 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Large-Scale Visual Speech Recognition
Oct 01, 2018
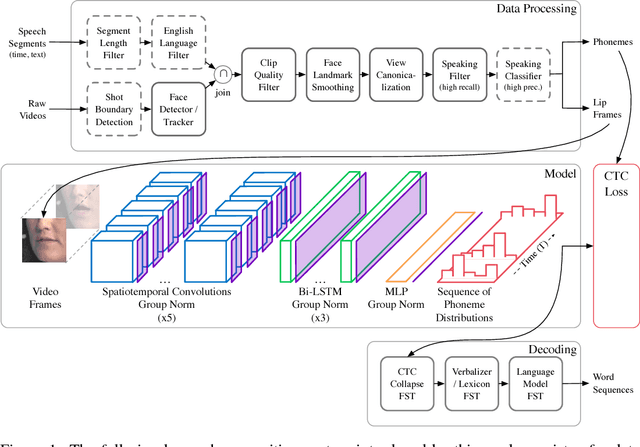
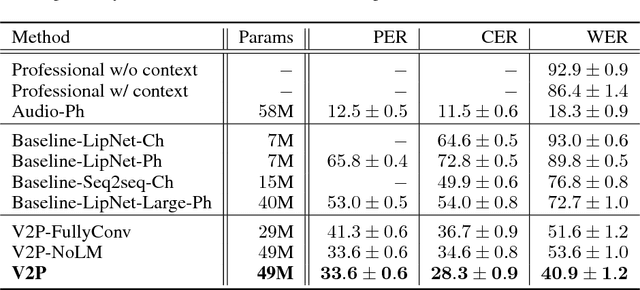


This work presents a scalable solution to open-vocabulary visual speech recognition. To achieve this, we constructed the largest existing visual speech recognition dataset, consisting of pairs of text and video clips of faces speaking (3,886 hours of video). In tandem, we designed and trained an integrated lipreading system, consisting of a video processing pipeline that maps raw video to stable videos of lips and sequences of phonemes, a scalable deep neural network that maps the lip videos to sequences of phoneme distributions, and a production-level speech decoder that outputs sequences of words. The proposed system achieves a word error rate (WER) of 40.9% as measured on a held-out set. In comparison, professional lipreaders achieve either 86.4% or 92.9% WER on the same dataset when having access to additional types of contextual information. Our approach significantly improves on other lipreading approaches, including variants of LipNet and of Watch, Attend, and Spell (WAS), which are only capable of 89.8% and 76.8% WER respectively.
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021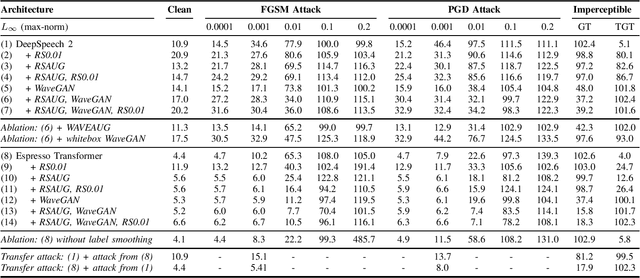
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.
Constructing Effective Machine Learning Models for the Sciences: A Multidisciplinary Perspective
Nov 21, 2022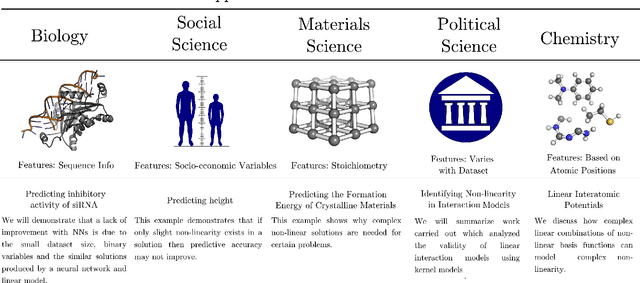
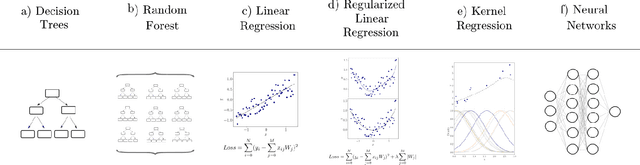
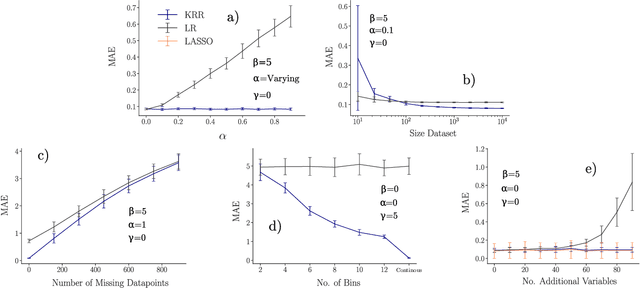
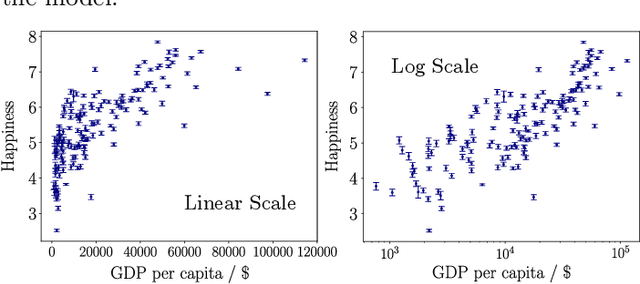
