 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023
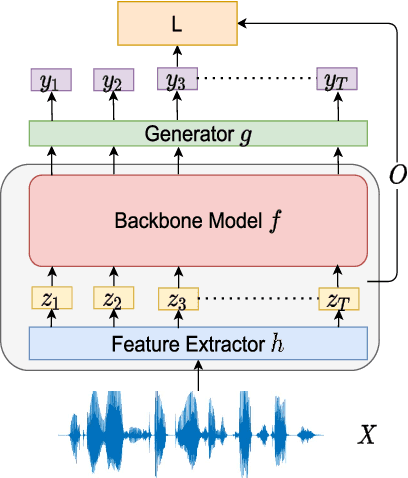
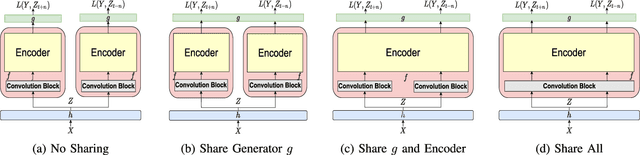
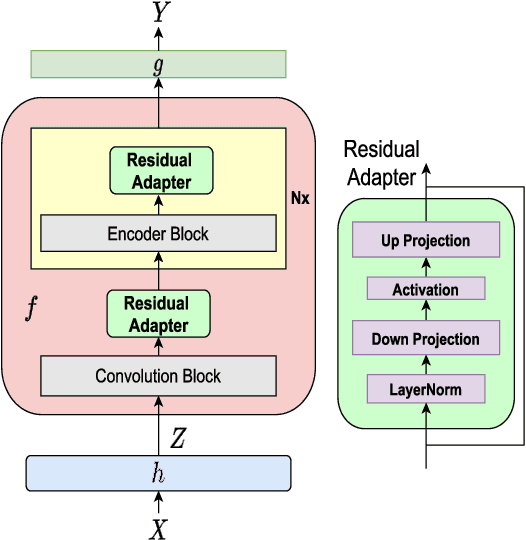
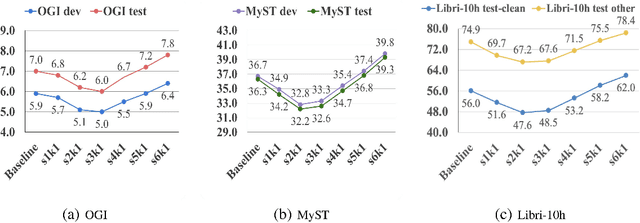
Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
JTubeSpeech: corpus of Japanese speech collected from YouTube for speech recognition and speaker verification
Dec 17, 2021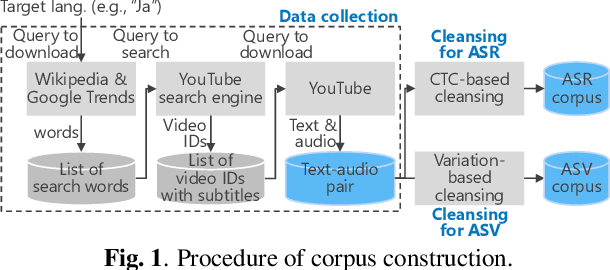

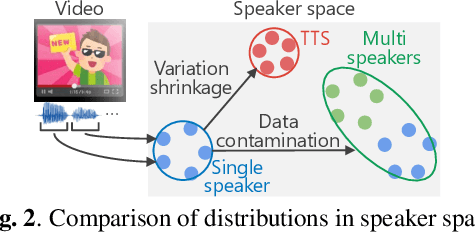
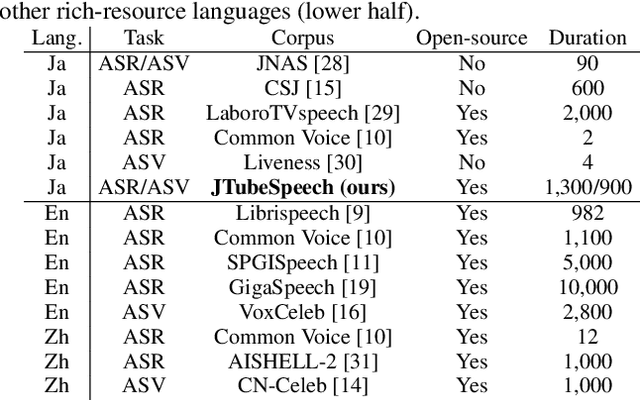
In this paper, we construct a new Japanese speech corpus called "JTubeSpeech." Although recent end-to-end learning requires large-size speech corpora, open-sourced such corpora for languages other than English have not yet been established. In this paper, we describe the construction of a corpus from YouTube videos and subtitles for speech recognition and speaker verification. Our method can automatically filter