 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Recent Progress of Face Image Synthesis
Jun 15, 2017




Face synthesis has been a fascinating yet challenging problem in computer vision and machine learning. Its main research effort is to design algorithms to generate photo-realistic face images via given semantic domain. It has been a crucial prepossessing step of main-stream face recognition approaches and an excellent test of AI ability to use complicated probability distributions. In this paper, we provide a comprehensive review of typical face synthesis works that involve traditional methods as well as advanced deep learning approaches. Particularly, Generative Adversarial Net (GAN) is highlighted to generate photo-realistic and identity preserving results. Furthermore, the public available databases and evaluation metrics are introduced in details. We end the review with discussing unsolved difficulties and promising directions for future research.
ReLMoGen: Leveraging Motion Generation in Reinforcement Learning for Mobile Manipulation
Aug 18, 2020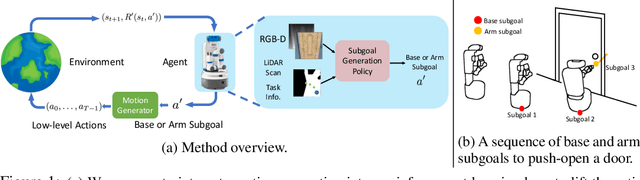
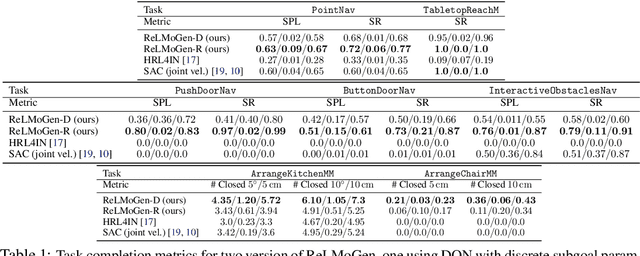
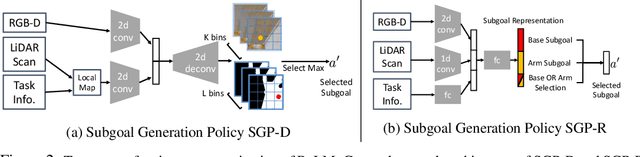

Many Reinforcement Learning (RL) approaches use joint control signals (positions, velocities, torques) as action space for continuous control tasks. We propose to lift the action space to a higher level in the form of subgoals for a motion generator (a combination of motion planner and trajectory executor). We argue that, by lifting the action space and by leveraging sampling-based motion planners, we can efficiently use RL to solve complex, long-horizon tasks that could not be solved with existing RL methods in the original action space. We propose ReLMoGen -- a framework that combines a learned policy to predict subgoals and a motion generator to plan and execute the motion needed to reach these subgoals. To validate our method, we apply ReLMoGen to two types of tasks: 1) Interactive Navigation tasks, navigation problems where interactions with the environment are required to reach the destination, and 2) Mobile Manipulation tasks, manipulation tasks that require moving the robot base. These problems are challenging because they are usually long-horizon, hard to explore during training, and comprise alternating phases of navigation and interaction. Our method is benchmarked on a diverse set of seven robotics tasks in photo-realistic simulation environments. In all settings, ReLMoGen outperforms state-of-the-art Reinforcement Learning and Hierarchical Reinforcement Learning baselines. ReLMoGen also shows outstanding transferability between different motion generators at test time, indicating a great potential to transfer to real robots.