Learning from data has led to substantial advances in a multitude of disciplines, including text and multimedia search, speech recognition, and autonomous-vehicle navigation. Can machine learning enable similar leaps in the natural and social sciences? This is certainly the expectation in many scientific fields and recent years have seen a plethora of applications of non-linear models to a wide range of datasets. However, flexible non-linear solutions will not always improve upon manually adding transforms and interactions between variables to linear regression models. We discuss how to recognize this before constructing a data-driven model and how such analysis can help us move to intrinsically interpretable regression models. Furthermore, for a variety of applications in the natural and social sciences we demonstrate why improvements may be seen with more complex regression models and why they may not.
There is more than one kind of robustness: Fooling Whisper with adversarial examples
Oct 26, 2022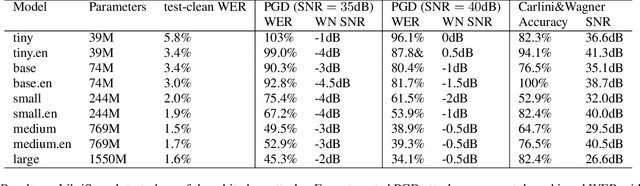
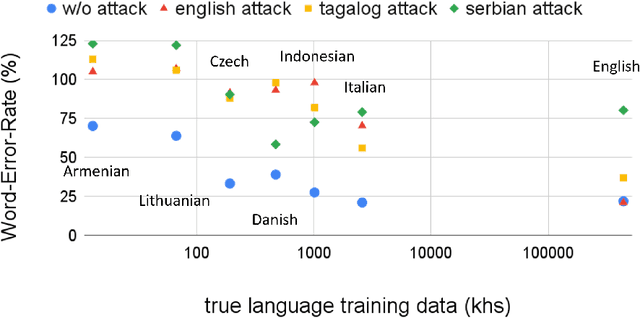

Whisper is a recent Automatic Speech Recognition (ASR) model displaying impressive robustness to both out-of-distribution inputs and random noise. In this work, we show that this robustness does not carry over to adversarial noise. We generate very small input perturbations with Signal Noise Ratio of up to 45dB, with which we can degrade Whisper performance dramatically, or even transcribe a target sentence of our choice. We also show that by fooling the Whisper language detector we can very easily degrade the performance of multilingual models. These vulnerabilities of a widely popular open-source model have practical security implications, and emphasize the need for adversarially robust ASR.
