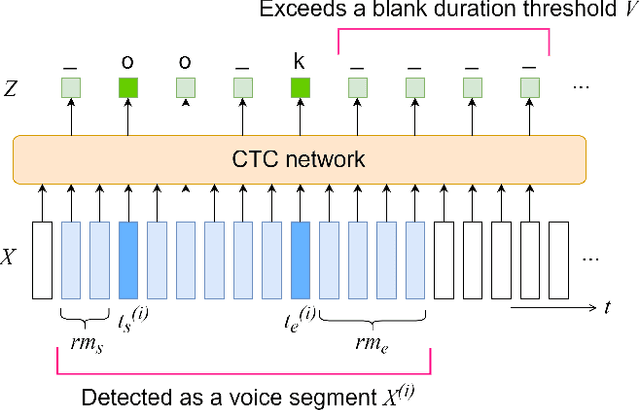
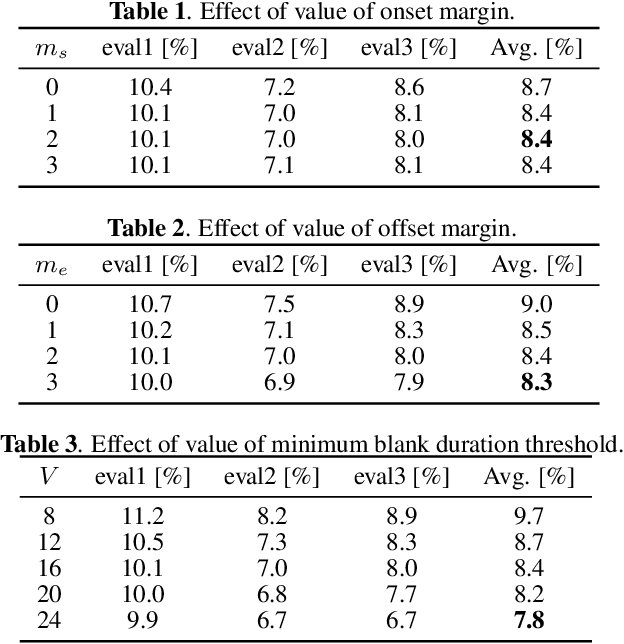
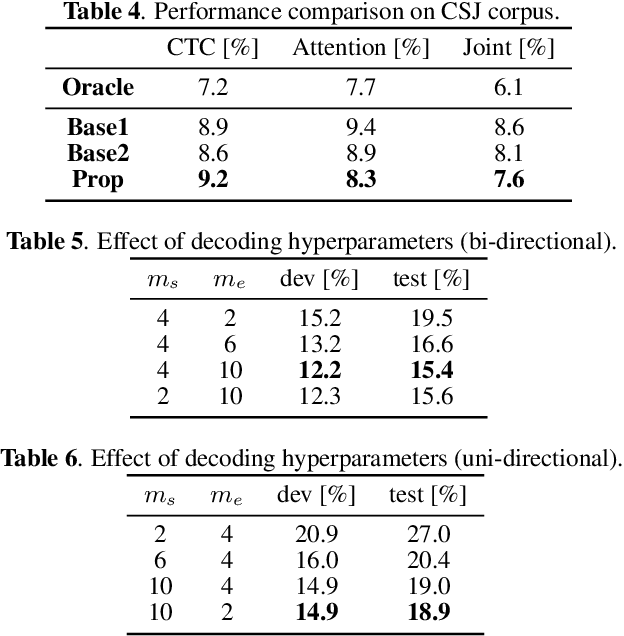

This paper integrates a voice activity detection (VAD) function with end-to-end automatic speech recognition toward an online speech interface and transcribing very long audio recordings. We focus on connectionist temporal classification (CTC) and its extension of CTC/attention architectures. As opposed to an attention-based architecture, input-synchronous label prediction can be performed based on a greedy search with the CTC (pre-)softmax output. This prediction includes consecutive long blank labels, which can be regarded as a non-speech region. We use the labels as a cue for detecting speech segments with simple thresholding. The threshold value is directly related to the length of a non-speech region, which is more intuitive and easier to control than conventional VAD hyperparameters. Experimental results on unsegmented data show that the proposed method outperformed the baseline methods using the conventional energy-based and neural-network-based VAD methods and achieved an RTF less than 0.2. The proposed method is publicly available.
