 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
An Automatic Reader of Identity Documents
Jun 26, 2020

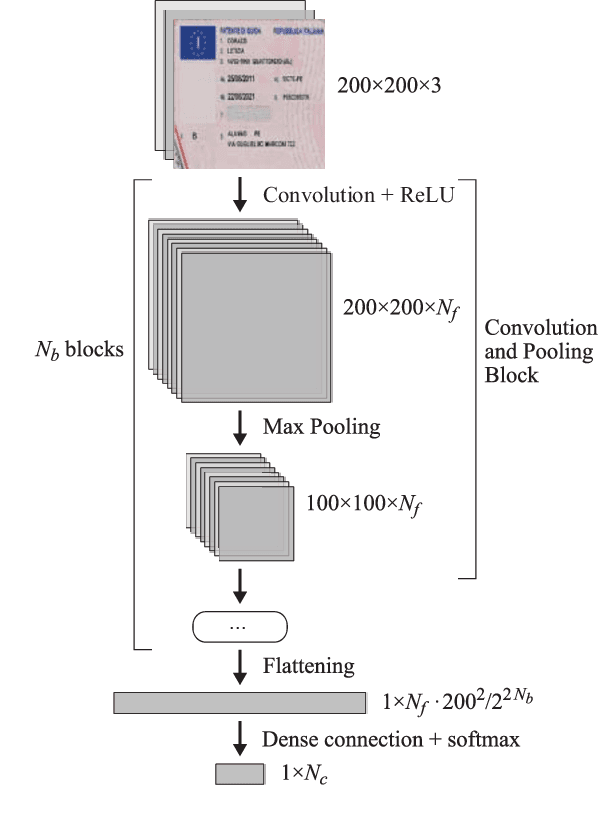


Identity documents automatic reading and verification is an appealing technology for nowadays service industry, since this task is still mostly performed manually, leading to waste of economic and time resources. In this paper the prototype of a novel automatic reading system of identity documents is presented. The system has been thought to extract data of the main Italian identity documents from photographs of acceptable quality, like those usually required to online subscribers of various services. The document is first localized inside the photo, and then classified; finally, text recognition is executed. A synthetic dataset has been used, both for neural networks training, and for performance evaluation of the system. The synthetic dataset avoided privacy issues linked to the use of real photos of real documents, which will be used, instead, for future developments of the system.
Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network
Dec 30, 2020


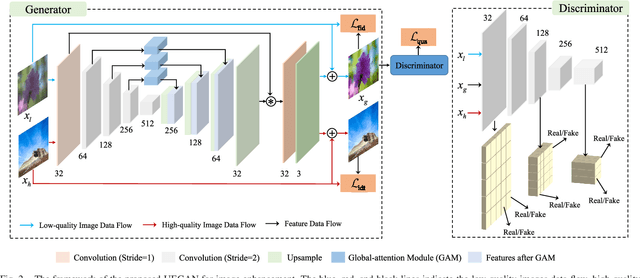
Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert-retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features. Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss, which is defined as a L2 regularization in the feature domain of a pre-trained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.