Face Morphing Attack Generation & Detection: A Comprehensive Survey
Nov 03, 2020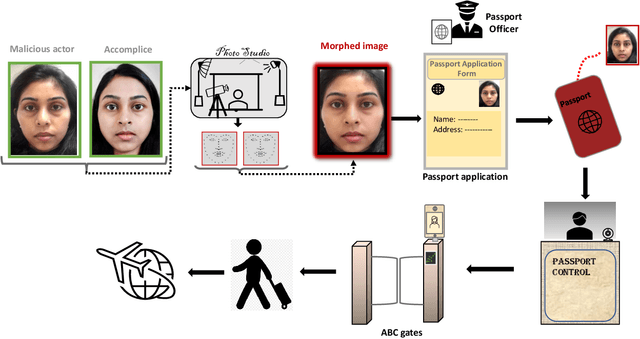

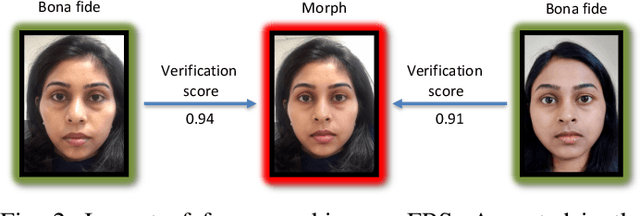
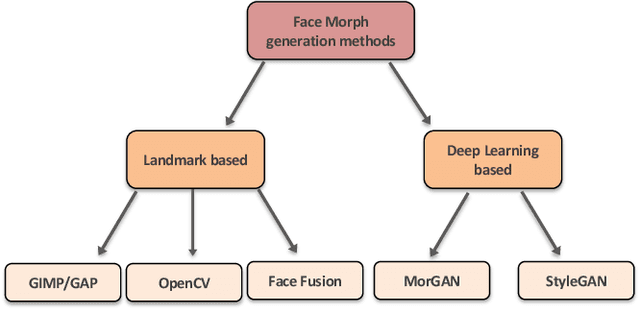
The vulnerability of Face Recognition System (FRS) to various kind of attacks (both direct and in-direct attacks) and face morphing attacks has received a great interest from the biometric community. The goal of a morphing attack is to subvert the FRS at Automatic Border Control (ABC) gates by presenting the Electronic Machine Readable Travel Document (eMRTD) or e-passport that is obtained based on the morphed face image. Since the application process for the e-passport in the majority countries requires a passport photo to be presented by the applicant, a malicious actor and the accomplice can generate the morphed face image and to obtain the e-passport. An e-passport with a morphed face images can be used by both the malicious actor and the accomplice to cross the border as the morphed face image can be verified against both of them. This can result in a significant threat as a malicious actor can cross the border without revealing the track of his/her criminal background while the details of accomplice are recorded in the log of the access control system. This survey aims to present a systematic overview of the progress made in the area of face morphing in terms of both morph generation and morph detection. In this paper, we describe and illustrate various aspects of face morphing attacks, including different techniques for generating morphed face images but also the