 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Instrument Separation of Symbolic Music by Explicitly Guided Diffusion Model
Sep 05, 2022

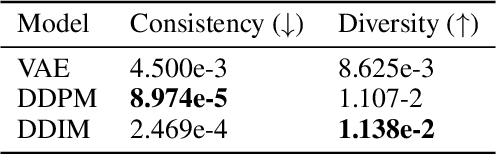
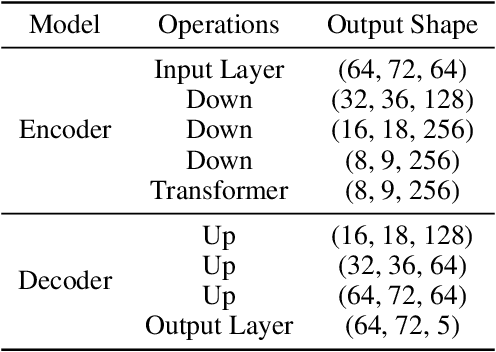
Similar to colorization in computer vision, instrument separation is to assign instrument labels (e.g. piano, guitar...) to notes from unlabeled mixtures which contain only performance information. To address the problem, we adopt diffusion models and explicitly guide them to preserve consistency between mixtures and music. The quantitative results show that our proposed model can generate high-fidelity samples for multitrack symbolic music with creativity.
Benchmarks and leaderboards for sound demixing tasks
May 12, 2023

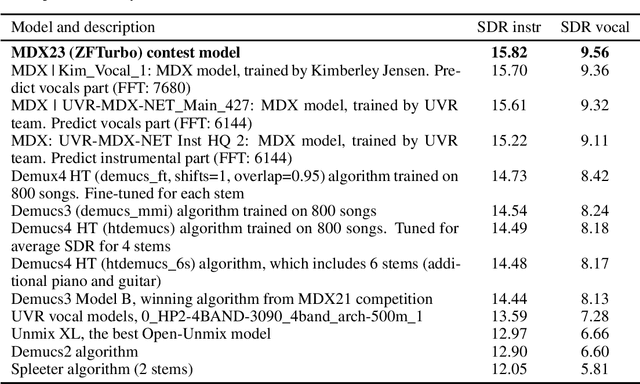
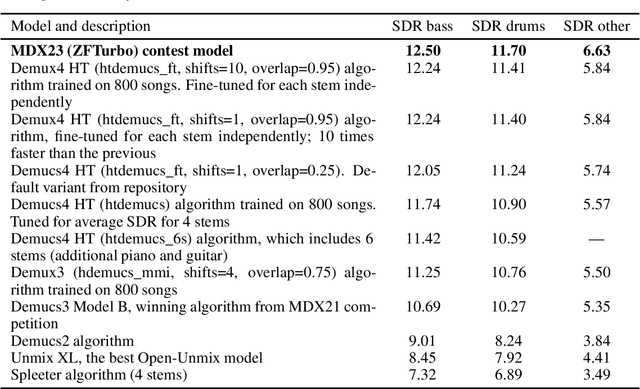
Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.
Low-Resource Music Genre Classification with Advanced Neural Model Reprogramming
Nov 02, 2022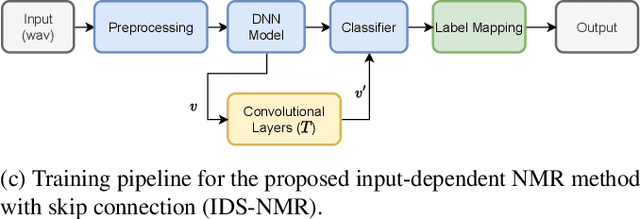

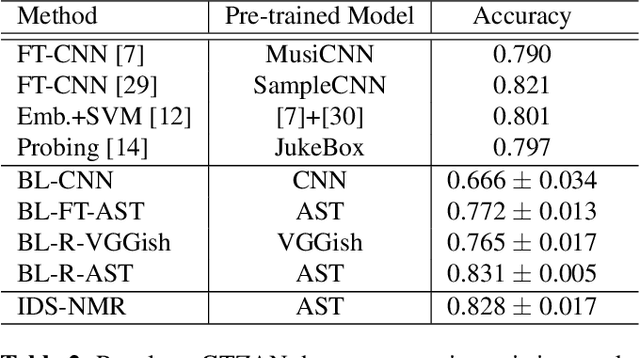
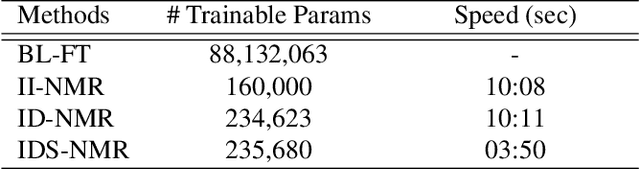
Transfer learning (TL) approaches have shown promising results when handling tasks with limited training data. However, considerable memory and computational resources are often required for fine-tuning pre-trained neural networks with target domain data. In this work, we introduce a novel method for leveraging pre-trained models for low-resource (music) classification based on the concept of Neural Model Reprogramming (NMR). NMR aims at re-purposing a pre-trained model from a source domain to a target domain by modifying the input of a frozen pre-trained model. In addition to the known, input-independent, reprogramming method, we propose an advanced reprogramming paradigm: Input-dependent NMR, to increase adaptability to complex input data such as musical audio. Experimental results suggest that a neural model pre-trained on large-scale datasets can successfully perform music genre classification by using this reprogramming method. The two proposed Input-dependent NMR TL methods outperform fine-tuning-based TL methods on a small genre classification dataset.