the videos and subtitles with almost no language-dependent processes. We consistently employ Connectionist Temporal Classification (CTC)-based techniques for automatic speech recognition (ASR) and a speaker variation-based method for automatic speaker verification (ASV). We build 1) a large-scale Japanese ASR benchmark with more than 1,300 hours of data and 2) 900 hours of data for Japanese ASV.
A Deliberation-based Joint Acoustic and Text Decoder
Mar 23, 2023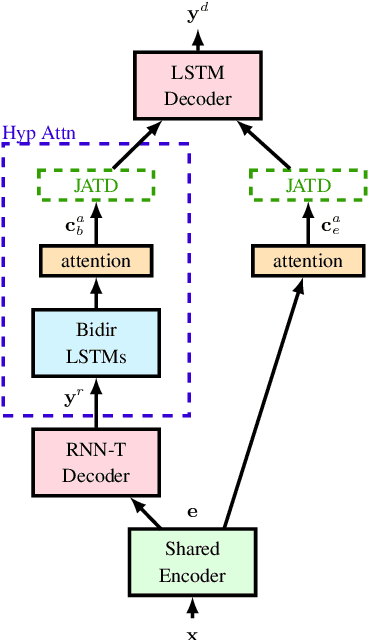
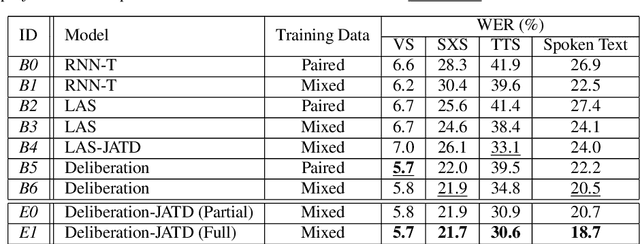
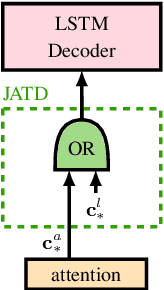
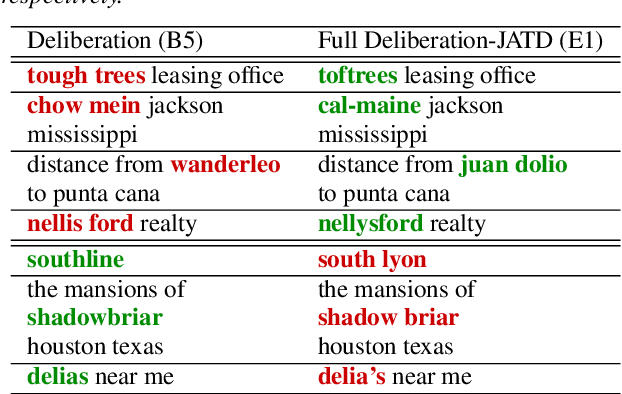
We propose a new two-pass E2E speech recognition model that improves ASR performance by training on a combination of paired data and unpaired text data. Previously, the joint acoustic and text decoder (JATD) has shown promising results through the use of text data during model training and the recently