Deferred Neural Rendering: Image Synthesis using Neural Textures
Apr 28, 2019

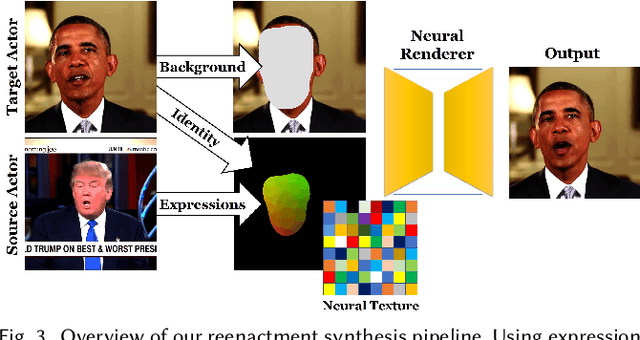
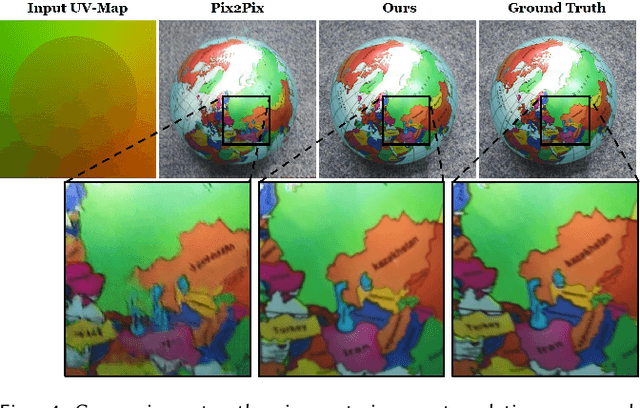
The modern computer graphics pipeline can synthesize images at remarkable visual quality; however, it requires well-defined, high-quality 3D content as input. In this work, we explore the use of imperfect 3D content, for instance, obtained from photo-metric reconstructions with noisy and incomplete surface geometry, while still aiming to produce photo-realistic (re-)renderings. To address this challenging problem, we introduce Deferred Neural Rendering, a new paradigm for image synthesis that combines the traditional graphics pipeline with learnable components. Specifically, we propose Neural Textures, which are learned feature maps that are trained as part of the scene capture process. Similar to traditional textures, neural textures are stored as maps on top of 3D mesh proxies; however, the high-dimensional feature maps contain significantly more information, which can be interpreted by our new deferred neural rendering pipeline. Both neural textures and deferred neural renderer are trained end-to-end, enabling us to synthesize photo-realistic images even when the original 3D content was imperfect. In contrast to traditional, black-box 2D generative neural networks, our 3D representation gives us explicit control over the generated output, and allows for a wide range of application domains. For instance, we can synthesize temporally-consistent video re-renderings of recorded 3D scenes as our representation is inherently embedded in 3D space. This way, neural textures can be utilized to coherently re-render or manipulate existing video content in both static and dynamic environments at real-time rates. We show the effectiveness of our approach in several experiments on novel view synthesis, scene editing, and facial reenactment, and compare to state-of-the-art approaches that leverage the standard graphics pipeline as well as conventional generative neural networks.
Consistency Guided Scene Flow Estimation
Jun 19, 2020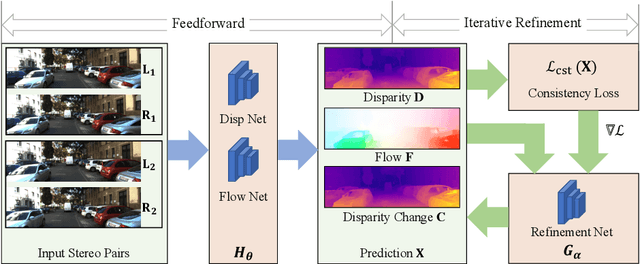


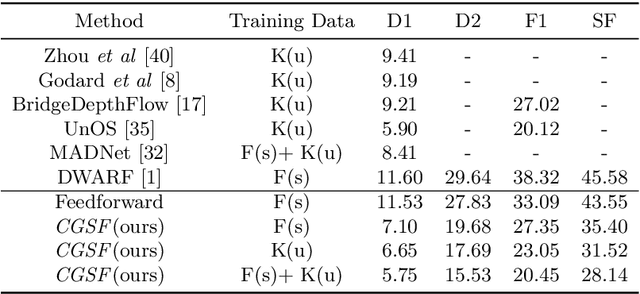
We present Consistency Guided Scene Flow Estimation (CGSF), a framework for joint estimation of 3D scene structure and motion from stereo videos. The model takes two temporal stereo pairs as input, and predicts disparity and scene flow. The model self-adapts at test time by iteratively refining its predictions. The refinement process is guided by a consistency loss, which combines stereo and temporal photo-consistency with a geometric term that couples the disparity and 3D motion. To handle the noise in the consistency loss, we further propose a learned, output refinement network, which takes the initial predictions, the loss, and the gradient as input, and efficiently predicts a correlated output update. We demonstrate with extensive experiments that the proposed model can reliably predict disparity and scene flow in many challenging scenarios, and achieves better generalization than the state-of-the-arts.