An interactive music infilling interface for pop music composition
Mar 23, 2022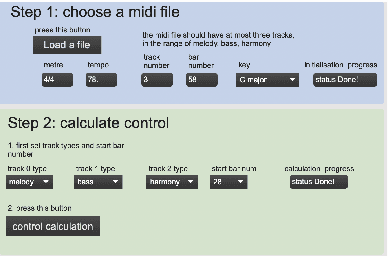
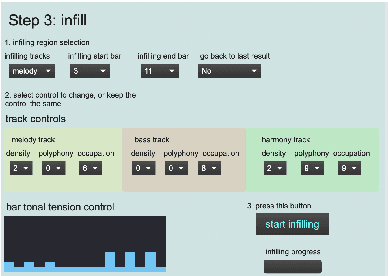
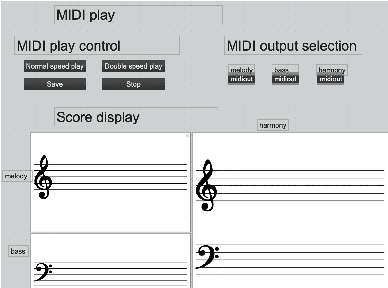
Artificial intelligence (AI) has been widely applied to music generation topics such as continuation, melody/harmony generation, genre transfer and music infilling application. Although with the burst interest to apply AI to music, there are still few interfaces for the musicians to take advantage of the latest progress of the AI technology. This makes those tools less valuable in practice and harder to find its advantage/drawbacks without utilizing them in the real scenario. This work builds a max patch for interactive music infilling application with different levels of control, including track density/polyphony/occupation rate and bar tonal tension control. The user can select the melody/bass/harmony track as the infilling content up to 16 bars. The infilling algorithm is based on the author's previous work, and the interface sends/receives messages to the AI system hosted in the cloud. This interface lowers the barrier of AI technology and can generate different variations of the selected content. Those results can give several alternatives to the musicians' composition, and the interactive process realizes the value of the AI infilling system.