introduced deliberation architecture has reduced recognition errors by leveraging first-pass decoding results. Our method, dubbed Deliberation-JATD, combines the spelling correcting abilities of deliberation with JATD's use of unpaired text data to further improve performance. The proposed model produces substantial gains across multiple test sets, especially those focused on rare words, where it reduces word error rate (WER) by between 12% and 22.5% relative. This is done without increasing model size or requiring multi-stage training, making Deliberation-JATD an efficient candidate for on-device applications.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 20, 2022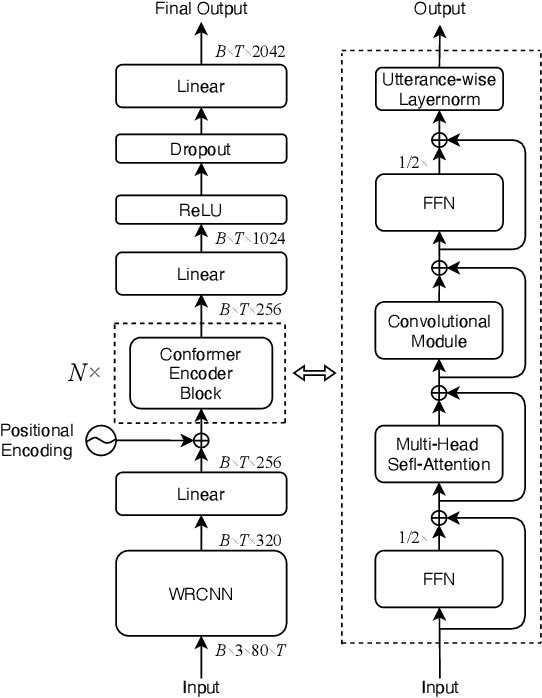
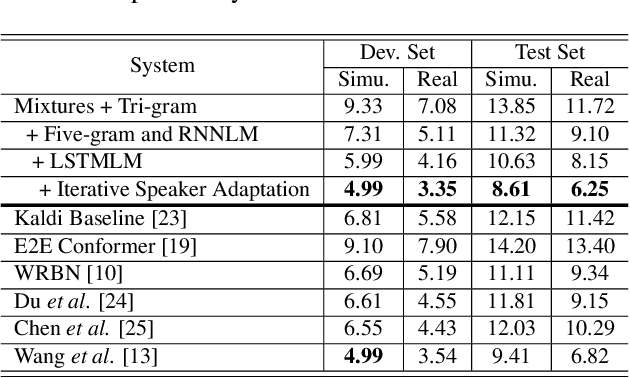
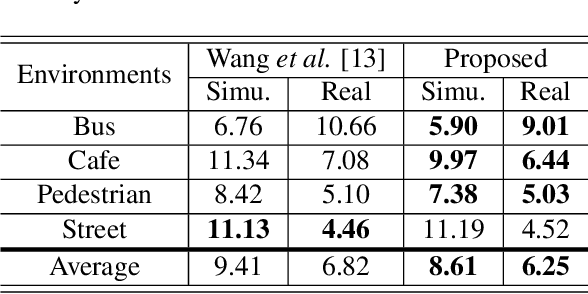
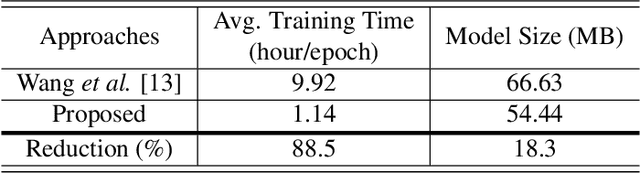
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces total training time by $79.6\%$.
