 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplatent: Splatting Diffusion Latents for Novel View Synthesis
Dec 10, 2025Radiance field representations have recently been explored in the latent space of VAEs that are commonly used by diffusion models. This direction offers efficient rendering and seamless integration with diffusion-based pipelines. However, these methods face a fundamental limitation: The VAE latent space lacks multi-view consistency, leading to blurred textures and missing details during 3D reconstruction. Existing approaches attempt to address this by fine-tuning the VAE, at the cost of reconstruction quality, or by relying on pre-trained diffusion models to recover fine-grained details, at the risk of some hallucinations. We present Splatent, a diffusion-based enhancement framework designed to operate on top of 3D Gaussian Splatting (3DGS) in the latent space of VAEs. Our key insight departs from the conventional 3D-centric view: rather than reconstructing fine-grained details in 3D space, we recover them in 2D from input views through multi-view attention mechanisms. This approach preserves the reconstruction quality of pretrained VAEs while achieving faithful detail recovery. Evaluated across multiple benchmarks, Splatent establishes a new state-of-the-art for VAE latent radiance field reconstruction. We further demonstrate that integrating our method with existing feed-forward frameworks, consistently improves detail preservation, opening new possibilities for high-quality sparse-view 3D reconstruction.
3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
Nov 04, 2020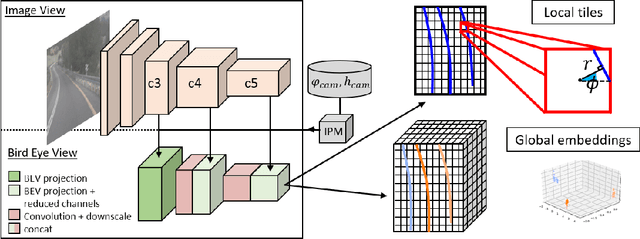

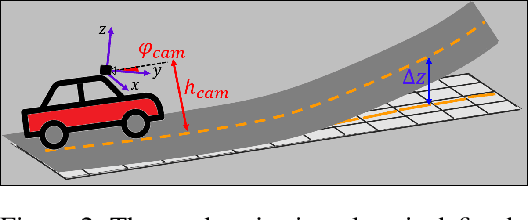
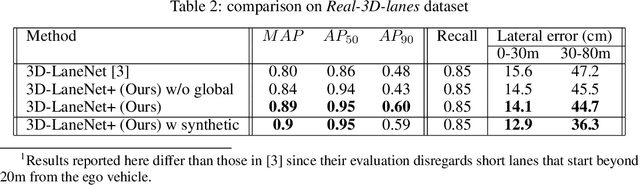
3D-LaneNet+ is a camera-based DNN method for anchor free 3D lane detection which is able to detect 3d lanes of any arbitrary topology such as splits, merges, as well as short and perpendicular lanes. We follow recently proposed 3D-LaneNet, and extend it to enable the detection of these previously unsupported lane topologies. Our output representation is an anchor free, semi-local tile representation that breaks down lanes into simple lane segments whose parameters can be learnt. In addition we learn, per lane instance, feature embedding that reasons for the global connectivity of locally detected segments to form full 3d lanes. This combination allows 3D-LaneNet+ to avoid using lane anchors, non-maximum suppression, and lane model fitting as in the original 3D-LaneNet. We demonstrate the efficacy of 3D-LaneNet+ using both synthetic and real world data. Results show significant improvement relative to the original 3D-LaneNet that can be attributed to better generalization to complex lane topologies, curvatures and surface geometries.