Multichannel Robot Speech Recognition Database: MChRSR
Dec 30, 2017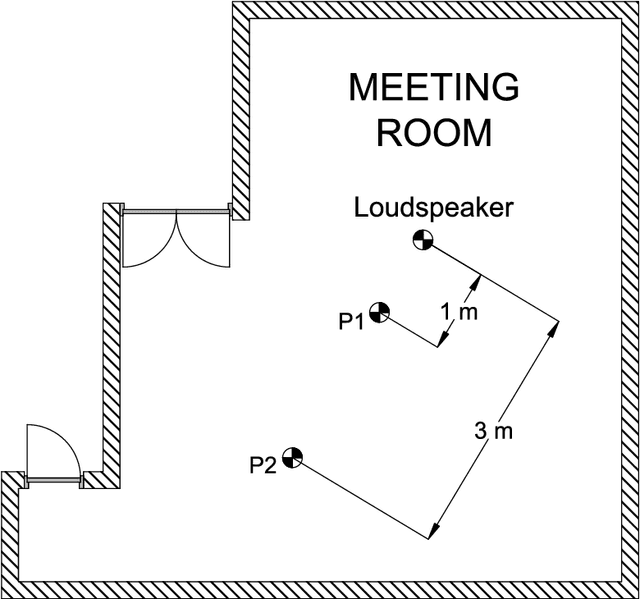

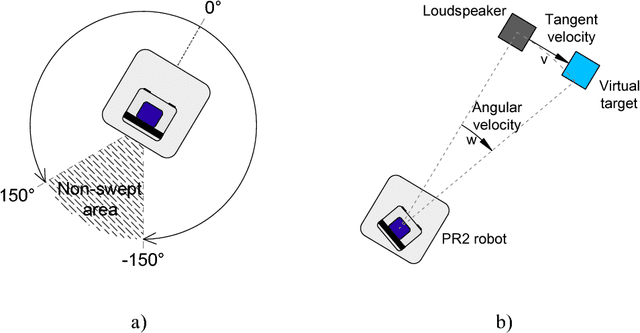
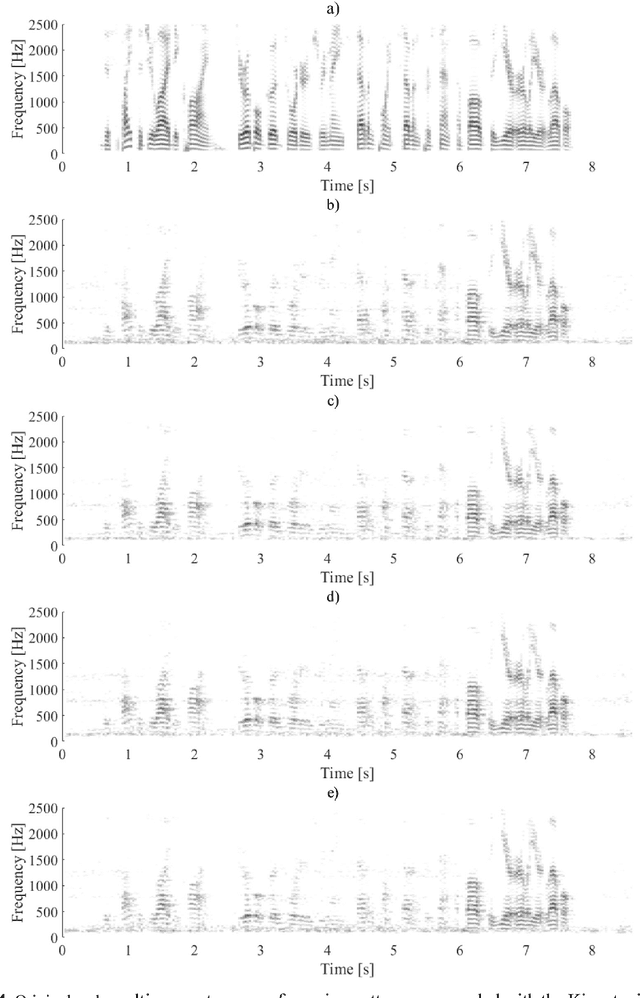
In real human robot interaction (HRI) scenarios, speech recognition represents a major challenge due to robot noise, background noise and time-varying acoustic channel. This document describes the procedure used to obtain the Multichannel Robot Speech Recognition Database (MChRSR). It is composed of 12 hours of multichannel evaluation data recorded in a real mobile HRI scenario. This database was recorded with a PR2 robot performing different translational and azimuthal movements. Accordingly, 16 evaluation sets were obtained re-recording the clean set of the Aurora 4 database in different movement conditions.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022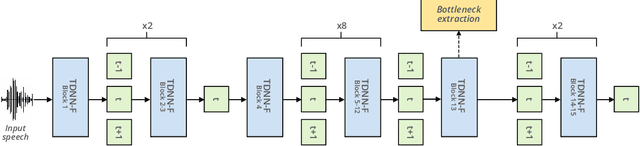

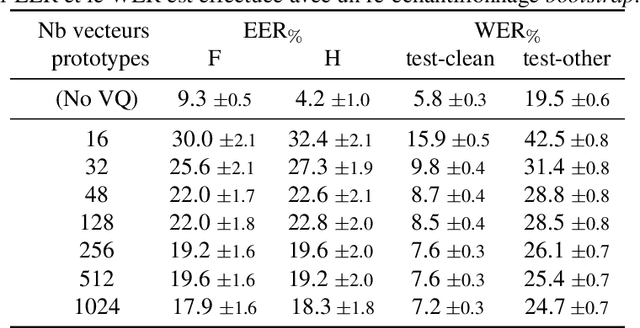
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021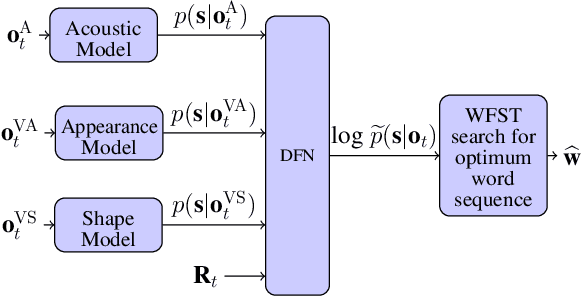
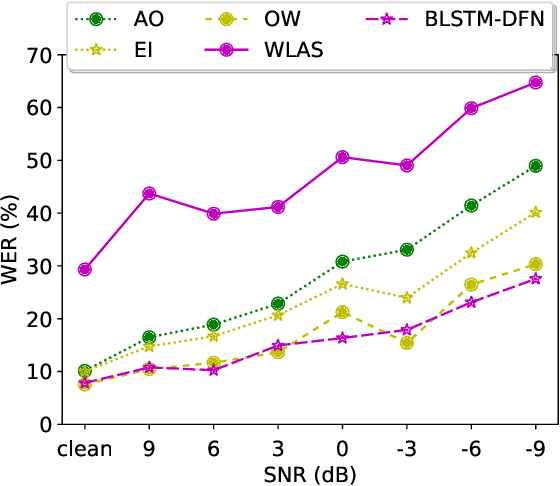

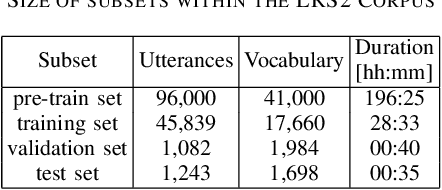
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jul 08, 2021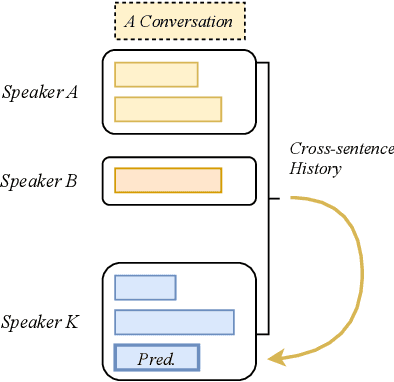
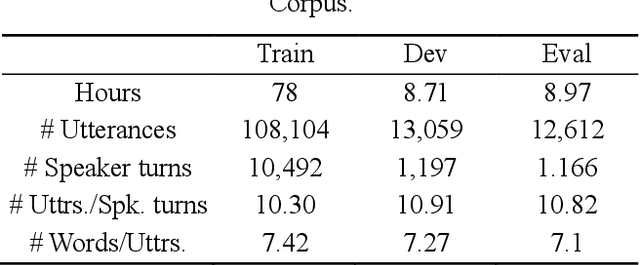
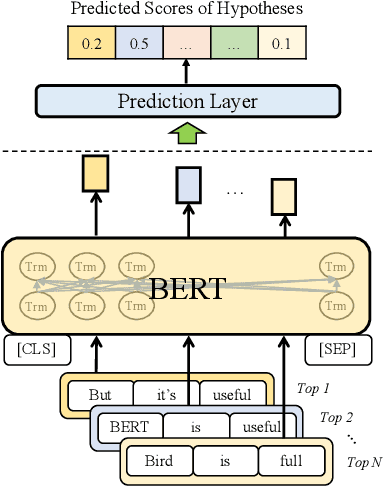