Silent versus modal multi-speaker speech recognition from ultrasound and video
Feb 27, 2021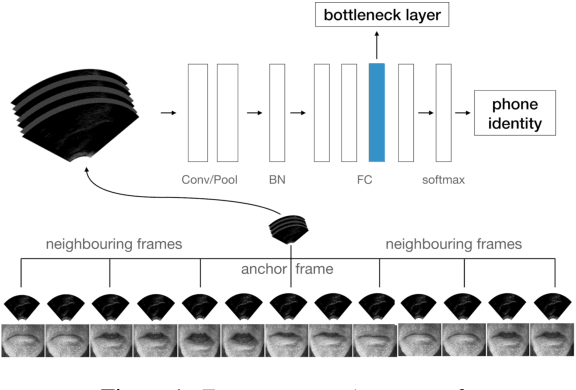
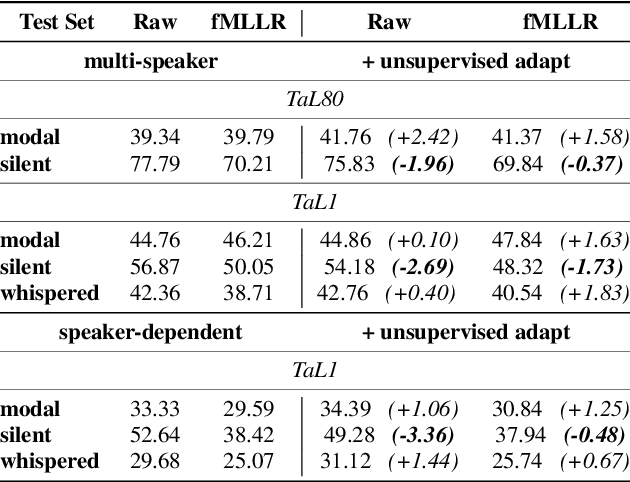
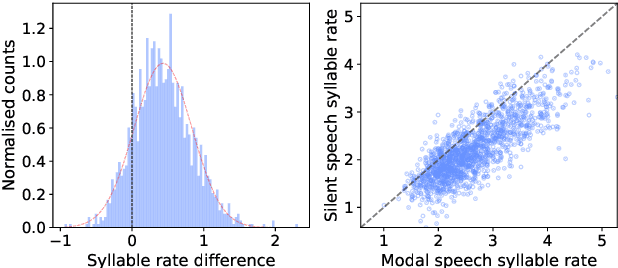

We investigate multi-speaker speech recognition from ultrasound images of the tongue and video images of the lips. We train our systems on imaging data from modal speech, and evaluate on matched test sets of two speaking modes: silent and modal speech. We observe that silent speech recognition from imaging data underperforms compared to modal speech recognition, likely due to a speaking-mode mismatch between training and testing. We improve silent speech recognition performance using techniques that address the domain mismatch, such as fMLLR and unsupervised model adaptation. We also analyse the properties of silent and modal speech in terms of utterance duration and the size of the articulatory space. To estimate the articulatory space, we compute the convex hull of tongue splines, extracted from ultrasound tongue images. Overall, we observe that the duration of silent speech is longer than that of modal speech, and that silent speech covers a smaller articulatory space than modal speech. Although these two properties are statistically significant across speaking modes, they do not directly correlate with word error rates from speech recognition.
Data Augmentation for Speech Recognition in Maltese: A Low-Resource Perspective
Nov 15, 2021
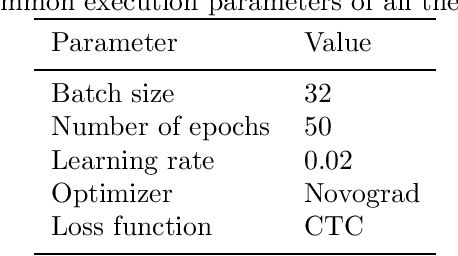


Developing speech technologies is a challenge for low-resource languages for which both annotated and raw speech data is sparse. Maltese is one such language. Recent years have seen an increased interest in the computational processing of Maltese, including speech technologies, but resources for the latter remain sparse. In this paper, we consider data augmentation techniques for improving speech recognition for such languages, focusing on Maltese as a test case. We consider three different types of data augmentation: unsupervised training, multilingual training and the use of synthesized speech as training data. The goal is to determine which of these techniques, or combination of them, is the most effective to improve speech recognition for languages where the starting point is a small corpus of approximately 7 hours of transcribed speech. Our results show that combining the three data augmentation techniques studied here lead us to an absolute WER improvement of 15% without the use of a language model.