DiffRoll: Diffusion-based Generative Music Transcription with Unsupervised Pretraining Capability
Oct 11, 2022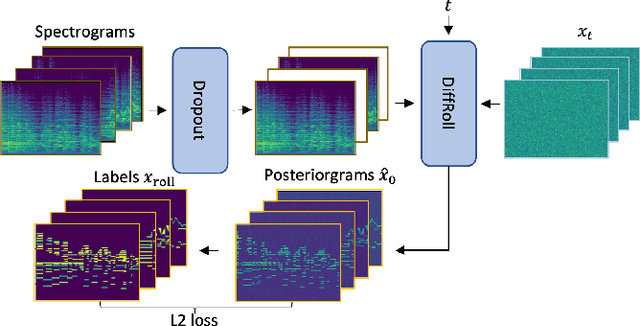
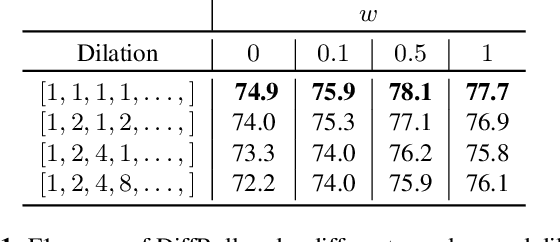
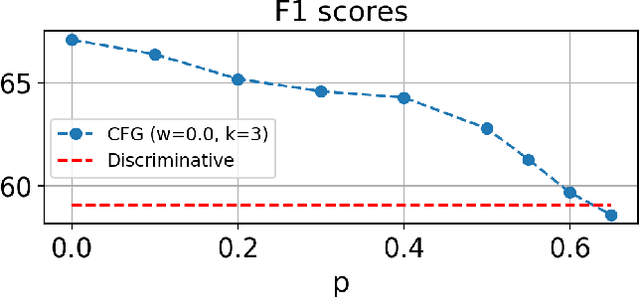

In this paper we propose a novel generative approach, DiffRoll, to tackle automatic music transcription (AMT). Instead of treating AMT as a discriminative task in which the model is trained to convert spectrograms into piano rolls, we think of it as a conditional generative task where we train our model to generate realistic looking piano rolls from pure Gaussian noise conditioned on spectrograms. This new AMT formulation enables DiffRoll to transcribe, generate and even inpaint music. Due to the classifier-free nature, DiffRoll is also able to be trained on unpaired datasets where only piano rolls are available. Our experiments show that DiffRoll outperforms its discriminative counterpart by 17.9 percentage points (ppt.) and our ablation studies also indicate that it outperforms similar existing methods by 3.70 ppt.
MF-PAM: Accurate Pitch Estimation through Periodicity Analysis and Multi-level Feature Fusion
Jun 16, 2023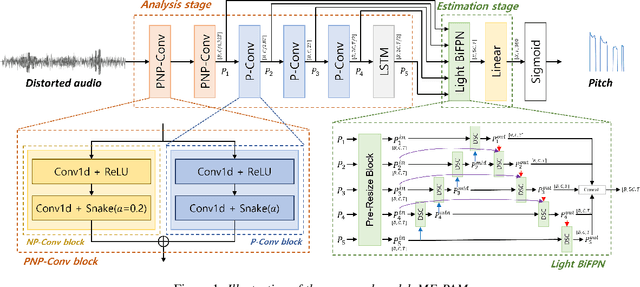
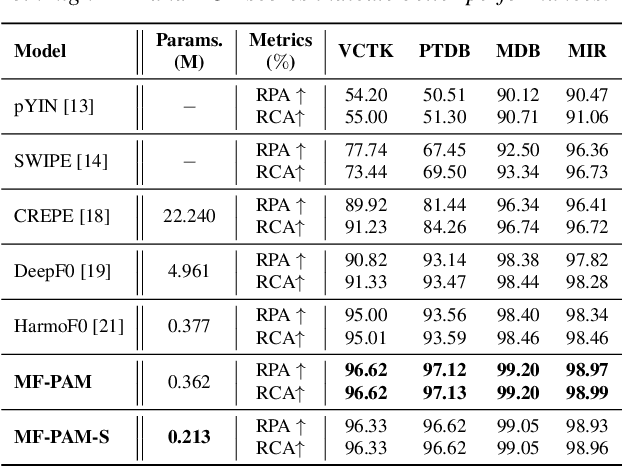
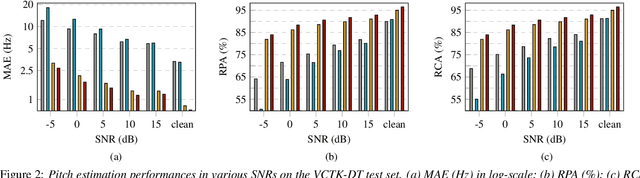
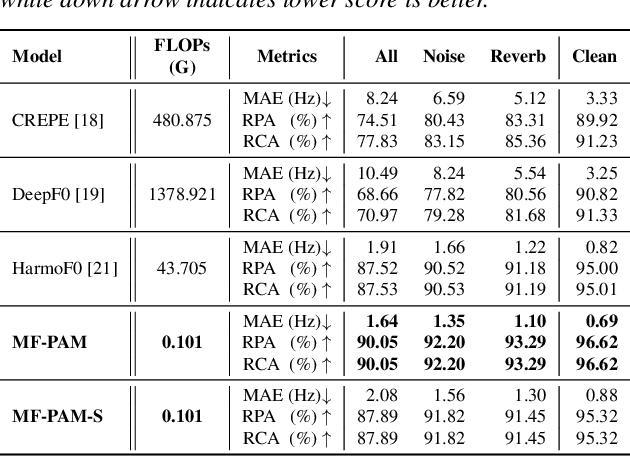
We introduce Multi-level feature Fusion-based Periodicity Analysis Model (MF-PAM), a novel deep learning-based pitch estimation model that accurately estimates pitch trajectory in noisy and reverberant acoustic environments. Our model leverages the periodic characteristics of audio signals and involves two key steps: extracting pitch periodicity using periodic non-periodic convolution (PNP-Conv) blocks and estimating pitch by aggregating multi-level features using a modified bi-directional feature pyramid network (BiFPN). We evaluate our model on speech and music datasets and achieve superior pitch estimation performance compared to state-of-the-art baselines while using fewer model parameters. Our model achieves 99.20 % accuracy in pitch estimation on a clean musical dataset. Overall, our proposed model provides a promising solution for accurate pitch estimation in challenging acoustic environments and has potential applications in audio signal processing.
