 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
A Picture May Be Worth a Thousand Lives: An Interpretable Artificial Intelligence Strategy for Predictions of Suicide Risk from Social Media Images
Feb 19, 2023
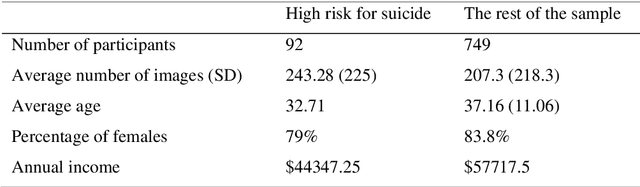
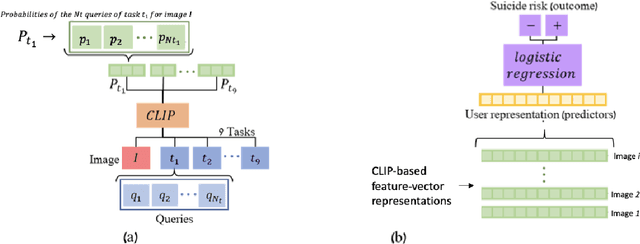
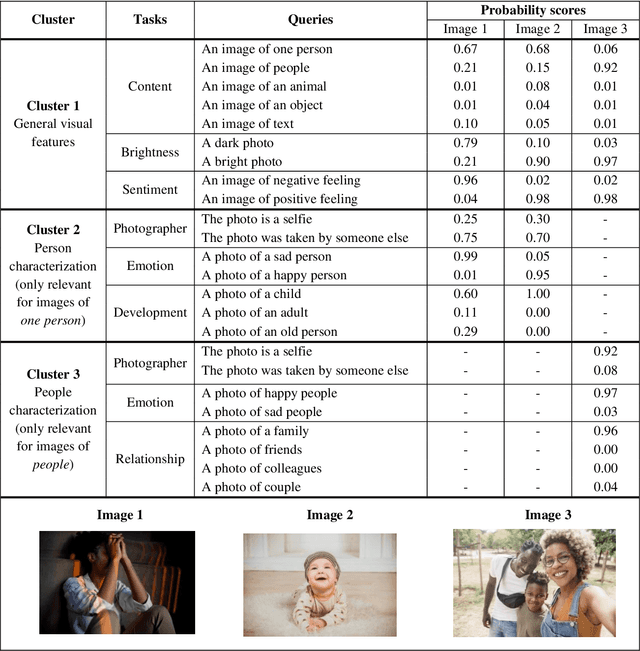

The promising research on Artificial Intelligence usages in suicide prevention has principal gaps, including black box methodologies, inadequate outcome measures, and scarce research on non-verbal inputs, such as social media images (despite their popularity today, in our digital era). This study addresses these gaps and combines theory-driven and bottom-up strategies to construct a hybrid and interpretable prediction model of valid suicide risk from images. The lead hypothesis was that images contain valuable information about emotions and interpersonal relationships, two central concepts in suicide-related treatments and theories. The dataset included 177,220 images by 841 Facebook users who completed a gold-standard suicide scale. The images were represented with CLIP, a state-of-the-art algorithm, which was utilized, unconventionally, to extract predefined features that served as inputs to a simple logistic-regression prediction model (in contrast to complex neural networks). The features addressed basic and theory-driven visual elements using everyday language (e.g., bright photo, photo of sad people). The results of the hybrid model (that integrated theory-driven and bottom-up methods) indicated high prediction performance that surpassed common bottom-up algorithms, thus providing a first proof that images (alone) can be leveraged to predict validated suicide risk. Corresponding with the lead hypothesis, at-risk users had images with increased negative emotions and decreased belonginess. The results are discussed in the context of non-verbal warning signs of suicide. Notably, the study illustrates the advantages of hybrid models in such complicated tasks and provides simple and flexible prediction strategies that could be utilized to develop real-life monitoring tools of suicide.