state-of-the-art regarding Morph Attack Detection (MAD) algorithms based on a stringent taxonomy and finally the availability of public databases, which allow to benchmark new MAD algorithms in a reproducible manner. The outcomes of competitions/benchmarking, vulnerability assessments and performance evaluation metrics are also provided in a comprehensive manner. Furthermore, we discuss the open challenges and potential future works that need to be addressed in this evolving field of biometrics.
On-demand teleradiology using smartphone photographs as proxies for DICOM images
Sep 06, 2019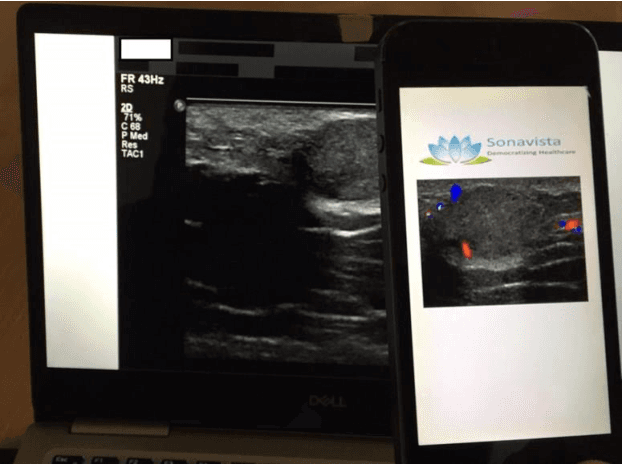
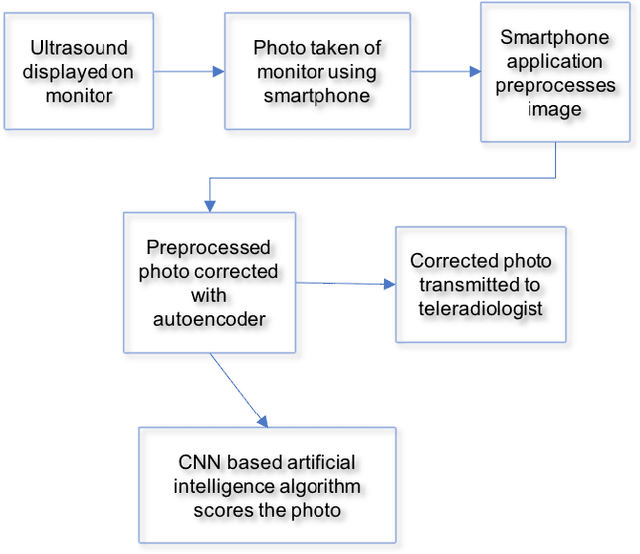
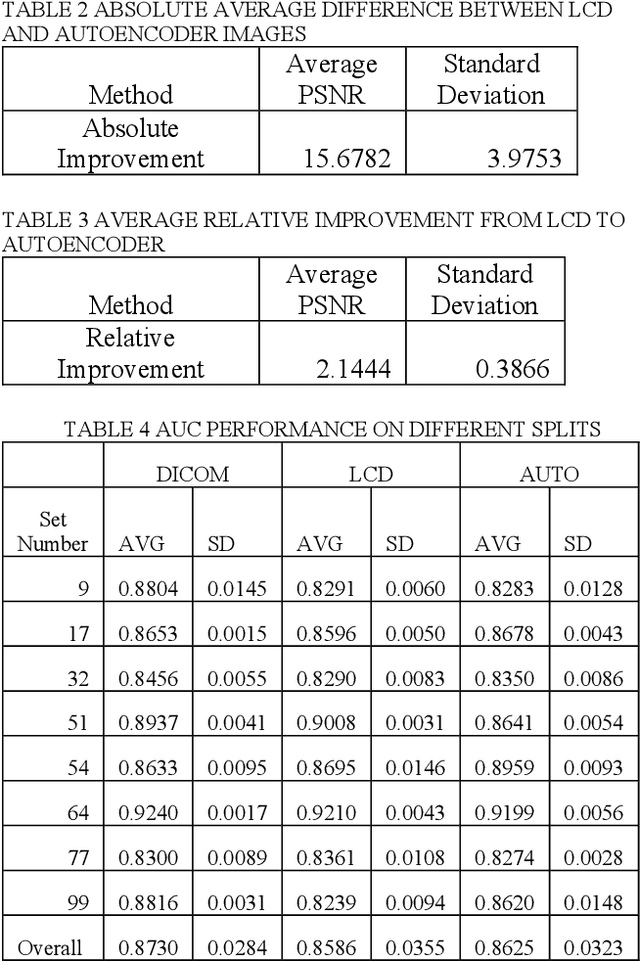
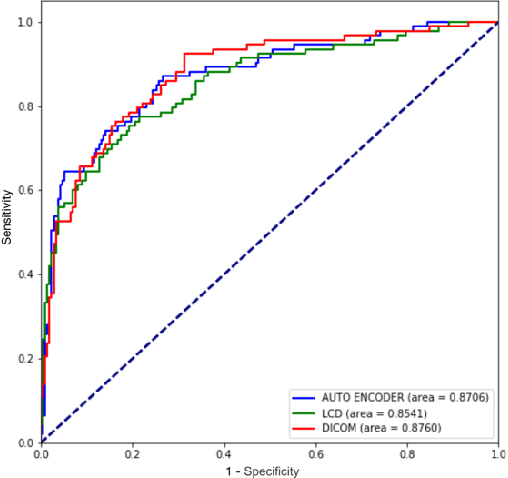
The use of photographs of the screen of displayed medical images is explored to circumvent the challenges involved in transferring images between sites. The photographs can be conveniently taken with a smartphone and analyzed remotely by either human or AI experts. An autoencoder preprocessor is shown to improve the performance for human experts. The AI performance provided by photographs is shown to be statistically equivalent to using the original DICOM images. The autoencoder preprocessor increases the PSNR by 15 dB or greater and provides an AUC that is statistically equivalent to using the original DICOM images. The photo approach is an alternative to IHE-based teleradiology applications while avoiding the problems inherit in navigating the proprietary and security barriers that limit DICOM communication between PACS in practice.