End-to-End Neural Systems for Automatic Children Speech Recognition: An Empirical Study
Feb 19, 2021
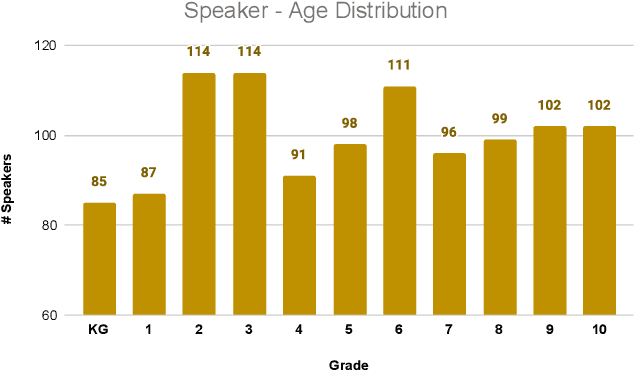
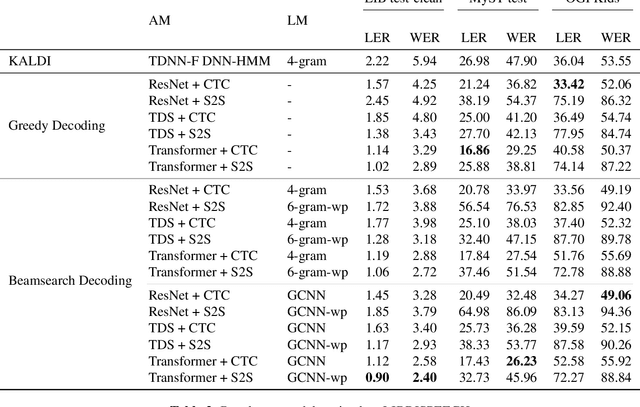
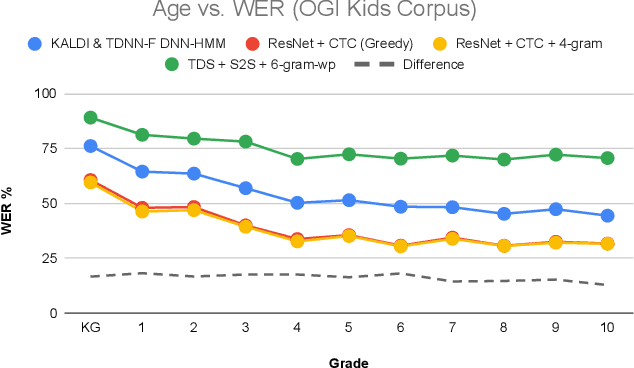
A key desiderata for inclusive and accessible speech recognition technology is ensuring its robust performance to children's speech. Notably, this includes the rapidly advancing neural network based end-to-end speech recognition systems. Children speech recognition is more challenging due to the larger intra-inter speaker variability in terms of acoustic and linguistic characteristics compared to adult speech. Furthermore, the lack of adequate and appropriate children speech resources adds to the challenge of designing robust end-to-end neural architectures. This study provides a critical assessment of automatic children speech recognition through an empirical study of contemporary state-of-the-art end-to-end speech recognition systems. Insights are provided on the aspects of training data requirements, adaptation on children data, and the effect of children age, utterance lengths, different architectures and loss functions for end-to-end systems and role of language models on the speech recognition performance.
