 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoto-realistic Image Super-resolution with Fast and Lightweight Cascading Residual Network
Paper and Code
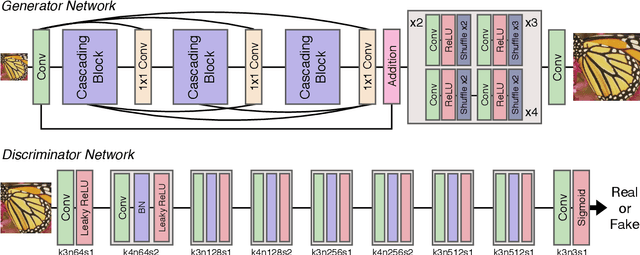
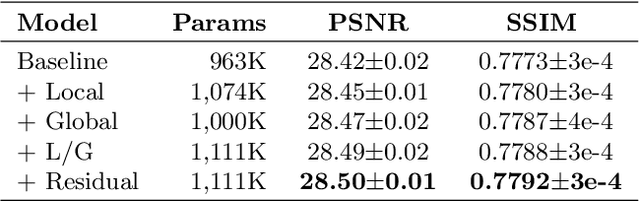
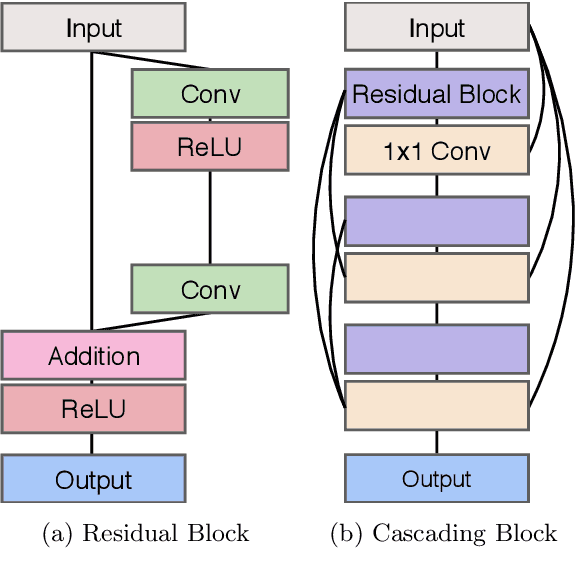

Recent progress in the deep learning-based models has improved single-image super-resolution significantly. However, despite their powerful performance, many models are difficult to apply to the real-world applications because of the heavy computational requirements. To facilitate the use of a deep learning model in such demands, we focus on keeping the model fast and lightweight while maintaining its accuracy. In detail, we design an architecture that implements a cascading mechanism on a residual network to boost the performance with limited resources via multi-level feature fusion. Moreover, we adopt group convolution and weight-tying for our proposed model in order to achieve extreme efficiency. In addition to the traditional super-resolution task, we apply our methods to the photo-realistic super-resolution field using the adversarial learning paradigm and a multi-scale discriminator approach. By doing so, we show that the performances of the proposed models surpass those of the recent methods, which have a complexity similar to ours, for both traditional pixel-based and perception-based tasks.