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Apr 01, 2023
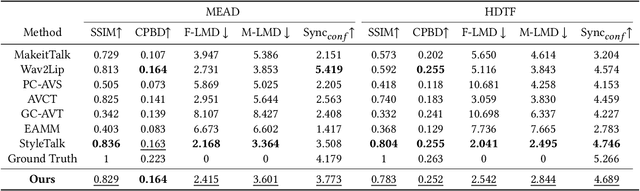
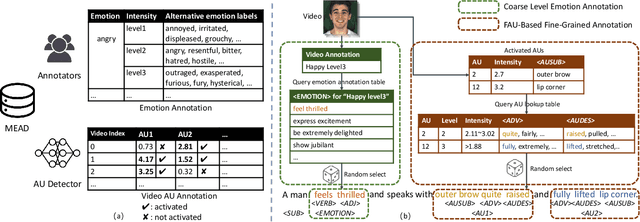
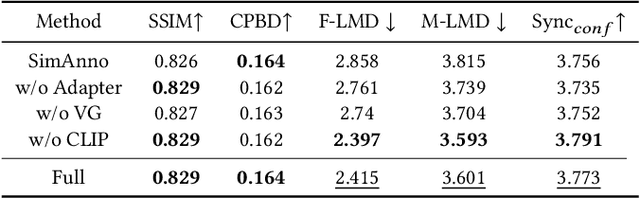
In order to produce facial-expression-specified talking head videos, previous audio-driven one-shot talking head methods need to use a reference video with a matching speaking style (i.e., facial expressions). However, finding videos with a desired style may not be easy, potentially restricting their application. In this work, we propose an expression-controllable one-shot talking head method, dubbed TalkCLIP, where the expression in a speech is specified by the natural language. This would significantly ease the difficulty of searching for a video with a desired speaking style. Here, we first construct a text-video paired talking head dataset, in which each video has alternative prompt-alike descriptions. Specifically, our descriptions involve coarse-level emotion annotations and facial action unit (AU) based fine-grained annotations. Then, we introduce a CLIP-based style encoder that first projects natural language descriptions to the CLIP text embedding space and then aligns the textual embeddings to the representations of speaking styles. As extensive textual knowledge has been encoded by CLIP, our method can even generalize to infer a speaking style whose description has not been seen during training. Extensive experiments demonstrate that our method achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
Biphasic Face Photo-Sketch Synthesis via Semantic-Driven Generative Adversarial Network with Graph Representation Learning
Jan 05, 2022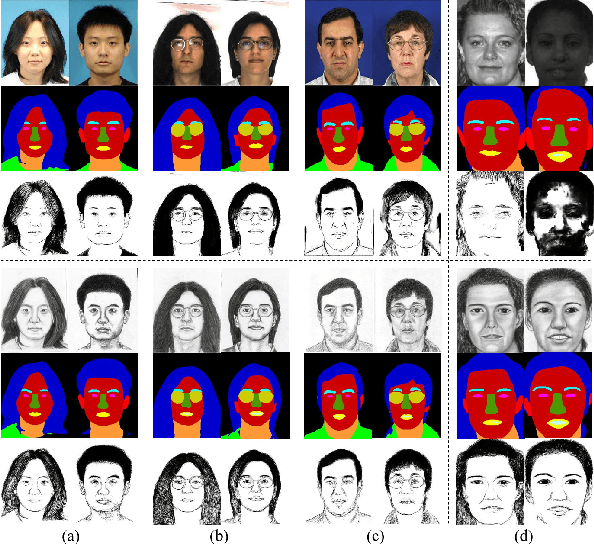