Continuous Silent Speech Recognition using EEG
Mar 15, 2020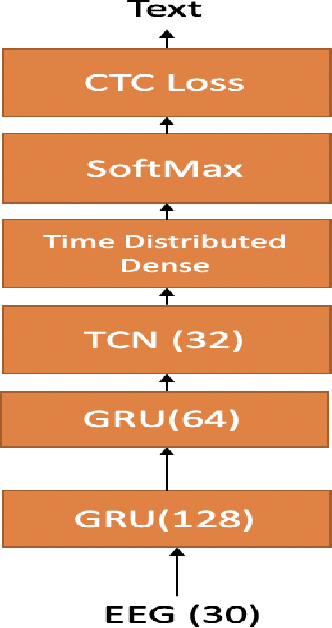
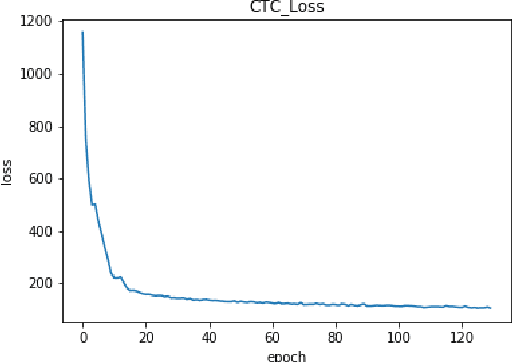
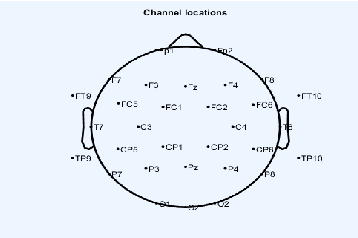
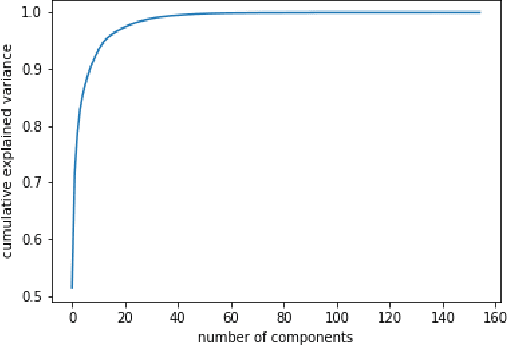
In this paper we explore continuous silent speech recognition using electroencephalography (EEG) signals. We implemented a connectionist temporal classification (CTC) automatic speech recognition (ASR) model to translate EEG signals recorded in parallel while subjects were reading English sentences in their mind without producing any voice to text. Our results demonstrate the feasibility of using EEG signals for performing continuous silent speech recognition. We demonstrate our results for a limited English vocabulary consisting of 30 unique sentences.