Pipeline for recording datasets and running neural networks on the Bela embedded hardware platform
Jun 20, 2023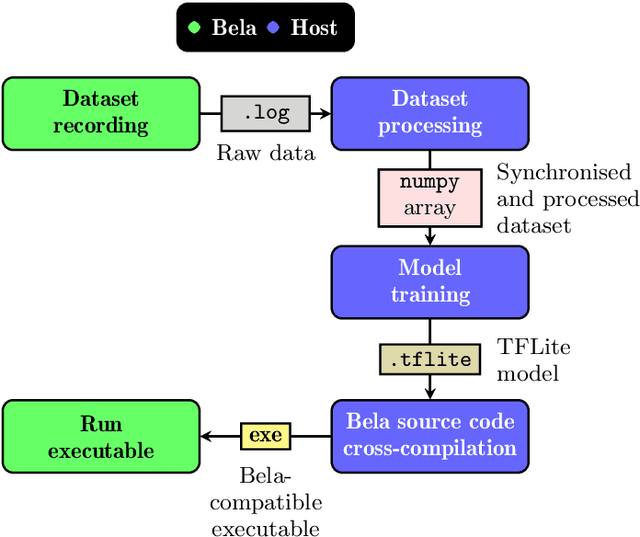
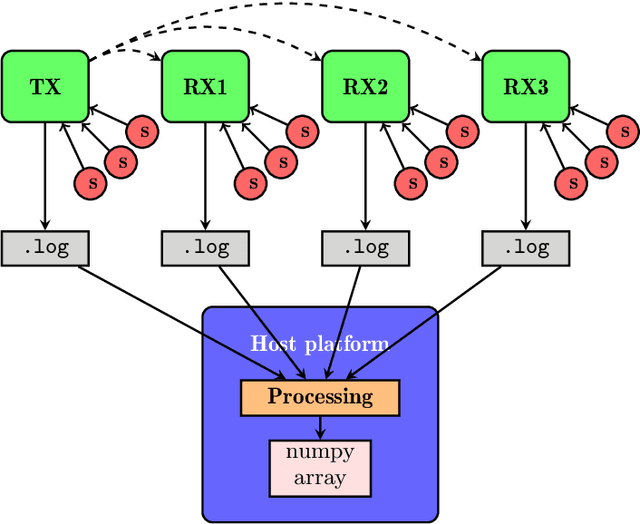
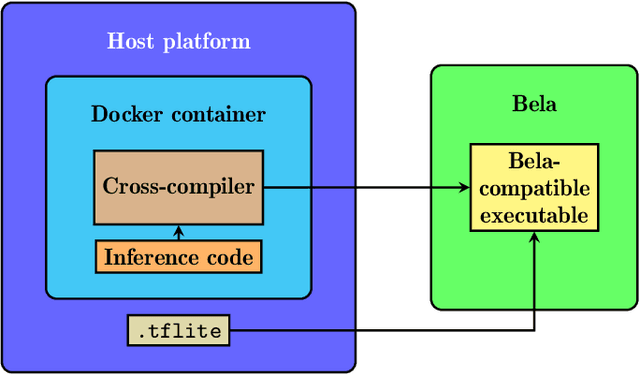
Deploying deep learning models on embedded devices is an arduous task: oftentimes, there exist no platform-specific instructions, and compilation times can be considerably large due to the limited computational resources available on-device. Moreover, many music-making applications demand real-time inference. Embedded hardware platforms for audio, such as Bela, offer an entry point for beginners into physical audio computing; however, the need for cross-compilation environments and low-level software development tools for deploying embedded deep learning models imposes high entry barriers on non-expert users. We present a pipeline for deploying neural networks in the Bela embedded hardware platform. In our pipeline, we include a tool to record a multichannel dataset of sensor signals. Additionally, we provide a dockerised cross-compilation environment for faster compilation. With this pipeline, we aim to provide a template for programmers and makers to prototype and experiment with neural networks for real-time embedded musical applications.