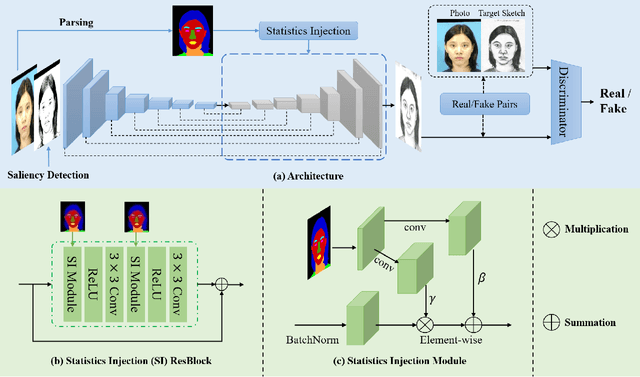
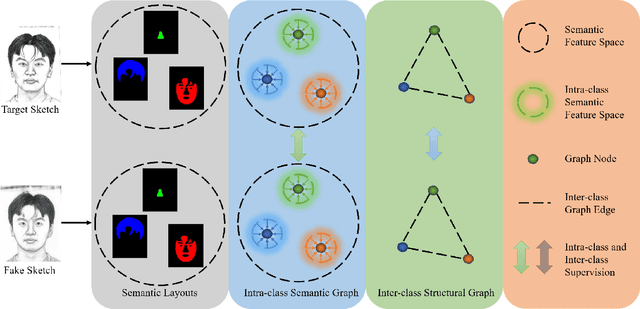
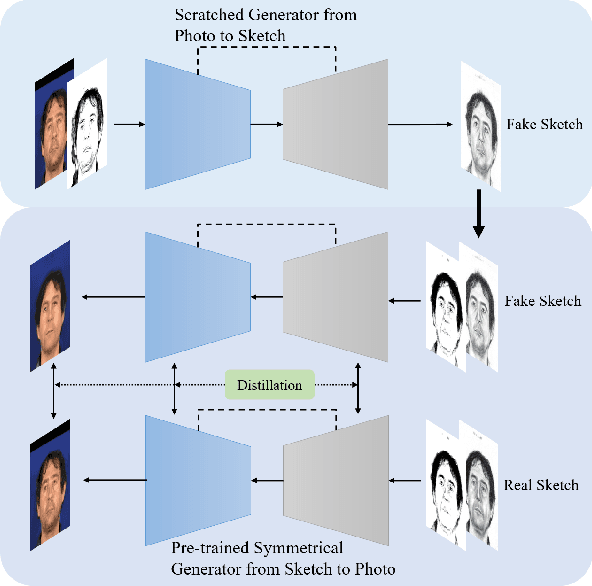
In recent years, significant progress has been achieved in biphasic face photo-sketch synthesis with the development of Generative Adversarial Network (GAN). Biphasic face photo-sketch synthesis could be applied in wide-ranging fields such as digital entertainment and law enforcement. However, generating realistic photos and distinct sketches suffers from great challenges due to the low quality of sketches and complex photo variations in the real scenes. To this end, we propose a novel Semantic-Driven Generative Adversarial Network to address the above issues, cooperating with the Graph Representation Learning. Specifically, we inject class-wise semantic layouts into the generator to provide style-based spatial supervision for synthesized face photos and sketches. In addition, to improve the fidelity of the generated results, we leverage the semantic layouts to construct two types of Representational Graphs which indicate the intra-class semantic features and inter-class structural features of the synthesized images. Furthermore, we design two types of constraints based on the proposed Representational Graphs which facilitate the preservation of the details in generated face photos and sketches. Moreover, to further enhance the perceptual quality of synthesized images, we propose a novel biphasic training strategy which is dedicated to refine the generated results through Iterative Cycle Training. Extensive experiments are conducted on CUFS and CUFSF datasets to demonstrate the prominent ability of our proposed method which achieves the state-of-the-art performance.
