 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
HSPACE: Synthetic Parametric Humans Animated in Complex Environments
Jan 06, 2022
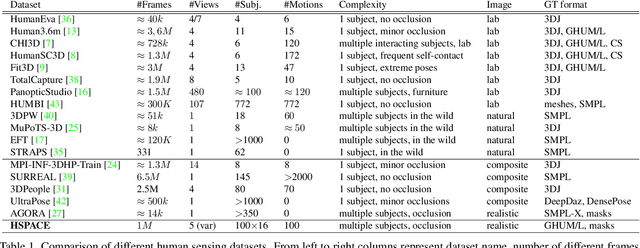
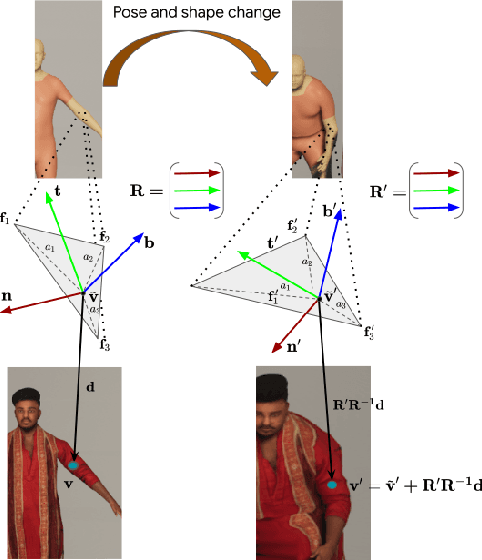
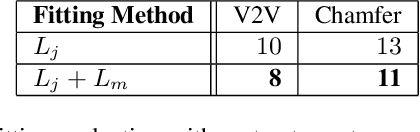
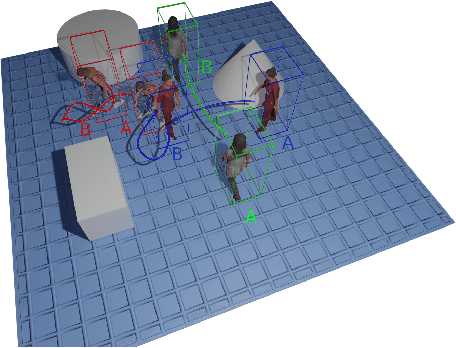
Advances in the state of the art for 3d human sensing are currently limited by the lack of visual datasets with 3d ground truth, including multiple people, in motion, operating in real-world environments, with complex illumination or occlusion, and potentially observed by a moving camera. Sophisticated scene understanding would require estimating human pose and shape as well as gestures, towards representations that ultimately combine useful metric and behavioral signals with free-viewpoint photo-realistic visualisation capabilities. To sustain progress, we build a large-scale photo-realistic dataset, Human-SPACE (HSPACE), of animated humans placed in complex synthetic indoor and outdoor environments. We combine a hundred diverse individuals of varying ages, gender, proportions, and ethnicity, with hundreds of motions and scenes, as well as parametric variations in body shape (for a total of 1,600 different humans), in order to generate an initial dataset of over 1 million frames. Human animations are obtained by fitting an expressive human body model, GHUM, to single scans of people, followed by novel re-targeting and positioning procedures that support the realistic animation of dressed humans, statistical variation of body proportions, and jointly consistent scene placement of multiple moving people. Assets are generated automatically, at scale, and are compatible with existing real time rendering and game engines. The dataset with evaluation server will be made available for research. Our large-scale analysis of the impact of synthetic data, in connection with real data and weak supervision, underlines the considerable potential for continuing quality improvements and limiting the sim-to-real gap, in this practical setting, in connection with increased model capacity.