AV Taris: Online Audio-Visual Speech Recognition
Dec 14, 2020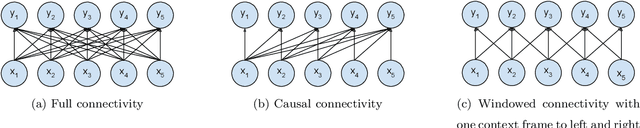

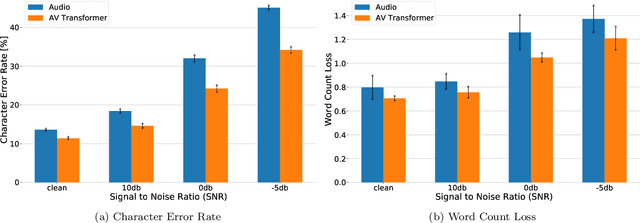
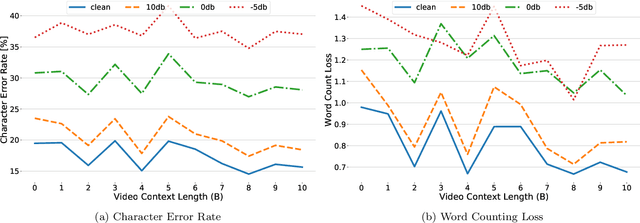
In recent years, Automatic Speech Recognition (ASR) technology has approached human-level performance on conversational speech under relatively clean listening conditions. In more demanding situations involving distant microphones, overlapped speech, background noise, or natural dialogue structures, the ASR error rate is at least an order of magnitude higher. The visual modality of speech carries the potential to partially overcome these challenges and contribute to the sub-tasks of speaker diarisation, voice activity detection, and the recovery of the place of articulation, and can compensate for up to 15dB of noise on average. This article develops AV Taris, a fully differentiable neural network model capable of decoding audio-visual speech in real time. We achieve this by connecting two recently proposed models for audio-visual speech integration and online speech recognition, namely AV Align and Taris. We evaluate AV Taris under the same conditions as AV Align and Taris on one of the largest publicly available audio-visual speech datasets, LRS2. Our results show that AV Taris is superior to the audio-only variant of Taris, demonstrating the utility of the visual modality to speech recognition within the real time decoding framework defined by Taris. Compared to an equivalent Transformer-based AV Align model that takes advantage of full sentences without meeting the real-time requirement, we report an absolute degradation of approximately 3% with AV Taris. As opposed to the more popular alternative for online speech recognition, namely the RNN Transducer, Taris offers a greatly simplified fully differentiable training pipeline. As a consequence, AV Taris has the potential to popularise the adoption of Audio-Visual Speech Recognition (AVSR) technology and overcome the inherent limitations of the audio modality in less optimal listening conditions.
Frequency-Directional Attention Model for Multilingual Automatic Speech Recognition
Mar 29, 2022
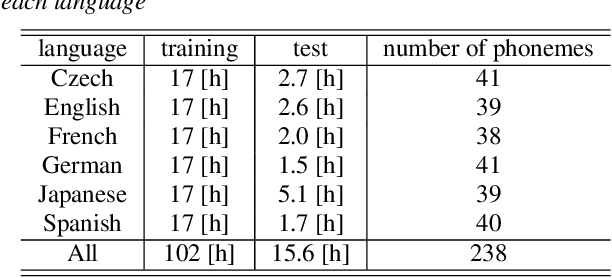
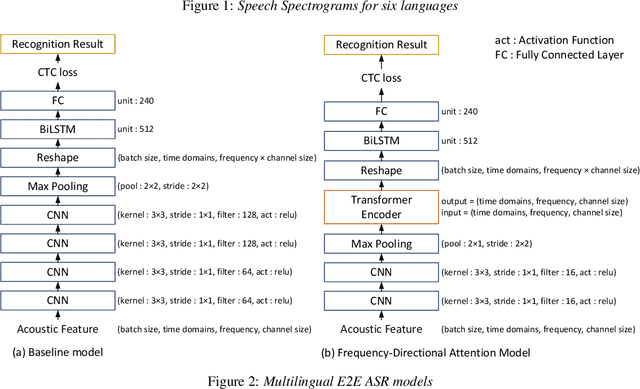

This paper proposes a model for transforming speech features using the frequency-directional attention model for End-to-End (E2E) automatic speech recognition. The idea is based on the hypothesis that in the phoneme system of each language, the characteristics of the frequency bands of speech when uttering them are different. By transforming the input Mel filter bank features with an attention model that characterizes the frequency direction, a feature transformation suitable for ASR in each language can be expected. This paper introduces a Transformer-encoder as a frequency-directional attention model. We evaluated the proposed method on a multilingual E2E ASR system for six different languages and found that the proposed method could achieve, on average, 5.3 points higher accuracy than the ASR model for each language by introducing the frequency-directional attention mechanism. Furthermore, visualization of the attention weights based on the proposed method suggested that it is possible to transform acoustic features considering the frequency characteristics of each language.