 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neural Systems for Automatic Children Speech Recognition: An Empirical Study
Paper and Code

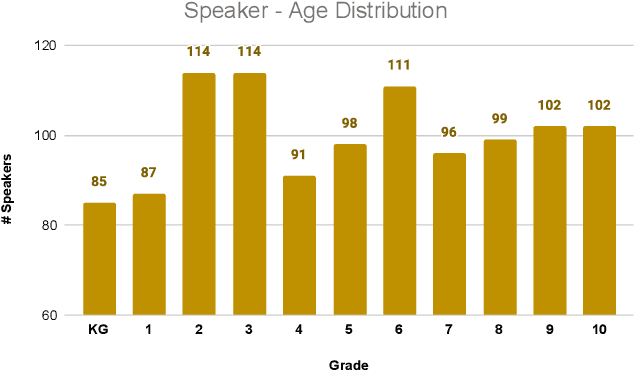
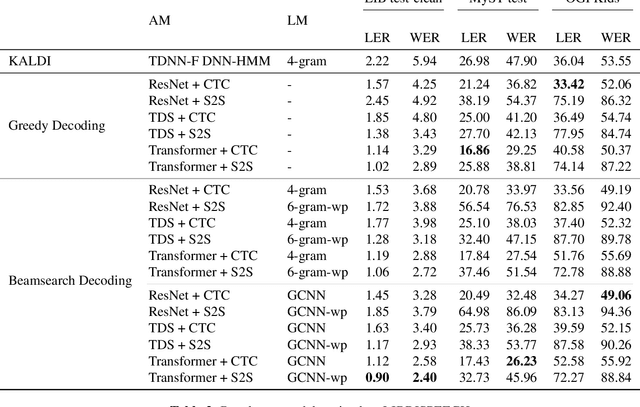
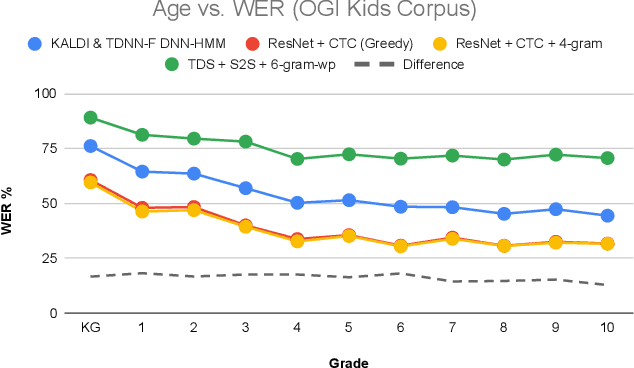
A key desiderata for inclusive and accessible speech recognition technology is ensuring its robust performance to children's speech. Notably, this includes the rapidly advancing neural network based end-to-end speech recognition systems. Children speech recognition is more challenging due to the larger intra-inter speaker variability in terms of acoustic and linguistic characteristics compared to adult speech. Furthermore, the lack of adequate and appropriate children speech resources adds to the challenge of designing robust end-to-end neural architectures. This study provides a critical assessment of automatic children speech recognition through an empirical study of contemporary state-of-the-art end-to-end speech recognition systems. Insights are provided on the aspects of training data requirements, adaptation on children data, and the effect of children age, utterance lengths, different architectures and loss functions for end-to-end systems and role of language models on the speech recognition performance.