FACSIMILE: Fast and Accurate Scans From an Image in Less Than a Second
Sep 02, 2019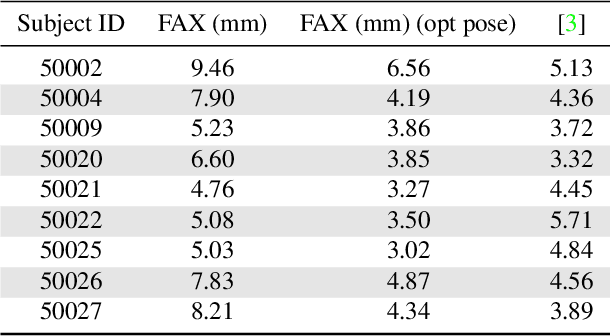
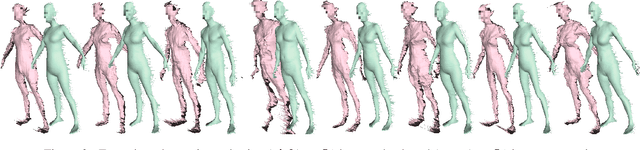
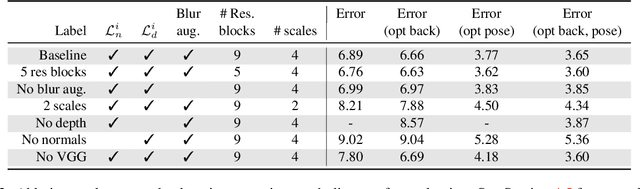
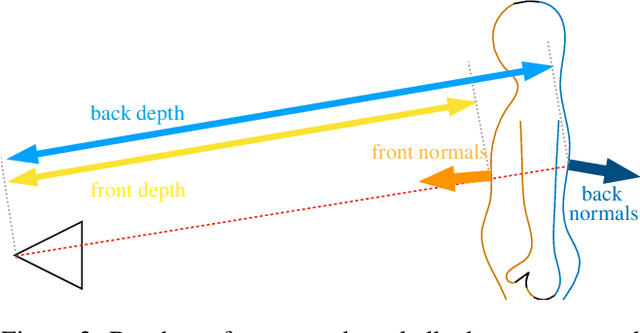
Current methods for body shape estimation either lack detail or require many images. They are usually architecturally complex and computationally expensive. We propose FACSIMILE (FAX), a method that estimates a detailed body from a single photo, lowering the bar for creating virtual representations of humans. Our approach is easy to implement and fast to execute, making it easily deployable. FAX uses an image-translation network which recovers geometry at the original resolution of the image. Counterintuitively, the main loss which drives FAX is on per-pixel surface normals instead of per-pixel depth, making it possible to estimate detailed body geometry without any depth supervision. We evaluate our approach both qualitatively and quantitatively, and compare with a state-of-the-art method.
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
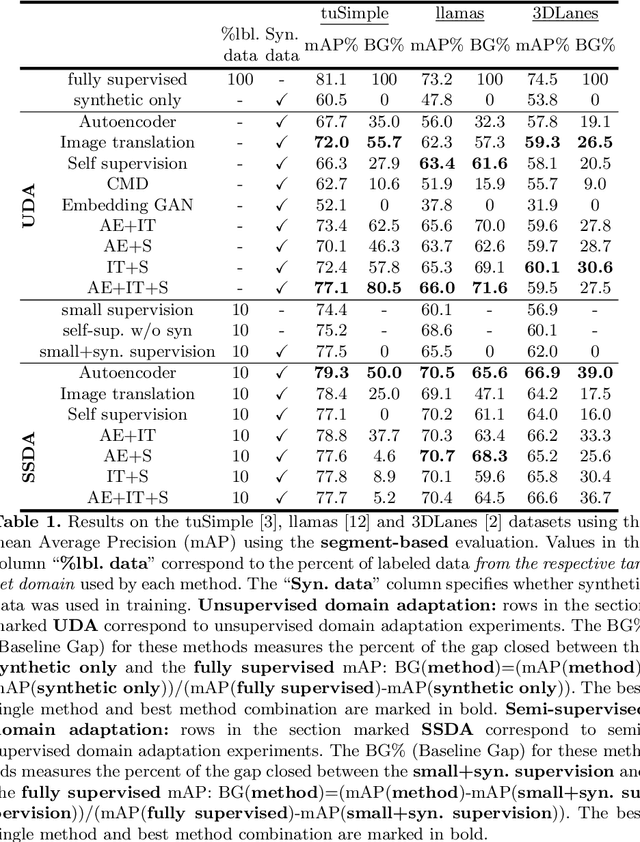
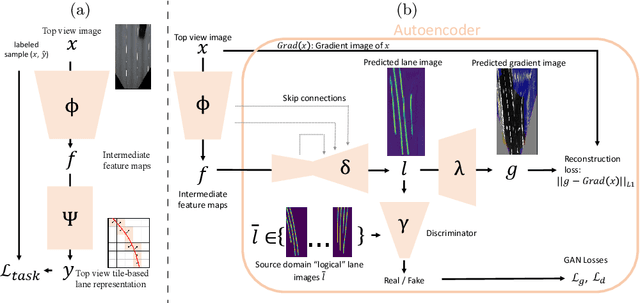
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.