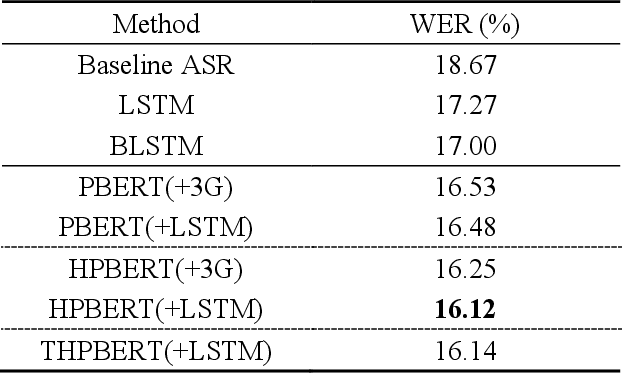
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Building a Noisy Audio Dataset to Evaluate Machine Learning Approaches for Automatic Speech Recognition Systems
Oct 04, 2021

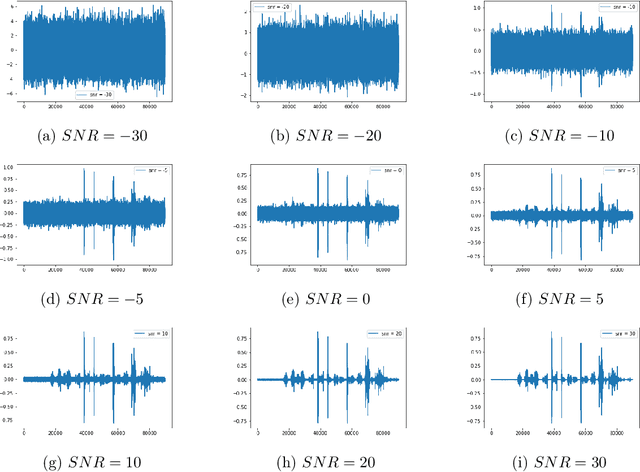
Automatic speech recognition systems are part of people's daily lives, embedded in personal assistants and mobile phones, helping as a facilitator for human-machine interaction while allowing access to information in a practically intuitive way. Such systems are usually implemented using machine learning techniques, especially with deep neural networks. Even with its high performance in the task of transcribing text from speech, few works address the issue of its recognition in noisy environments and, usually, the datasets used do not contain noisy audio examples, while only mitigating this issue using data augmentation techniques. This work aims to present the process of building a dataset of noisy audios, in a specific case of degenerated audios due to interference, commonly present in radio transmissions. Additionally, we present initial results of a classifier that uses such data for evaluation, indicating the benefits of using this dataset in the recognizer's training process. Such recognizer achieves an average result of 0.4116 in terms of character error rate in the noisy set (SNR = 30).