Photo-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Mar 06, 2019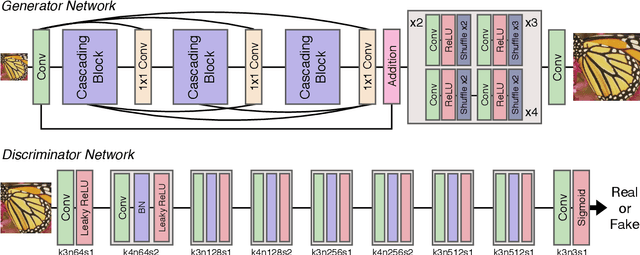
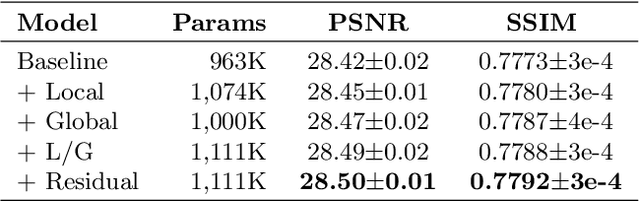
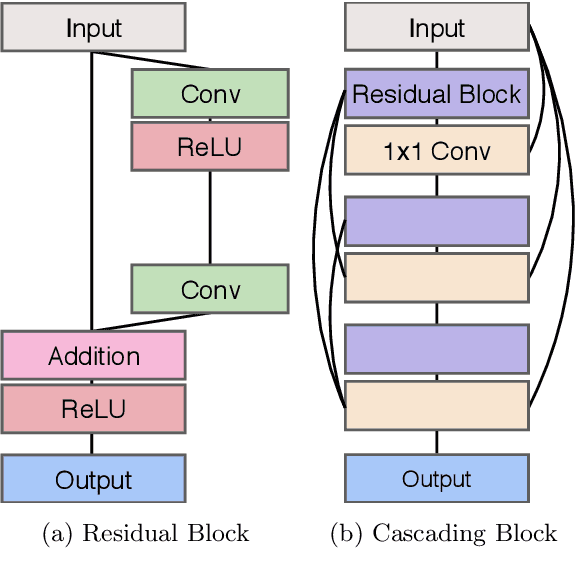

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.
Photo Stylistic Brush: Robust Style Transfer via Superpixel-Based Bipartite Graph
Jul 15, 2016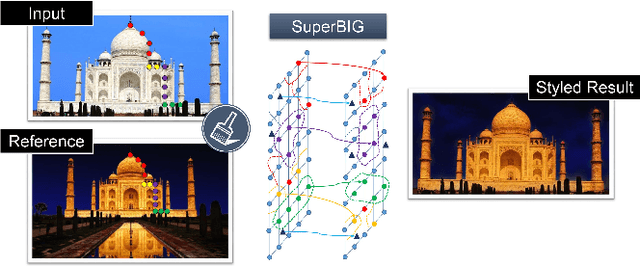
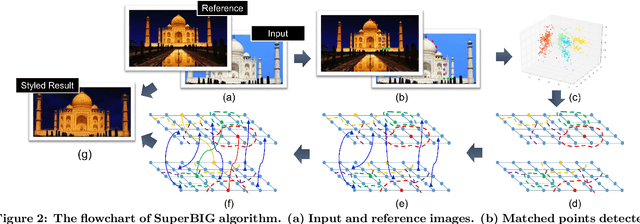


With the rapid development of social network and multimedia technology, customized image and video stylization has been widely used for various social-media applications. In this paper, we explore the problem of exemplar-based photo style transfer, which provides a flexible and convenient way to invoke fantastic visual impression. Rather than investigating some fixed artistic patterns to represent certain styles as was done in some previous works, our work emphasizes styles related to a series of visual effects in the photograph, e.g. color, tone, and contrast. We propose a photo stylistic brush, an automatic robust style transfer approach based on Superpixel-based BIpartite Graph (SuperBIG). A two-step bipartite graph algorithm with different granularity levels is employed to aggregate pixels into superpixels and find their correspondences. In the first step, with the extracted hierarchical features, a bipartite graph is constructed to describe the content similarity for pixel partition to produce superpixels. In the second step, superpixels in the input/reference image are rematched to form a new superpixel-based bipartite graph, and superpixel-level correspondences are generated by a bipartite matching. Finally, the refined correspondence guides SuperBIG to perform the transformation in a decorrelated color space. Extensive experimental results demonstrate the effectiveness and robustness of the proposed method for transferring various styles of exemplar images, even for some challenging cases, such as night images.
InteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset
Sep 03, 2018
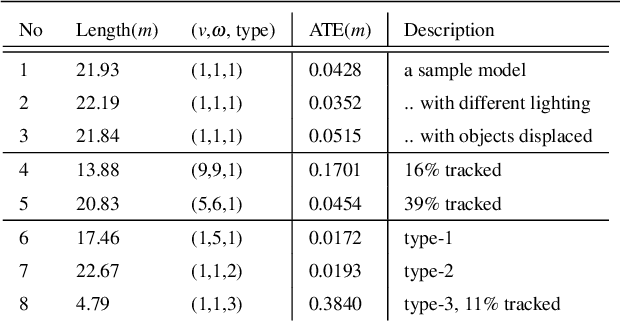

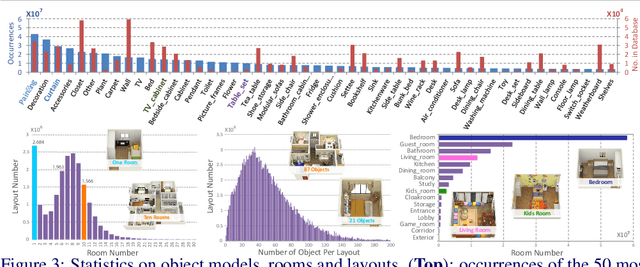
Datasets have gained an enormous amount of popularity in the computer vision community, from training and evaluation of Deep Learning-based methods to benchmarking Simultaneous Localization and Mapping (SLAM). Without a doubt, synthetic imagery bears a vast potential due to scalability in terms of amounts of data obtainable without tedious manual ground truth annotations or measurements. Here, we present a dataset with the aim of providing a higher degree of photo-realism, larger scale, more variability as well as serving a wider range of purposes compared to existing datasets. Our dataset leverages the availability of millions of professional interior designs and millions of production-level furniture and object assets -- all coming with fine geometric details and high-resolution texture. We render high-resolution and high frame-rate video sequences following realistic trajectories while supporting various camera types as well as providing inertial measurements. Together with the release of the dataset, we will make executable program of our interactive simulator software as well as our renderer available at https://interiornetdataset.github.io. To showcase the usability and uniqueness of our dataset, we show benchmarking results of both sparse and dense SLAM algorithms.
SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image
Apr 02, 2022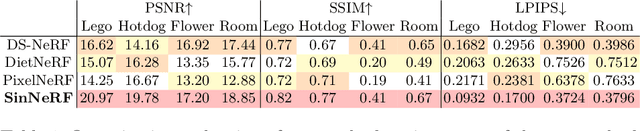
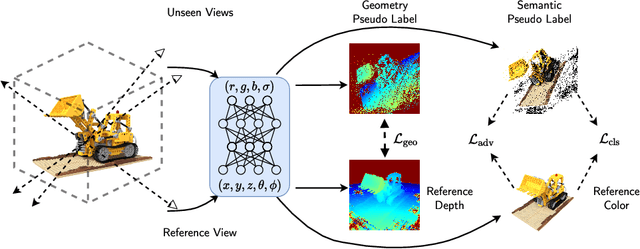


Despite the rapid development of Neural Radiance Field (NeRF), the necessity of dense covers largely prohibits its wider applications. While several recent works have attempted to address this issue, they either operate with sparse views (yet still, a few of them) or on simple objects/scenes. In this work, we consider a more ambitious task: training neural radiance field, over realistically complex visual scenes, by "looking only once", i.e., using only a single view. To attain this goal, we present a Single View NeRF (SinNeRF) framework consisting of thoughtfully designed semantic and geometry regularizations. Specifically, SinNeRF