* arXiv admin note: substantial text overlap with arXiv:2003.05257
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
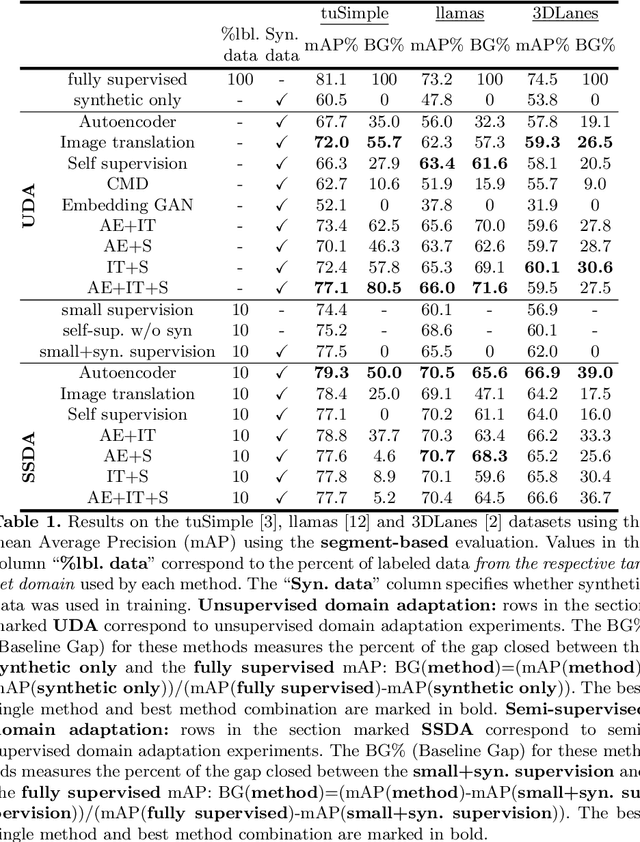
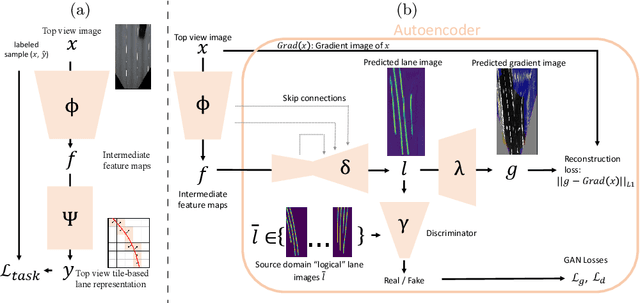
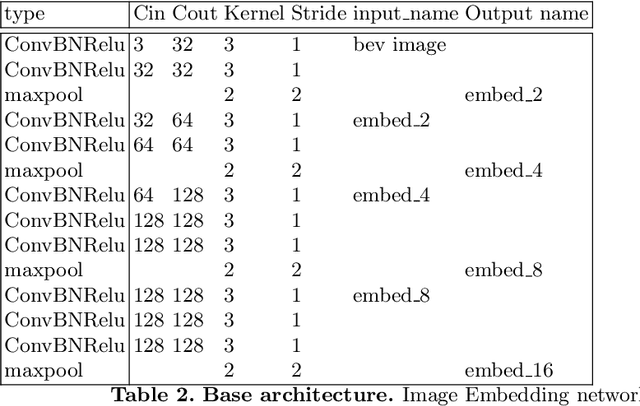
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.
Semi-Local 3D Lane Detection and Uncertainty Estimation
Mar 11, 2020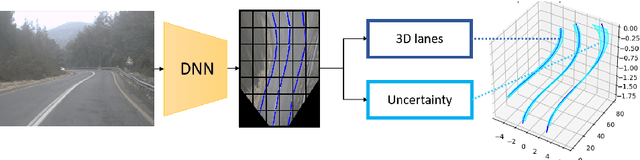
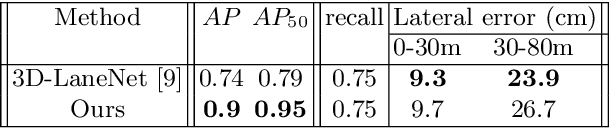
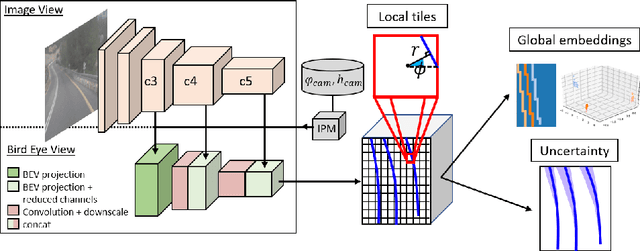
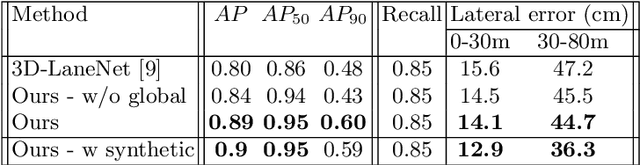
We propose a novel camera-based DNN method for 3D lane detection with uncertainty estimation. Our method is based on a semi-local, BEV, tile representation that breaks down lanes into simple lane segments. It combines learning a parametric model for the segments along with a deep feature embedding that is then used to cluster segment together into full lanes. This combination allows our method to generalize to complex lane topologies, curvatures and surface geometries. Additionally, our method is the first to output a learning based uncertainty estimation for the lane detection task. The efficacy of our method is demonstrated in extensive experiments achieving state-of-the-art results for camera-based 3D lane detection, while also showing our ability to generalize to complex topologies, curvatures and road geometries as well as to different cameras. We also demonstrate how our uncertainty estimation aligns with the empirical error statistics indicating that it is well calibrated and truly reflects the detection noise.