Building Multimodal AI Chatbots
Apr 21, 2023
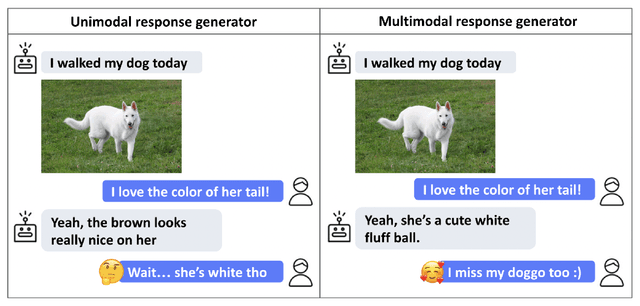
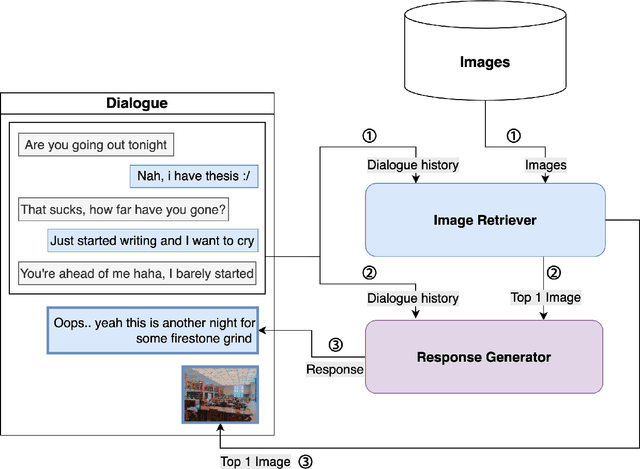
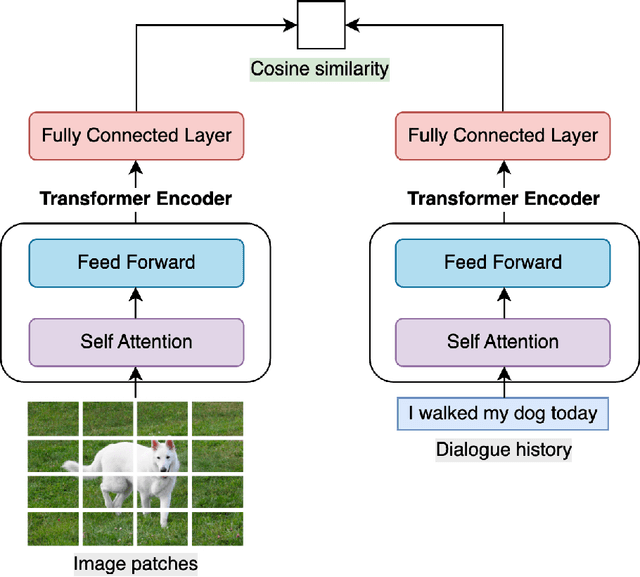
This work aims to create a multimodal AI system that chats with humans and shares relevant photos. While earlier works were limited to dialogues about specific objects or scenes within images, recent works have incorporated images into open-domain dialogues. However, their response generators are unimodal, accepting text input but no image input, thus prone to generating responses contradictory to the images shared in the dialogue. Therefore, this work proposes a complete chatbot system using two multimodal deep learning models: an image retriever that understands texts and a response generator that understands images. The image retriever, implemented by ViT and BERT, selects the most relevant image given the dialogue history and a database of images. The response generator, implemented by ViT and GPT-2/DialoGPT, generates an appropriate response given the dialogue history and the most recently retrieved image. The two models are trained and evaluated on PhotoChat, an open-domain dialogue dataset in which a photo is shared in each session. In automatic evaluation, the proposed image retriever outperforms existing baselines VSE++ and SCAN with Recall@1/5/10 of 0.1/0.3/0.4 and MRR of 0.2 when ranking 1,000 images. The proposed response generator also surpasses the baseline Divter with PPL of 16.9, BLEU-1/2 of 0.13/0.03, and Distinct-1/2 of 0.97/0.86, showing a significant improvement in PPL by -42.8 and BLEU-1/2 by +0.07/0.02. In human evaluation with a Likert scale of 1-5, the complete multimodal chatbot system receives higher image-groundedness of 4.3 and engagingness of 4.3, along with competitive fluency of 4.1, coherence of 3.9, and humanness of 3.1, when compared to other chatbot variants. The source code is available at: https://github.com/minniie/multimodal_chat.git.