constructs a semi-supervised learning process, where we introduce and propagate geometry pseudo labels and semantic pseudo labels to guide the progressive training process. Extensive experiments are conducted on complex scene benchmarks, including NeRF synthetic dataset, Local Light Field Fusion dataset, and DTU dataset. We show that even without pre-training on multi-view datasets, SinNeRF can yield photo-realistic novel-view synthesis results. Under the single image setting, SinNeRF significantly outperforms the current state-of-the-art NeRF baselines in all cases. Project page: https://vita-group.github.io/SinNeRF/
Depth estimation of endoscopy using sim-to-real transfer
Dec 27, 2021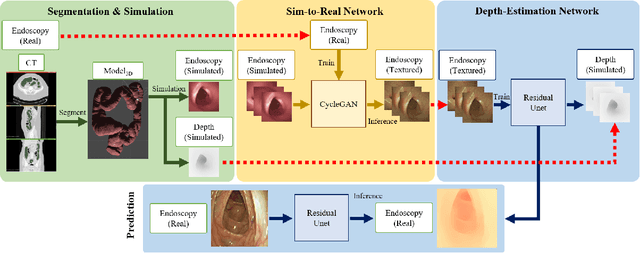
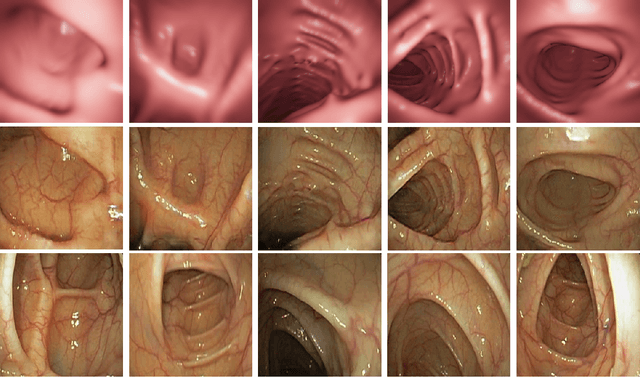
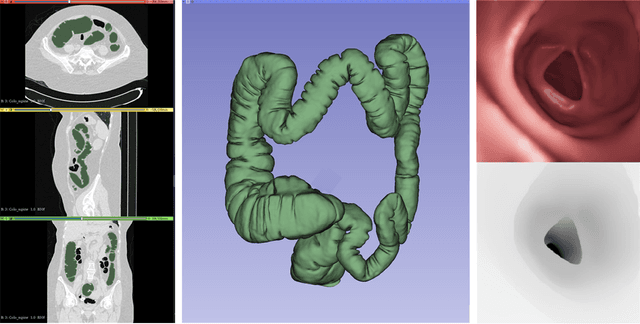

In order to use the navigation system effectively, distance information sensors such as depth sensors are essential. Since depth sensors are difficult to use in endoscopy, many groups propose a method using convolutional neural networks. In this paper, the ground truth of the depth image and the endoscopy image is generated through endoscopy simulation using the colon model segmented by CT colonography. Photo-realistic simulation images can be created using a sim-to-real approach using cycleGAN for endoscopy images. By training the generated dataset, we propose a quantitative endoscopy depth estimation network. The proposed method represents a better-evaluated score than the existing unsupervised training-based results.
Enhancing exploration algorithms for navigation with visual SLAM
Oct 18, 2021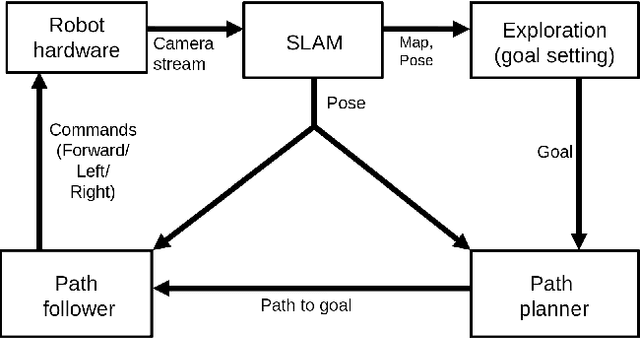
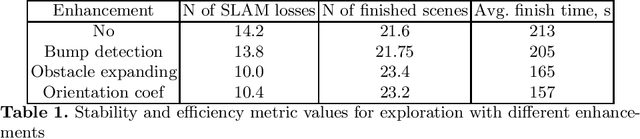
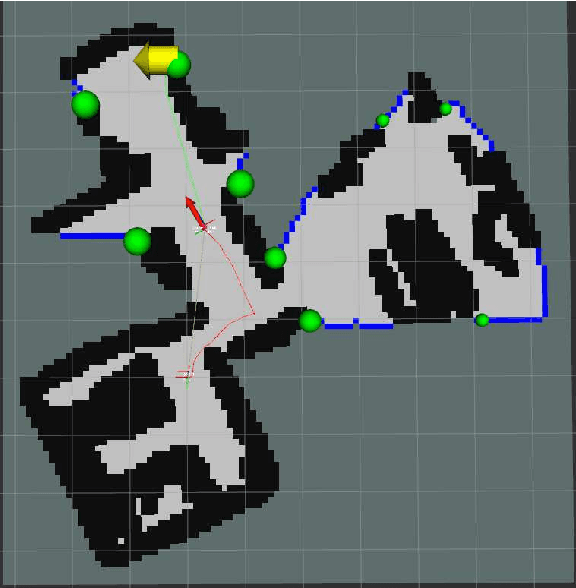
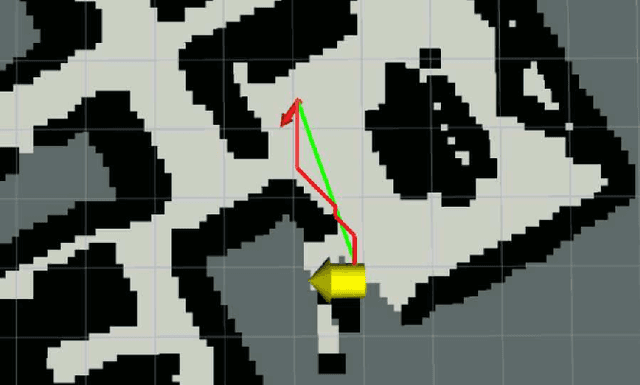
Exploration is an important step in autonomous navigation of robotic systems. In this paper we introduce a series of enhancements for exploration algorithms in order to use them with vision-based simultaneous localization and mapping (vSLAM) methods. We evaluate developed approaches in photo-realistic simulator in two modes: with ground-truth depths and neural network reconstructed depth maps as vSLAM input. We evaluate standard metrics in order to estimate exploration coverage.