Transformer-based Automatic Speech Recognition of Formal and Colloquial Czech in MALACH Project
Jun 15, 2022


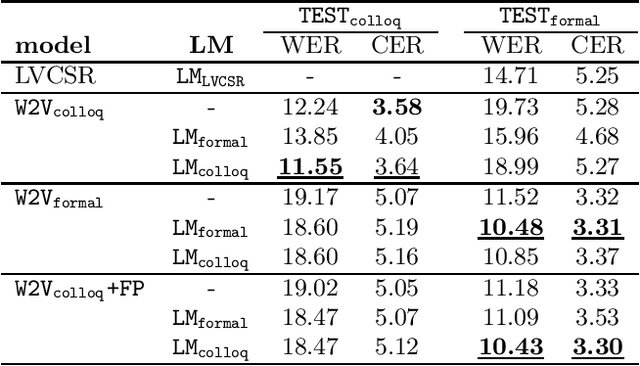
Czech is a very specific language due to its large differences between the formal and the colloquial form of speech. While the formal (written) form is used mainly in official documents, literature, and public speeches, the colloquial (spoken) form is used widely among people in casual speeches. This gap introduces serious problems for ASR systems, especially when training or evaluating ASR models on datasets containing a lot of colloquial speech, such as the MALACH project. In this paper, we are addressing this problem in the light of a new paradigm in end-to-end ASR systems -- recently introduced self-supervised audio Transformers. Specifically, we are investigating the influence of colloquial speech on the performance of Wav2Vec 2.0 models and their ability to transcribe colloquial speech directly into formal transcripts. We are presenting results with both formal and colloquial forms in the training transcripts, language models, and evaluation transcripts.
Multi-view Frequency LSTM: An Efficient Frontend for Automatic Speech Recognition
Jun 30, 2020Acoustic models in real-time speech recognition systems typically stack multiple unidirectional LSTM layers to process the acoustic frames over time. Performance improvements over vanilla LSTM architectures have been reported by prepending a stack of frequency-LSTM (FLSTM) layers to the time LSTM. These FLSTM layers can learn a more robust input feature to the time LSTM layers by modeling time-frequency correlations in the acoustic input signals. A drawback of FLSTM based architectures however is that they operate at a predefined, and tuned, window size and stride, referred to as 'view' in this paper. We present a simple and efficient modification by combining the outputs of multiple FLSTM stacks with different views, into a dimensionality reduced feature representation. The proposed multi-view FLSTM architecture allows to model a wider range of time-frequency correlations compared to an FLSTM model with single view. When trained on 50K hours of English far-field speech data with CTC loss followed by sMBR sequence training, we show that the multi-view FLSTM acoustic model provides relative Word Error Rate (WER) improvements of 3-7% for different speaker and acoustic environment scenarios over an optimized single FLSTM model, while retaining a similar computational footprint.