Fashion is Taking Shape: Understanding Clothing Preference Based on Body Shape From Online Sources
Jul 09, 2018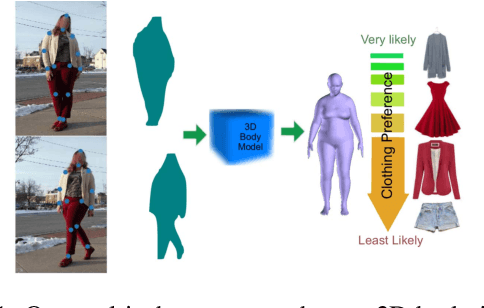
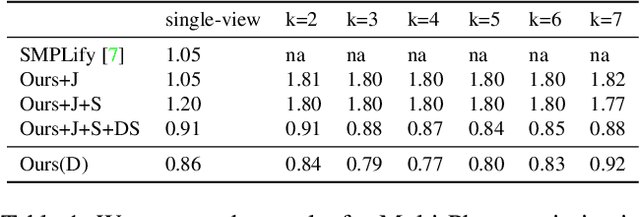
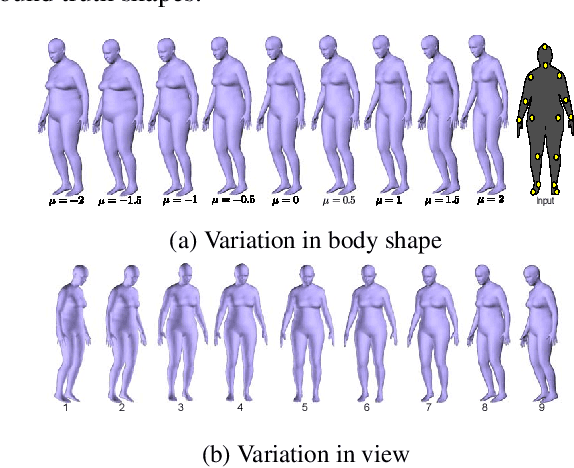
To study the correlation between clothing garments and body shape, we collected a new dataset (Fashion Takes Shape), which includes images of users with clothing category annotations. We employ our multi-photo approach to estimate body shapes of each user and build a conditional model of clothing categories given body-shape. We demonstrate that in real-world data, clothing categories and body-shapes are correlated and show that our multi-photo approach leads to a better predictive model for clothing categories compared to models based on single-view shape estimates or manually annotated body types. We see our method as the first step towards the large-scale understanding of clothing preferences from body shape.
Deep View Synthesis via Self-Consistent Generative Network
Jan 19, 2021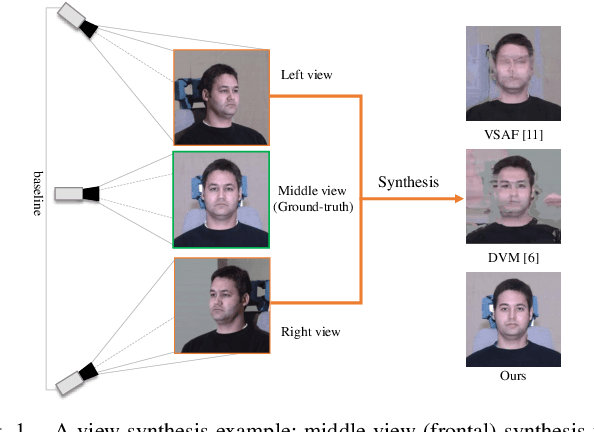



View synthesis aims to produce unseen views from a set of views captured by two or more cameras at different positions. This task is non-trivial since it is hard to conduct pixel-level matching among different views. To address this issue, most existing methods seek to exploit the geometric information to match pixels. However, when the distinct cameras have a large baseline (i.e., far away from each other), severe geometry distortion issues would occur and the geometric information may fail to provide useful guidance, resulting in very blurry synthesized images. To address the above issues, in this paper, we propose a novel deep generative model, called Self-Consistent Generative Network (SCGN), which synthesizes novel views from the given input views without explicitly exploiting the geometric information. The proposed SCGN model consists of two main components, i.e., a View Synthesis Network (VSN) and a View Decomposition Network (VDN), both employing an Encoder-Decoder structure. Here, the VDN seeks to reconstruct input views from the synthesized novel view to preserve the consistency of view synthesis. Thanks to VDN, SCGN is able to synthesize novel views without using any geometric rectification before encoding, making it easier for both training and applications. Finally, adversarial loss is introduced to improve the photo-realism of novel views. Both qualitative and quantitative comparisons against several state-of-the-art methods on two benchmark tasks demonstrated the superiority of our approach.