Generating Photo-realistic Images from LiDAR Point Clouds with Generative Adversarial Networks
Dec 20, 2021



We examined the feasibility of generative adversarial networks (GANs) to generate photo-realistic images from LiDAR point clouds. For this purpose, we created a dataset of point cloud image pairs and trained the GAN to predict photorealistic images from LiDAR point clouds containing reflectance and distance information. Our models learned how to predict realistically looking images from just point cloud data, even images with black cars. Black cars are difficult to detect directly from point clouds because of their low level of reflectivity. This approach might be used in the future to perform visual object recognition on photorealistic images generated from LiDAR point clouds. In addition to the conventional LiDAR system, a second system that generates photorealistic images from LiDAR point clouds would run simultaneously for visual object recognition in real-time. In this way, we might preserve the supremacy of LiDAR and benefit from using photo-realistic images for visual object recognition without the usage of any camera. In addition, this approach could be used to colorize point clouds without the usage of any camera images.
SINE: Semantic-driven Image-based NeRF Editing with Prior-guided Editing Field
Mar 25, 2023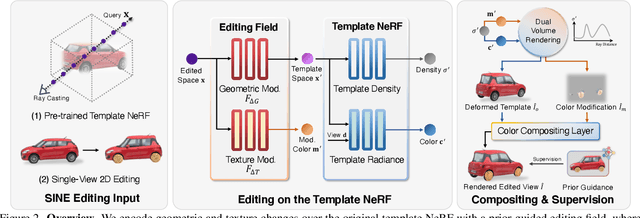
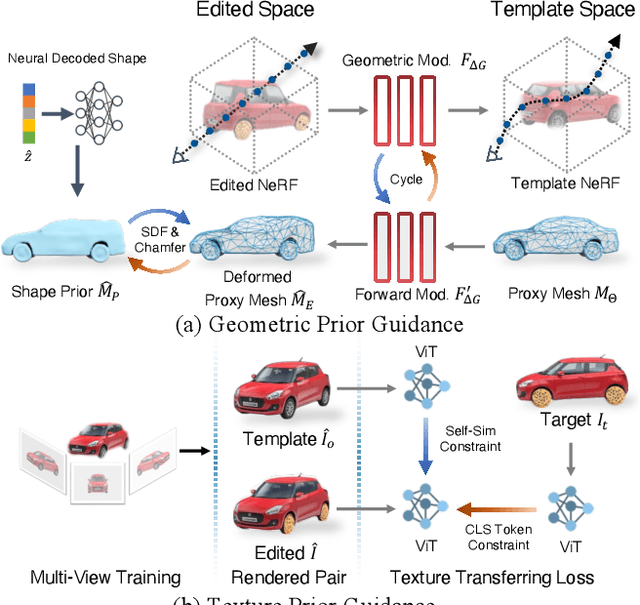
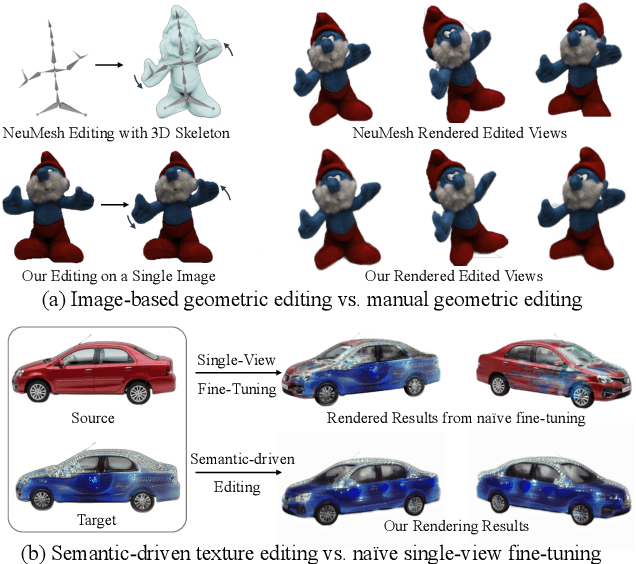
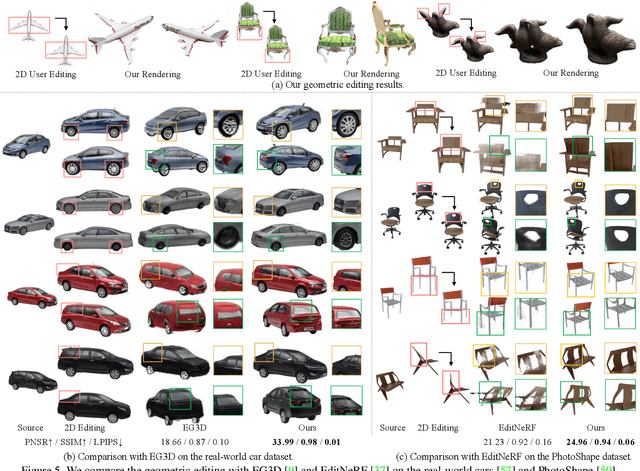
Despite the great success in 2D editing using user-friendly tools, such as Photoshop, semantic strokes, or even text prompts, similar capabilities in 3D areas are still limited, either relying on 3D modeling skills or allowing editing within only a few categories. In this paper, we present a novel semantic-driven NeRF editing approach, which enables users to edit a neural radiance field with a single image, and faithfully delivers edited novel views with high fidelity and multi-view consistency. To achieve this goal, we propose a prior-guided editing field to encode fine-grained geometric and texture editing in 3D space, and develop a series of techniques to aid the editing process, including cyclic constraints with a proxy mesh to facilitate