Kite: Automatic speech recognition for unmanned aerial vehicles
Jul 02, 2019
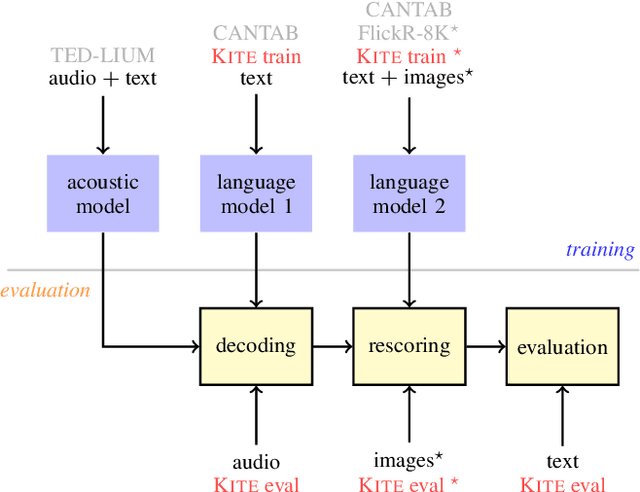
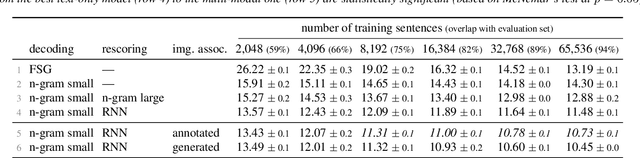
This paper addresses the problem of building a speech recognition system attuned to the control of unmanned aerial vehicles (UAVs). Even though UAVs are becoming widespread, the task of creating voice interfaces for them is largely unaddressed. To this end, we introduce a multi-modal evaluation dataset for UAV control, consisting of spoken commands and associated images, which represent the visual context of what the UAV "sees" when the pilot utters the command. We provide baseline results and address two research directions: (i) how robust the language models are, given an incomplete list of commands at train time; (ii) how to incorporate visual information in the language model. We find that recurrent neural networks (RNNs) are a solution to both tasks: they can be successfully adapted using a small number of commands and they can be extended to use visual cues. Our results show that the image-based RNN outperforms its text-only counterpart even if the command-image training associations are automatically generated and inherently imperfect. The dataset and our code are available at http://kite.speed.pub.ro.
Encrypted Speech Recognition using Deep Polynomial Networks
May 11, 2019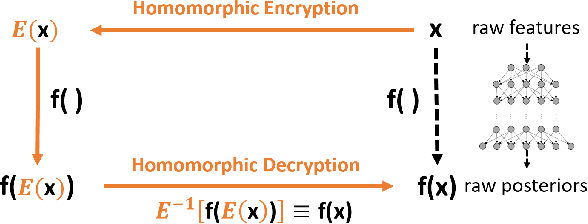
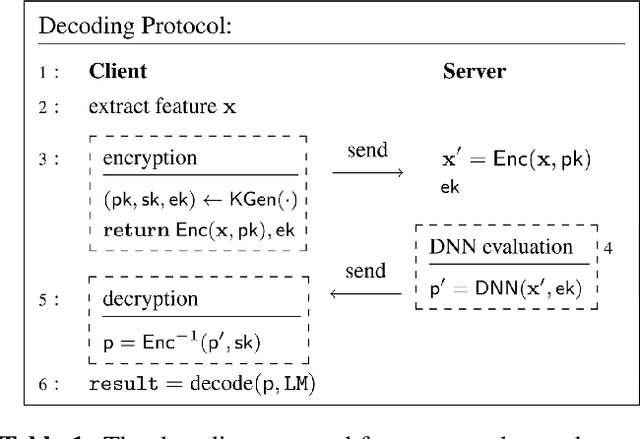
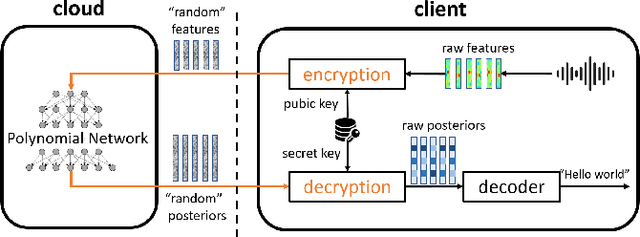
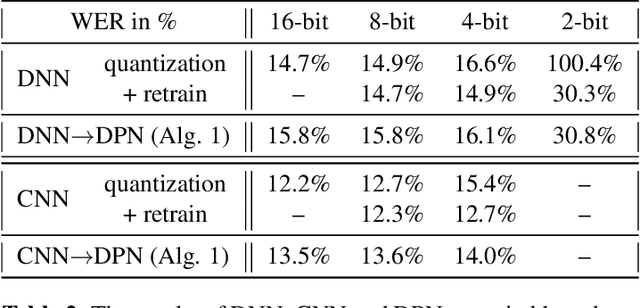
The cloud-based speech recognition/API provides developers or enterprises an easy way to create speech-enabled features in their applications. However, sending audios about personal or company internal information to the cloud, raises concerns about the privacy and security issues. The recognition results generated in cloud may also reveal some sensitive information. This paper proposes a deep polynomial network (DPN) that can be applied to the encrypted speech as an acoustic model. It allows clients to send their data in an encrypted form to the cloud to ensure that their data remains confidential, at mean while the DPN can still make frame-level predictions over the encrypted speech and return them in encrypted form. One good property of the DPN is that it can be trained on unencrypted speech features in the traditional way. To keep the cloud away from the raw audio and recognition results, a cloud-local joint decoding framework is also proposed. We demonstrate the effectiveness of model and framework on the Switchboard and Cortana voice assistant tasks with small performance degradation and latency increased comparing with the traditional cloud-based DNNs.