Conditional variational autoencoder to improve neural audio synthesis for polyphonic music sound
Nov 16, 2022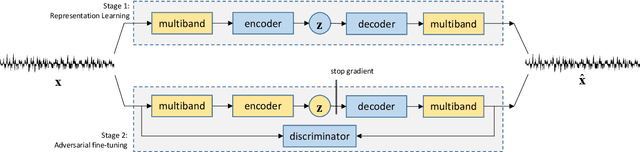
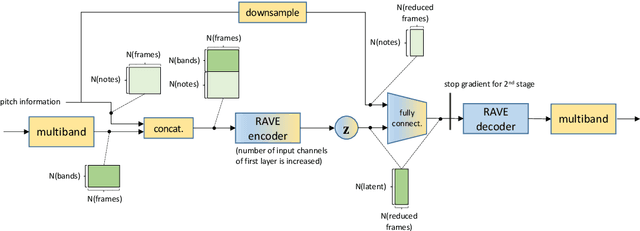
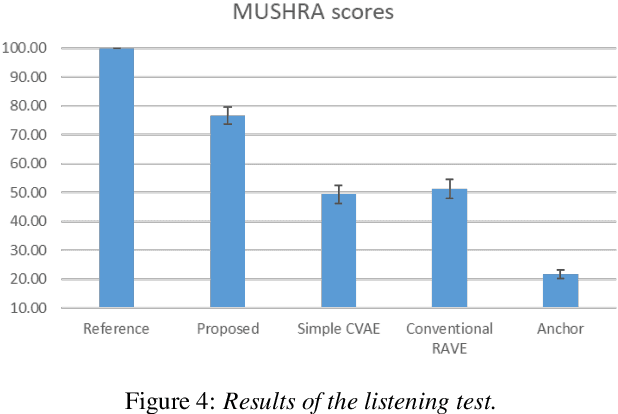
Deep generative models for audio synthesis have recently been significantly improved. However, the task of modeling raw-waveforms remains a difficult problem, especially for audio waveforms and music signals. Recently, the realtime audio variational autoencoder (RAVE) method was developed for high-quality audio waveform synthesis. The RAVE method is based on the variational autoencoder and utilizes the two-stage training strategy. Unfortunately, the RAVE model is limited in reproducing wide-pitch polyphonic music sound. Therefore, to enhance the reconstruction performance, we adopt the pitch activation data as an auxiliary information to the RAVE model. To handle the auxiliary information, we propose an enhanced RAVE model with a conditional variational autoencoder structure and an additional fully-connected layer. To evaluate the proposed structure, we conducted a listening experiment based on multiple stimulus tests with hidden references and an anchor (MUSHRA) with the MAESTRO. The obtained results indicate that the proposed model exhibits a more significant performance and stability improvement than the conventional RAVE model.