geometric supervision, a color compositing mechanism to stabilize semantic-driven texture editing, and a feature-cluster-based regularization to preserve the irrelevant content unchanged. Extensive experiments and editing examples on both real-world and synthetic data demonstrate that our method achieves photo-realistic 3D editing using only a single edited image, pushing the bound of semantic-driven editing in 3D real-world scenes. Our project webpage: https://zju3dv.github.io/sine/.
Brain Tumor classification and Segmentation using Deep Learning
Apr 16, 2023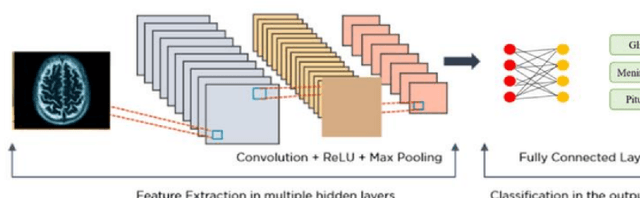
Brain tumors are a complex and potentially life-threatening medical condition that requires accurate diagnosis and timely treatment. In this paper, we present a machine learning-based system designed to assist healthcare professionals in the classification and diagnosis of brain tumors using MRI images. Our system provides a secure login, where doctors can upload or take a photo of MRI and our app can classify the model and segment the tumor, providing the doctor with a folder of each patient's history, name, and results. Our system can also add results or MRI to this folder, draw on the MRI to send it to another doctor, and save important results in a saved page in the app. Furthermore, our system can classify in less than 1 second and allow doctors to chat with a community of brain tumor doctors. To achieve these objectives, our system uses a state-of-the-art machine learning algorithm that has been trained on a large dataset of MRI images. The algorithm can accurately classify different types of brain tumors and provide doctors with detailed information on the size, location, and severity of the tumor. Additionally, our system has several features to ensure its security and privacy, including secure login and data encryption. We evaluated our system using a dataset of real-world MRI images and compared its performance to other existing systems. Our results demonstrate that our system is highly accurate, efficient, and easy to use. We believe that our system has the potential to revolutionize the field of brain tumor diagnosis and treatment and provide healthcare professionals with a powerful tool for improving patient outcomes.