An Approach: Modality Reduction and Face-Sketch Recognition
Dec 05, 2013
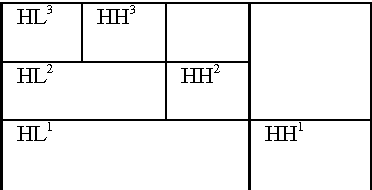
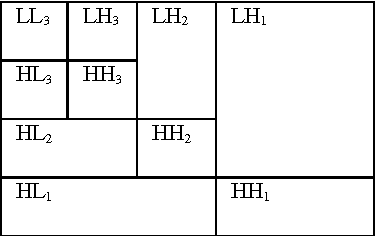
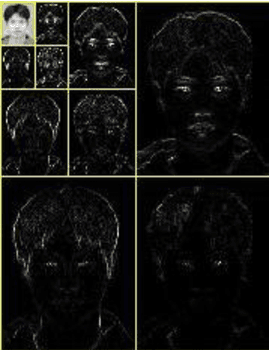
To recognize face sketch through face photo database is a challenging task for todays researchers. Because face photo images in training set and face sketch images in testing set have different modality. Difference between two face photos of difference person is smaller than the difference between same person in a face photo and face sketched. In this paper, for reduction of the modality between face photo and face sketch we first bring face photo and face sketch images in a new dimension using 2D Discrete Haar wavelet transform with scale 3 followed by a negative approach. After that, extract features from transformed images using Principal Component Analysis (PCA). Thereafter, we use SVM classifier and K-NN classifier for better classification. Our proposed method is experimentally verified by its robustness against faces that are captured in a good lighting condition and in a frontal pose. The experiment has been conducted with 100 male and female face images as training set and 100 male and female face sketch images as testing set collected from CUHK training and testing cropped photos and CUHK training and testing cropped sketches.
* 7 pages. arXiv admin note: substantial text overlap with arXiv:1312.1462
Inverse Graphics GAN: Learning to Generate 3D Shapes from Unstructured 2D Data
Feb 28, 2020

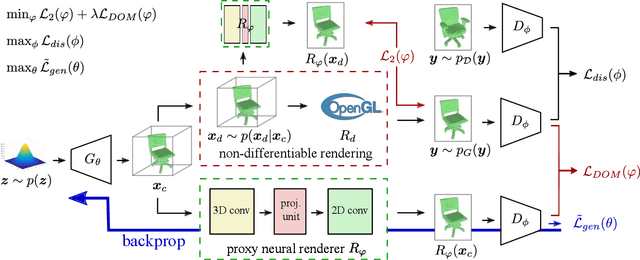

Recent work has shown the ability to learn generative models for 3D shapes from only unstructured 2D images. However, training such models requires differentiating through the rasterization step of the rendering process, therefore past work has focused on developing bespoke rendering models which smooth over this non-differentiable process in various ways. Such models are thus unable to take advantage of the photo-realistic, fully featured, industrial renderers built by the gaming and graphics industry. In this paper we introduce the first scalable training technique for 3D generative models from 2D data which utilizes an off-the-shelf non-differentiable renderer. To account for the non-differentiability, we introduce a proxy neural renderer to match the output of the non-differentiable renderer. We further propose discriminator output matching to ensure that the neural renderer learns to smooth over the rasterization appropriately. We evaluate our model on images rendered from our generated 3D shapes, and show that our model can consistently learn to generate better shapes than existing models when trained with exclusively unstructured 2D images.