Preliminary Study on SSCF-derived Polar Coordinate for ASR
Nov 30, 2022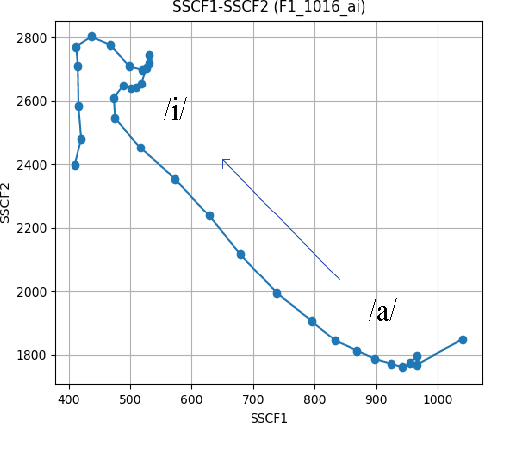

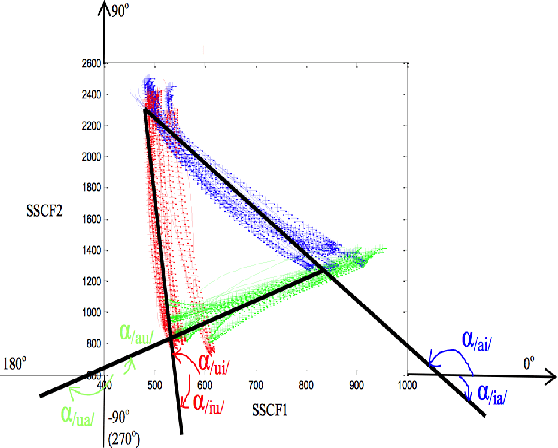

The transition angles are defined to describe the vowel-to-vowel transitions in the acoustic space of the Spectral Subband Centroids, and the findings show that they are similar among speakers and speaking rates. In this paper, we propose to investigate the usage of polar coordinates in favor of angles to describe a speech signal by characterizing its acoustic trajectory and using them in Automatic Speech Recognition. According to the experimental results evaluated on the BRAF100 dataset, the polar coordinates achieved significantly higher accuracy than the angles in the mixed and cross-gender speech recognitions, demonstrating that these representations are superior at defining the acoustic trajectory of the speech signal. Furthermore, the accuracy was significantly improved when they were utilized with their first and second-order derivatives ($\Delta$, $\Delta$$\Delta$), especially in cross-female recognition. However, the results showed they were not much more gender-independent than the conventional Mel-frequency Cepstral Coefficients (MFCCs).