Cycle Generative Adversarial Networks Algorithm With Style Transfer For Image Generation
Jan 11, 2021The biggest challenge faced by a Machine Learning Engineer is the lack of data they have, especially for 2-dimensional images. The image is processed to be trained into a Machine Learning model so that it can recognize patterns in the data and provide predictions. This research is intended to create a solution using the Cycle Generative Adversarial Networks (GANs) algorithm in overcoming the problem of lack of data. Then use Style Transfer to be able to generate a new image based on the given style. Based on the results of testing the resulting model has been carried out several improvements, previously the loss value of the photo generator: 3.1267, monet style generator: 3.2026, photo discriminator: 0.6325, and monet style discriminator: 0.6931 to photo generator: 2.3792, monet style generator: 2.7291, photo discriminator: 0.5956, and monet style discriminator: 0.4940. It is hoped that the research will make the application of this solution useful in the fields of Education, Arts, Information Technology, Medicine, Astronomy, Automotive and other important fields.
PRNU Based Source Camera Identification for Webcam and Smartphone Videos
Jan 27, 2022
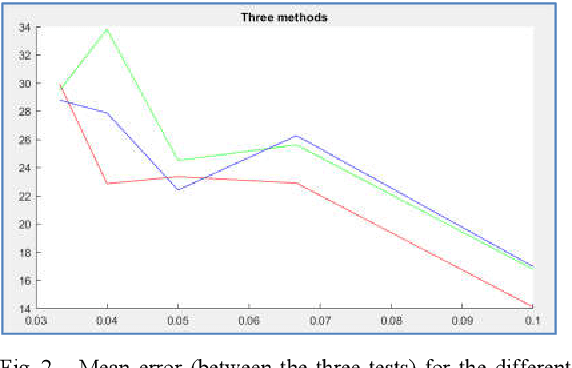


This communication is about an application of image forensics where we use camera sensor fingerprints to identify source camera (SCI: Source Camera Identification) in webcam/smartphone videos. Sensor or camera fingerprints are based on computing the intrinsic noise that is always present in this kind of sensors due to manufacturing imperfections. This is an unavoidable characteristic that links each sensor with its noise pattern. PRNU (Photo Response Non-Uniformity) has become the default technique to compute a camera fingerprint. There are many applications nowadays dealing with PRNU patterns for camera identification using still images. In this work we focus on video, first on webcam video and afterwards on smartphone video. Webcams and smartphones are the most used video cameras nowadays. Three possible methods for SCI are implemented and assessed in this work.