Self-Supervised Learning of Music-Dance Representation through Explicit-Implicit Rhythm Synchronization
Jul 07, 2022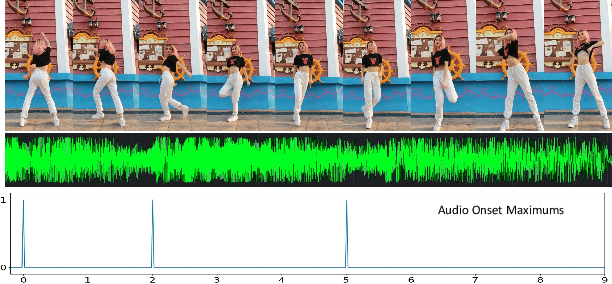
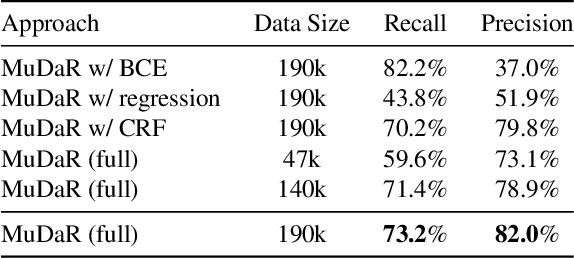
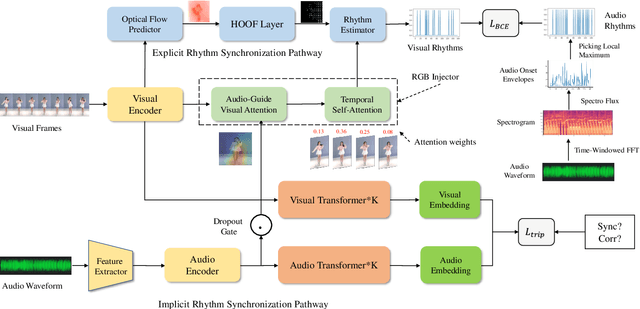
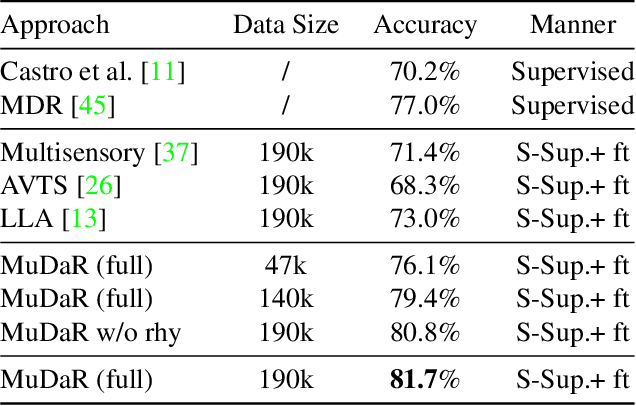
Although audio-visual representation has been proved to be applicable in many downstream tasks, the representation of dancing videos, which is more specific and always accompanied by music with complex auditory contents, remains challenging and uninvestigated. Considering the intrinsic alignment between the cadent movement of dancer and music rhythm, we introduce MuDaR, a novel Music-Dance Representation learning framework to perform the synchronization of music and dance rhythms both in explicit and implicit ways. Specifically, we derive the dance rhythms based on visual appearance and motion cues inspired by the music rhythm analysis. Then the visual rhythms are temporally aligned with the music counterparts, which are extracted by the amplitude of sound intensity. Meanwhile, we exploit the implicit coherence of rhythms implied in audio and visual streams by contrastive learning. The model learns the joint embedding by predicting the temporal consistency between audio-visual pairs. The music-dance representation, together with the capability of detecting audio and visual rhythms, can further be applied to three downstream tasks: (a) dance classification, (b) music-dance retrieval, and (c) music-dance retargeting. Extensive experiments demonstrate that our proposed framework outperforms other self-supervised methods by a large margin.
Bi-Sampling Approach to Classify Music Mood leveraging Raga-Rasa Association in Indian Classical Music
Mar 13, 2022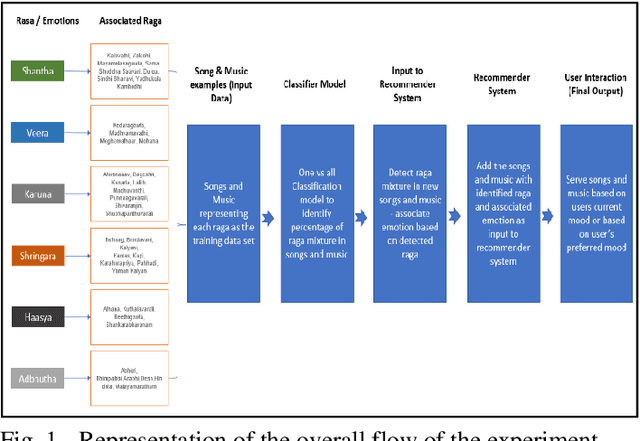

The impact of Music on the mood or emotion of the listener is a well-researched area in human psychology and behavioral science. In Indian classical music, ragas are the melodic structure that defines the various styles and forms of the music. Each raga has been found to evoke a specific emotion in the listener. With the advent of advanced capabilities of audio signal processing and the application of machine learning, the demand for intelligent music classifiers and recommenders has received increased attention, especially in the 'Music as a service' cloud applications. This paper explores a novel framework to leverage the raga-rasa association in Indian classical Music to build an intelligent classifier and its application in music recommendation system based on user's current mood and the mood they aspire to be in.