PAT image reconstruction using augmented sparsity regularization with semi-automated tuning of regularization weight
Mar 24, 2021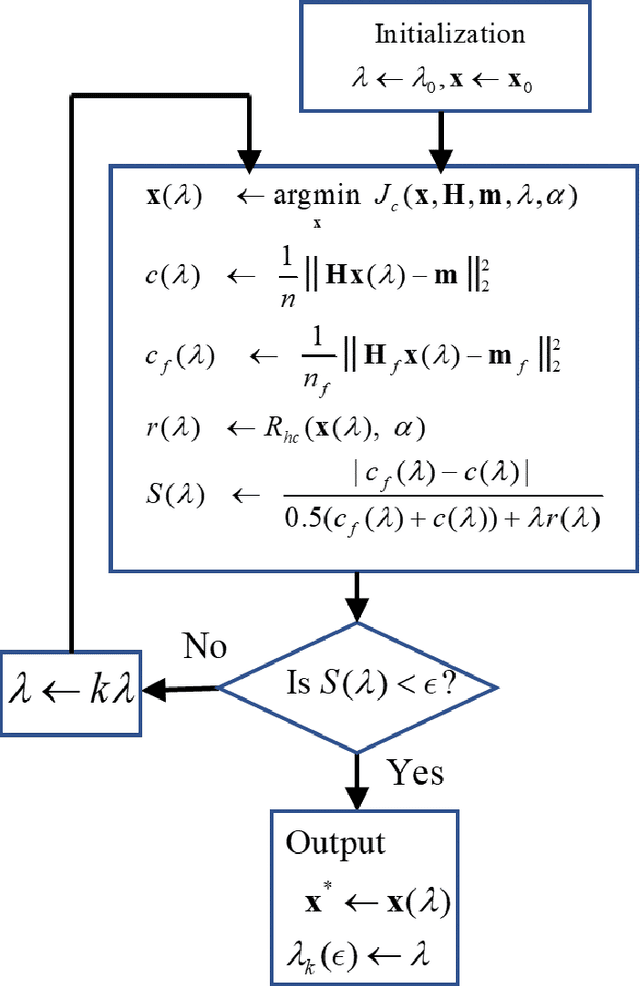
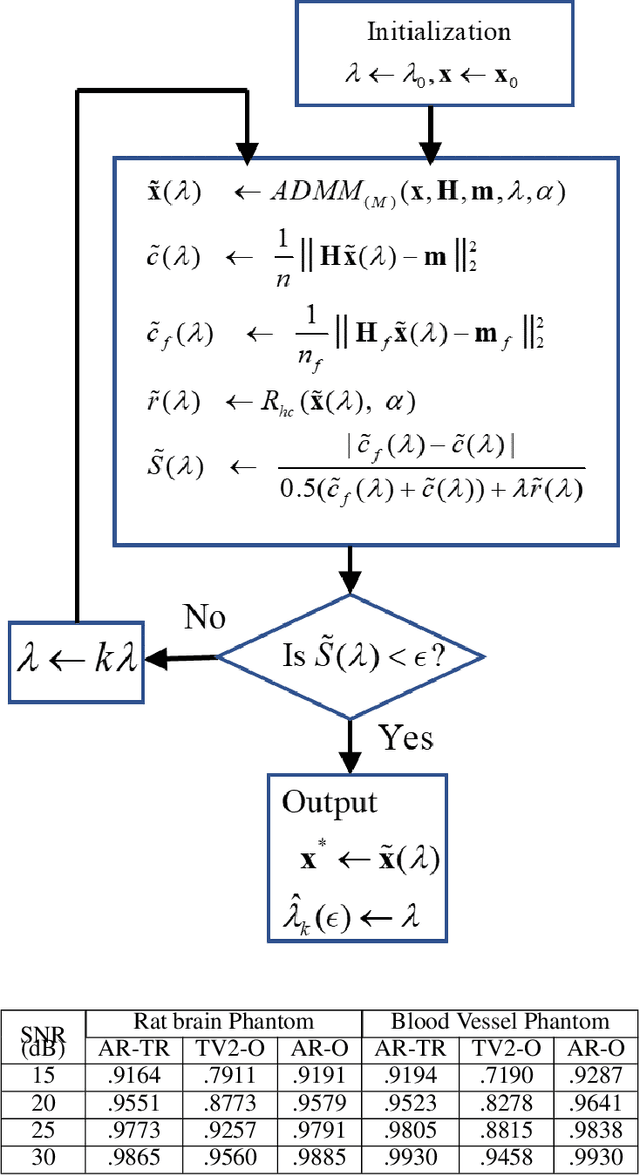
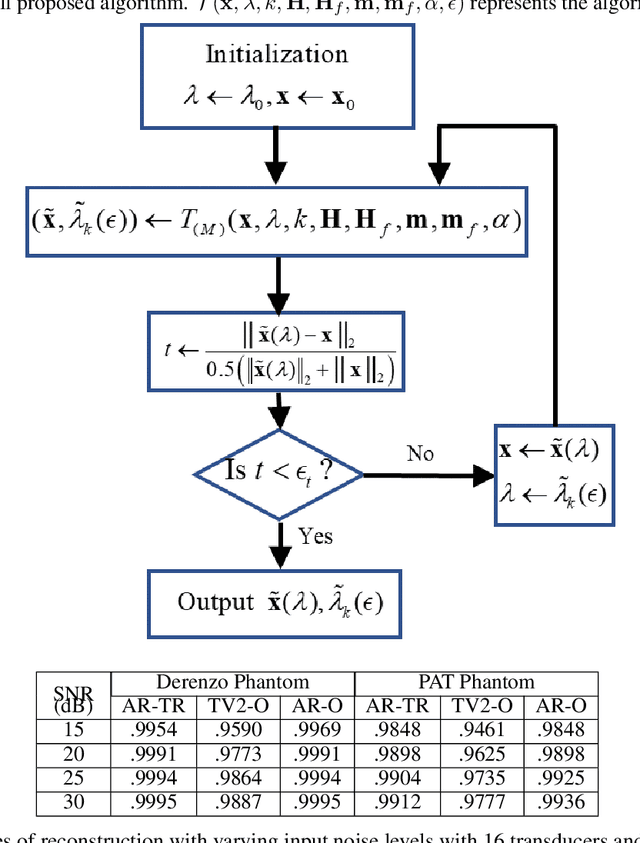
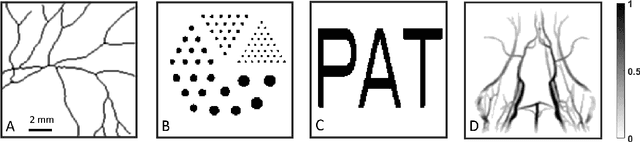
Among all tissue imaging modalities, photo-acoustic tomography (PAT) has been getting increasing attention in the recent past due to the fact that it has high contrast, high penetrability, and has capability of retrieving high resolution. The reconstruction methods used in PAT plays a crucial role in the applicability of PAT, and PAT finds particularly a wider applicability if a model-based regularized reconstruction method is used. A crucial factor that determines the quality of reconstruction in such methods is the choice of regularization weight. Unfortunately, an appropriately tuned value of regularization weight varies significantly with variation in the noise level, as well as, with the variation in the high resolution contents of the image, in a way that has not been well understood. There has been attempts to determine optimum regularization weight from the measured data in the context of using elementary and general purpose regularizations. In this paper, we develop a method for semi-automated tuning of the regularization weight in the context of using a modern type of regularization that was specifically designed for PAT image reconstruction. As a first step, we introduce a relative smoothness constraint with a parameter; this parameter computationally maps into the actual regularization weight, but, its tuning does not vary significantly with variation in the noise level, and with the variation in the high resolution contents of the image. Next, we construct an algorithm that integrates the task of determining this mapping along with obtaining the reconstruction. Finally we demonstrate experimentally that we can run this algorithm with a nominal value of the relative smoothness parameter -- a value independent of the noise level and the structure of the underlying image -- to obtain good quality reconstructions.