Photo-to-Shape Material Transfer for Diverse Structures
May 09, 2022
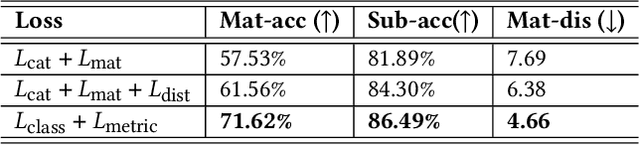
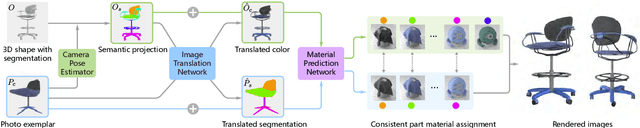
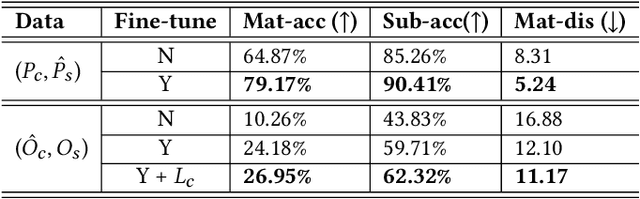
We introduce a method for assigning photorealistic relightable materials to 3D shapes in an automatic manner. Our method takes as input a photo exemplar of a real object and a 3D object with segmentation, and uses the exemplar to guide the assignment of materials to the parts of the shape, so that the appearance of the resulting shape is as similar as possible to the exemplar. To accomplish this goal, our method combines an image translation neural network with a material assignment neural network. The image translation network translates the color from the exemplar to a projection of the 3D shape and the part segmentation from the projection to the exemplar. Then, the material prediction network assigns materials from a collection of realistic materials to the projected parts, based on the translated images and perceptual similarity of the materials. One key idea of our method is to use the translation network to establish a correspondence between the exemplar and shape projection, which allows us to transfer materials between objects with diverse structures. Another key idea of our method is to use the two pairs of (color, segmentation) images provided by the image translation to guide the material assignment, which enables us to ensure the consistency in the assignment. We demonstrate that our method allows us to assign materials to shapes so that their appearances better resemble the input exemplars, improving the quality of the results over the state-of-the-art method, and allowing us to automatically create thousands of shapes with high-quality photorealistic materials. Code and data for this paper are available at https://github.com/XiangyuSu611/TMT.
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 24, 2023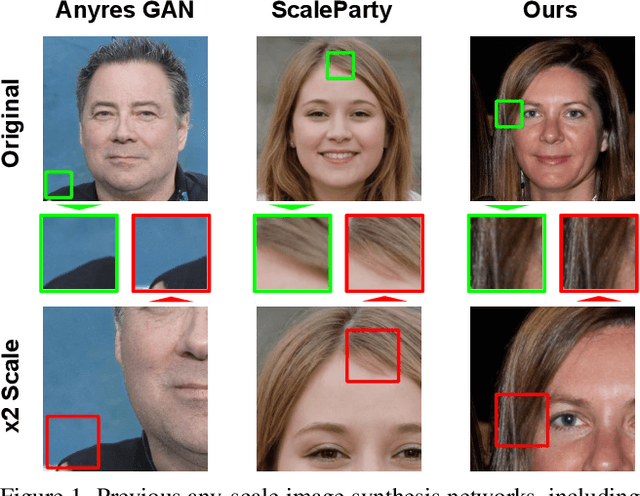
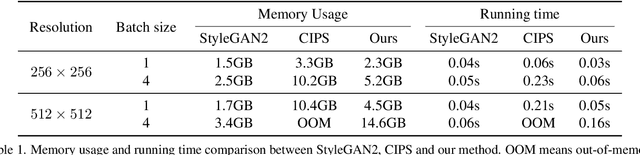
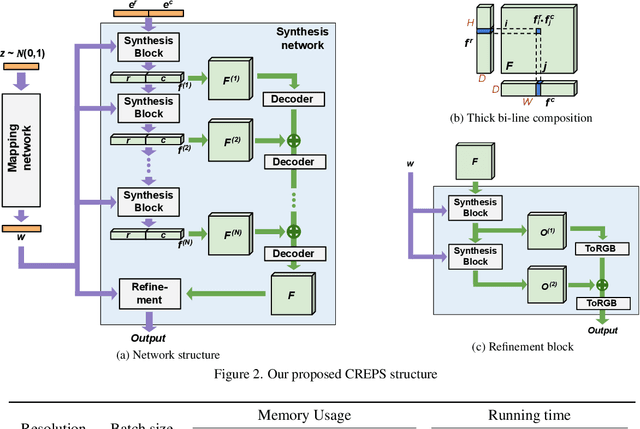

Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.