ClovaCall: Korean Goal-Oriented Dialog Speech Corpus for Automatic Speech Recognition of Contact Centers
Apr 20, 2020
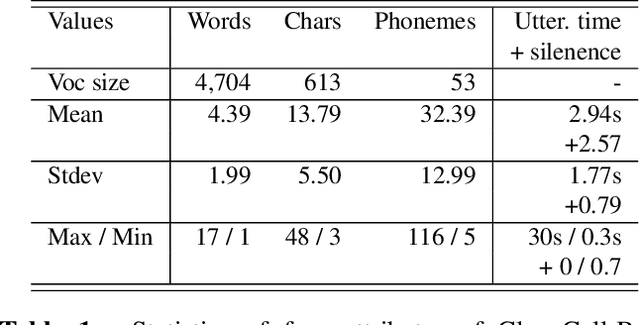
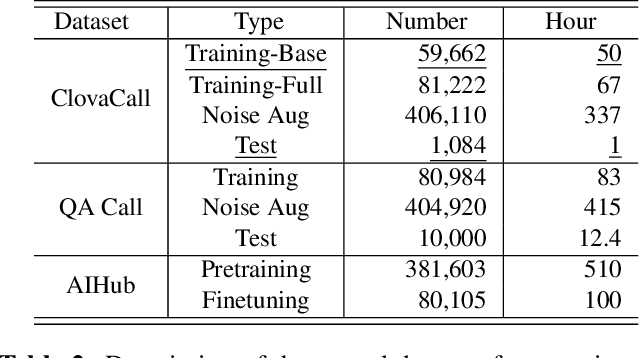
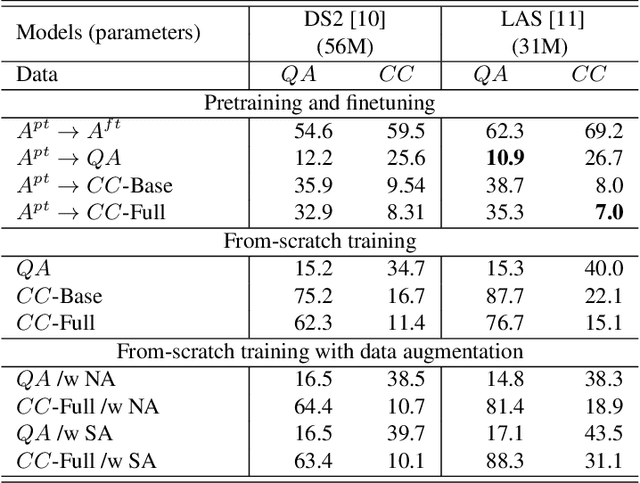
Automatic speech recognition (ASR) via call is essential for various applications, including AI for contact center (AICC) services. Despite the advancement of ASR, however, most publicly available speech corpora such as Switchboard are old-fashioned. Also, most existing call corpora are in English and mainly focus on open-domain dialog or general scenarios such as audiobooks. Here we introduce a new large-scale Korean call-based speech corpus under a goal-oriented dialog scenario from more than 11,000 people, i.e., ClovaCall corpus. ClovaCall includes approximately 60,000 pairs of a short sentence and its corresponding spoken utterance in a restaurant reservation domain. We validate the effectiveness of our dataset with intensive experiments using two standard ASR models. Furthermore, we release our ClovaCall dataset and baseline source codes to be available via https://github.com/ClovaAI/ClovaCall.