Learning About Objects by Learning to Interact with Them
Jun 16, 2020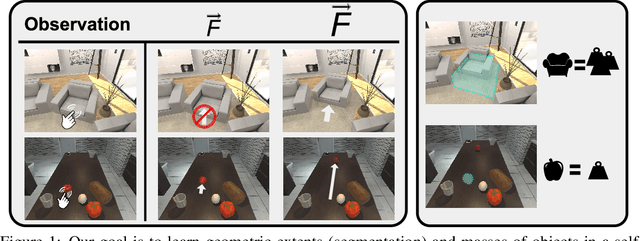
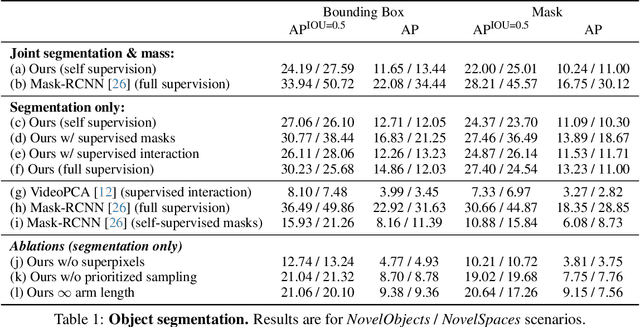
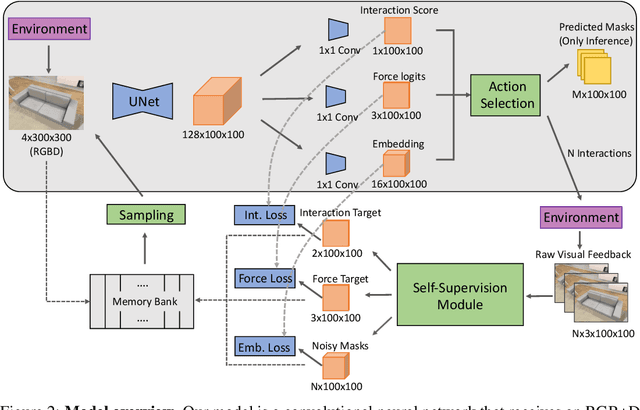

Much of the remarkable progress in computer vision has been focused around fully supervised learning mechanisms relying on highly curated datasets for a variety of tasks. In contrast, humans often learn about their world with little to no external supervision. Taking inspiration from infants learning from their environment through play and interaction, we present a computational framework to discover objects and learn their physical properties along this paradigm of Learning from Interaction. Our agent, when placed within the near photo-realistic and physics-enabled AI2-THOR environment, interacts with its world and learns about objects, their geometric extents and relative masses, without any external guidance. Our experiments reveal that this agent learns efficiently and effectively; not just for objects it has interacted with before, but also for novel instances from seen categories as well as novel object categories.