Signing at Scale: Learning to Co-Articulate Signs for Large-Scale Photo-Realistic Sign Language Production
Mar 29, 2022
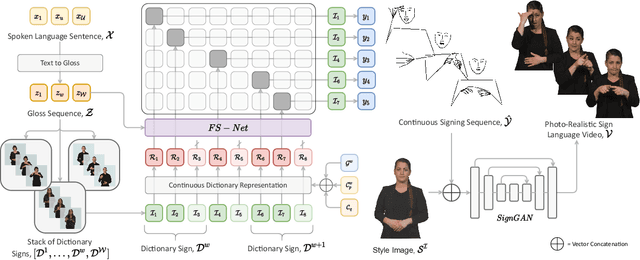
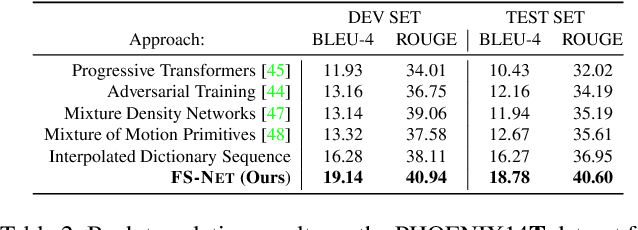
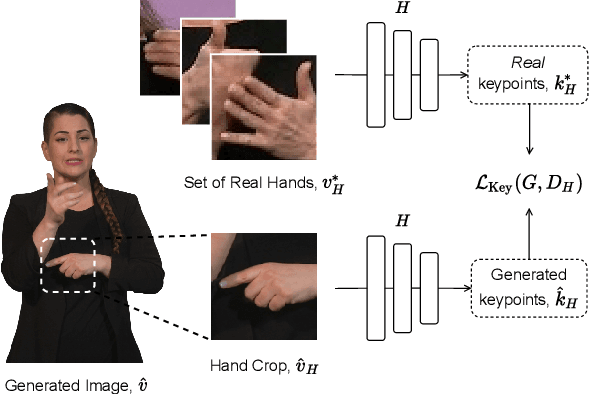
Sign languages are visual languages, with vocabularies as rich as their spoken language counterparts. However, current deep-learning based Sign Language Production (SLP) models produce under-articulated skeleton pose sequences from constrained vocabularies and this limits applicability. To be understandable and accepted by the deaf, an automatic SLP system must be able to generate co-articulated photo-realistic signing sequences for large domains of discourse. In this work, we tackle large-scale SLP by learning to co-articulate between dictionary signs, a method capable of producing smooth signing while scaling to unconstrained domains of discourse. To learn sign co-articulation, we propose a novel Frame Selection Network (FS-Net) that improves the temporal alignment of interpolated dictionary signs to continuous signing sequences. Additionally, we propose SignGAN, a pose-conditioned human synthesis model that produces photo-realistic sign language videos direct from skeleton pose. We propose a novel keypoint-based loss function which improves the quality of synthesized hand images. We evaluate our SLP model on the large-scale meineDGS (mDGS) corpus, conducting extensive user evaluation showing our FS-Net approach improves co-articulation of interpolated dictionary signs. Additionally, we show that SignGAN significantly outperforms all baseline methods for quantitative metrics, human perceptual studies and native deaf signer comprehension.