Learning Deep Sketch Abstraction
Apr 13, 2018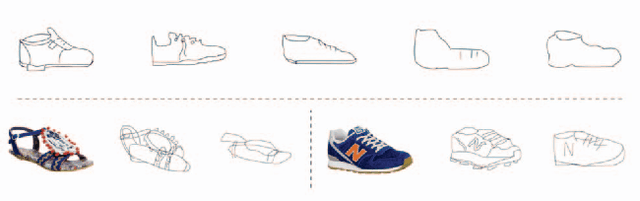
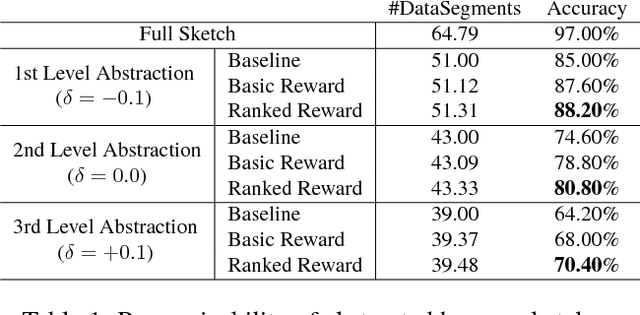
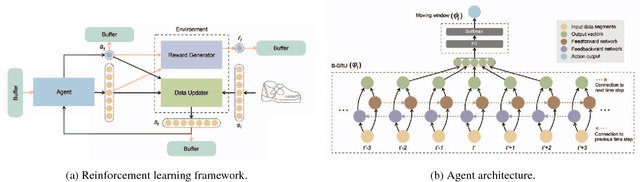
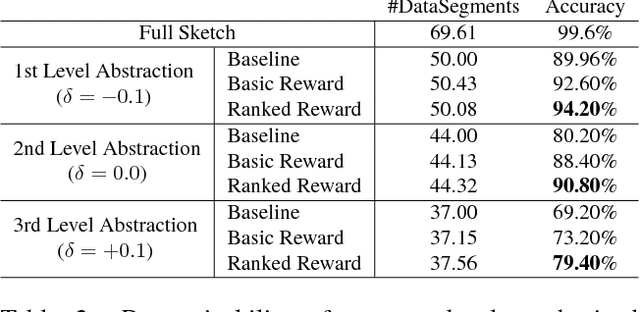
Human free-hand sketches have been studied in various contexts including sketch recognition, synthesis and fine-grained sketch-based image retrieval (FG-SBIR). A fundamental challenge for sketch analysis is to deal with drastically different human drawing styles, particularly in terms of abstraction level. In this work, we propose the first stroke-level sketch abstraction model based on the insight of sketch abstraction as a process of trading off between the recognizability of a sketch and the number of strokes used to draw it. Concretely, we train a model for abstract sketch generation through reinforcement learning of a stroke removal policy that learns to predict which strokes can be safely removed without affecting recognizability. We show that our abstraction model can be used for various sketch analysis tasks including: (1) modeling stroke saliency and understanding the decision of sketch recognition models, (2) synthesizing sketches of variable abstraction for a given category, or reference object instance in a photo, and (3) training a FG-SBIR model with photos only, bypassing the expensive photo-sketch pair collection step.
Person Recognition in Personal Photo Collections
Sep 25, 2015


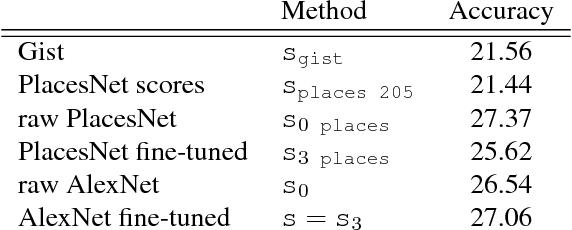
Recognising persons in everyday photos presents major challenges (occluded faces, different clothing, locations, etc.) for machine vision. We propose a convnet based person recognition system on which we provide an in-depth analysis of informativeness of different body cues, impact of training data, and the common failure modes of the system. In addition, we discuss the limitations of existing benchmarks and propose more challenging ones. Our method is simple and is built on open source and open data, yet it improves the state of the art results on a large dataset of social media photos (PIPA).