Yelp Food Identification via Image Feature Extraction and Classification
Feb 11, 2019
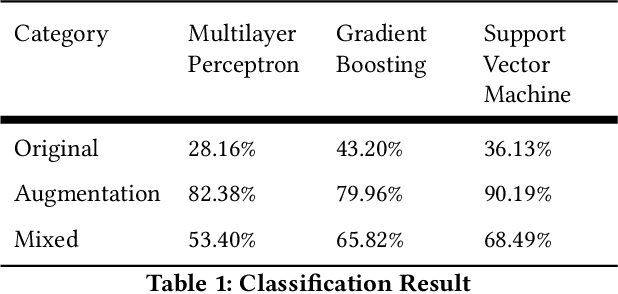
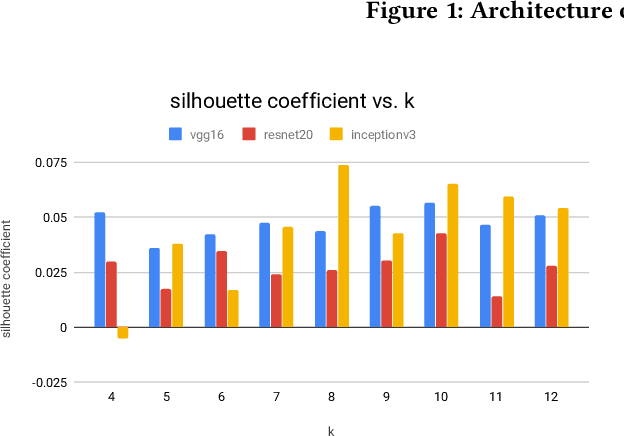

Yelp has been one of the most popular local service search engine in US since 2004. It is powered by crowd-sourced text reviews and photo reviews. Restaurant customers and business owners upload photo images to Yelp, including reviewing or advertising either food, drinks, or inside and outside decorations. It is obviously not so effective that labels for food photos rely on human editors, which is an issue should be addressed by innovative machine learning approaches. In this paper, we present a simple but effective approach which can identify up to ten kinds of food via raw photos from the challenge dataset. We use 1) image pre-processing techniques, including filtering and image augmentation, 2) feature extraction via convolutional neural networks (CNN), and 3) three ways of classification algorithms. Then, we illustrate the classification accuracy by tuning parameters for augmentations, CNN, and classification. Our experimental results show this simple but effective approach to identify up to 10 food types from images.
Robustness Evaluation of Stacked Generative Adversarial Networks using Metamorphic Testing
Mar 04, 2021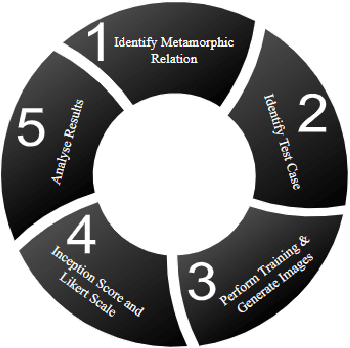



Synthesising photo-realistic images from natural language is one of the challenging problems in computer vision. Over the past decade, a number of approaches have been proposed, of which the improved Stacked Generative Adversarial Network (StackGAN-v2) has proven capable of generating high resolution images that reflect the details specified in the input text descriptions. In this paper, we aim to assess the robustness and fault-tolerance capability of the StackGAN-v2 model by introducing variations in the training data. However, due to the working principle of Generative Adversarial Network (GAN), it is difficult to predict the output of the model when the training data are modified. Hence, in this work, we adopt Metamorphic Testing technique to evaluate the robustness of the model with a variety of unexpected training dataset. As such, we first implement StackGAN-v2 algorithm and test the pre-trained model provided by the original authors to establish a ground truth for our experiments. We then identify a metamorphic relation, from which test cases are generated. Further, metamorphic relations were derived successively based on the observations of prior test results. Finally, we synthesise the results from our experiment of all the metamorphic relations and found that StackGAN-v2 algorithm is susceptible to input images with obtrusive objects, even if it overlaps with the main object minimally, which was not reported by the authors and users of StackGAN-v2 model. The proposed metamorphic relations can be applied to other text-to-image synthesis models to not only verify the robustness but also to help researchers understand and interpret the results made by the machine learning models.